Классификация опухолевых клеток с использованием моделей машинного обучения в среде Альт Линукc (Игорь Воронин, OSEDUCONF-2023)
Материал из 0x1.tv
- Докладчик
- Игорь Воронин


Спектроскопия комбинационного рассеяния (также известная как рамановская) — метод, который успешно используется в химии для получения структурных «отпечатков пальцев».
Колебательная спектроскопия дает ключевую информацию о структуре молекул. В результате полученных спектрограмм, можно анализировать и делать выводы о состоянии биологической ткани — методами машинного обучения.
Для успешной борьбы с раковой опухолью очень важно обнаружить все раковые клетки на ранних этапах, даже те, которые находятся вне очевидных границ опухоли и являются труднодиагностируемыми. Цель диагностического поиска — своевременно обнаружить и выбрать тот способ лечения, который бы позволил удалить 100% опасных клеток и минимизировать риск рецидива заболевания. В связи с этим большую важность имеют разнообразные методики классификации тканей. В частности, можно проводить биопсию исследуемой области, получать небольшой образец ткани, а потом анализировать его спектрограмму.
Содержание
Видео
Презентация









Thesis
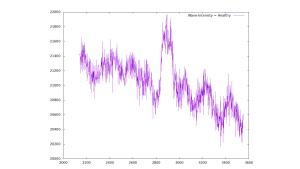
Исходные данные В данной работе была рассмотрена задача бинарной классификации с классами “больные” и “здоровые” образцы биологических тканей. Для обучения и тестирования виртуальной модели были использованы 888 спектрограммы, из которых 456 принадлежат классу “больные” и 432 принадлежат классу “здоровые”. Работа выполнялась на сервер astera.laser.ru (ИПЛИТ РАН, Шатура) в операционной среде ALT Server 10.1 (FalcoRusticolus), Python 3.9.6, Docker version 20.10.11, ядро Linux astera 5.10.131-std-def-alt1
Визуализация типовой спектрограммы:

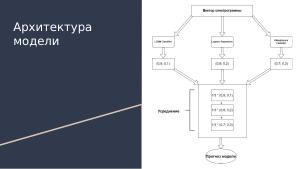
Архитектура модели и результаты:

В качестве базовых моделей использовались: градиентный бустинг, логистическая регрессия и KNeighbors классификаторы, реализованные в библиотеках LightGBM и SKLearn. После того как эти 3 базовых классификатора делают свои прогнозы, прогнозы усредняются. Благодаря тому, что выбраны классификаторы с разными принципами работы, корреляция между их прогнозами не слишком высока, что позволяет получать ощутимое улучшение точности после усреднения.
Обучение: train датасет используется для обучения 3 базовых классификаторов независимо друг от друга.
Валидация: Используется кросс-валидация с n_folds = 5, на каждом шаге модель обучается на датасета и проверяется на оставшейся части. Итоговая точность вычисляется как среднее арифметическое от точности каждого шага.
Результаты: На кросс-валидации удалось получить точность 97.6%. Использование популярных фреймворков (LightGBM, SKLearn и NumPy) позволяет создавать приложение для классификации для любой операционной системы.
- Marco Riva et al, Glioma biopsies classification using raman spectroscopy and machine learning models o fresh tissue samples, [1]
- Jason Brownlee, Stacking ensemble machine learning with Python, [2]
- Сервер для дистанционной обработки спектрограмм [3].
!.jpg)