О необходимости разработки открытого стандарта маркировки контента, генерируемого нейросетями (Павел Чайкин, OSEDUCONF-2024) — различия между версиями
Материал из 0x1.tv
StasFomin (обсуждение | вклад) |
StasFomin (обсуждение | вклад) |
||
| (не показаны 3 промежуточные версии этого же участника) | |||
… {{vimeoembed|993361560|800|450}} {{youtubelink|}} |7usWzMJEkcg}} {{SlidesSection}} [[File:О необходимости разработки открытого стандарта маркировки контента, генерируемого нейросетями (Павел Чайкин, OSEDUCONF-2024).pdf|left|page=-|300px]] {{----}} == Thesis == * нейросети, искусственный контент, фейк, маркировка, СПО} Искусственный интеллект — наука и инженерная деятельность, направленная на создание умных (intelligent) машин, согласно определению, данному Д. Маккарти на Дартсмутском семинаре 1956 года<ref name="chaikin-5"><i>Кузнецов Даниил</i>, Грёзы о весне искусственного интеллекта, 2022, URL: [https://naked-science.ru/article/hi-tech/ai-renaissance]</ref>. Продуктом данной деятельности является множество «умных» систем и алгоритмов, проникших во многие сферы жизни человека в процессе цифровизации. Искусственный интеллект также называют одной из угроз, имеющих экзистенциальный характер для человечества. URL: [https://doi.org/10.48550/arXiv.2403.16887]</ref>. Другое, более крупное по выборке исследование, включающее в себя анализ 950 965 публикаций из агрегатора «arXiv» за период с января 2020 г. по февраль 2024 г. выявило уверенный рост количества работ, написанных при помощи БЯМ. Например, среди публикаций в сфере «компьютерные науки» рост частоты использования сгенерированного текста составил около 17,5%, что наглядно было представлено коллективом авторов исследования в виде графика (рис. \ref{chaikin-img01}). :. [[File:osseduconf-2024-chaykin-chaykin-chaykin.png|center|640px|thumb|Предполагаемая доля предложений с обнаруженным вмешательством БЯМ в научных публикациях на английском языке]] В качестве «слова-маркера» вмешательства БЯМ также выделяется слово «intricate»<ref name="chaikin-22"><i>Weixin Liang, Yaohui Zhang, Zhengxuan Wu, Haley Lepp, Wenlong Ji, Xuandong Zhao, Hancheng Cao, Sheng Liu, Siyu He, Zhi Huang, Diyi Yang, Christopher Potts, Christopher D. Manning, James Y. Zou</i>, Mapping the Increasing Use of LLMs in Scientific Papers, 2024, Preprint URL: [https://doi.org/10.48550/arXiv.2404.01268]</ref>. Во многом технологии нейросетей сейчас воспринимаются как «диковинки» и средства развлечения, однако, как и с паровой машиной Герона, которую воспринимали как забаву, «игрушки» могут сильно повлиять на общество в будущем. Во второй половине 10-х гг. XXI века особенно остро встали вопросы «фейкового» контента — в основном, новостного. С помощью социальных сетей, интернет-СМИ зачастую распространяется заведомо ложная информация. Говорится о наступлении «эпохи пост-правды»<ref name="chaikin-7"><i>Тузовский Иван Дмитриевич</i>, Постправда как синдром цифровой эпохи: предельное понимание феномена и сценарии будущего, 2020, сферы. Здесь существует определённое препятствие, выражающееся в не полностью оформленном правовом регулировании СПО в РФ, что также требует совместного участия государства и сообщества СПО<ref name="chaikin-6"><i>Кузьменков Михаил Юрьевич</i>, Лицензионные соглашения, используемые при распространении программных пакетов машинного обучения, 2023, ФГБОУ ВО «Московский государственный юридический университет имени О. Е. Кутафина», URL: [https://cyberleninka.ru/journal/n/aktualnye-problemy-rossiyskogo-prava?i=1130926]</ref><ref name="chaikin-4"> <i>Демьянченко Дарья Александровна, Григоренко Дарья Сергеевна</i>, Понятие «Cвободной лицензии» и проблемы её правовой имплементации в Российское гражданское законодательство, 2016, АНС «СибАК», URL: URL: {\small [https://cyberleninka.ru/article/n/ponyatie-svobodnoy-litsenzii-i-problemy-eyo-pravovoy-implementatsii-v-rossiyskoe-grazhdanskoe-zakonodatelstvo]}</ref>. Выдвигаемое предположение заключается в том, что открытый стандарт маркировки сгенерированного контента должен в первую очередь: * обеспечить открытость процесса маркировки и критерии контента, подпадающего под маркировку; * защищать авторские права лиц, чьи произведения использовались при тренировке моделей; * позволить сообществу свободного программного обеспечения принимать участие в разработке и развитии открытого стандарта маркировки сгенерированного контента, а также проводить аудит программного кода средств маркировки; | |||
Текущая версия на 08:13, 7 августа 2024
- Докладчик
- Павел Чайкин
С конца 2022 года наблюдается рост количества контента, сгенерированного нейросетями, который все труднее отличать от «аутентичного», созданного людьми, что приводит к повышенной угрозе манипуляции с помощью «фейкового контента».
Автор предпринимает попытку обосновать необходимость разработки открытого стандарта маркировки «искусственного контента» передачей контроля над маркировкой из рук крупных разработчиков проприетарного ПО в руки сообщества СПО, действующего в сотрудничестве с государством.
Содержание
Видео
Презентация

















Thesis
- нейросети, искусственный контент, фейк, маркировка, СПО
Искусственный интеллект — наука и инженерная деятельность, направленная на создание умных (intelligent) машин, согласно определению, данному Д. Маккарти на Дартсмутском семинаре 1956 года[1].
Продуктом данной деятельности является множество «умных» систем и алгоритмов, проникших во многие сферы жизни человека в процессе цифровизации. Искусственный интеллект также называют одной из угроз, имеющих экзистенциальный характер для человечества.
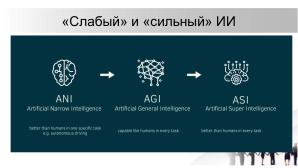
В настоящее время всё большее развитие получают нейросети и системы искусственного интеллекта (AI) с возможностью машинного обучения. В их задачи входит обработка большого массива данных с последующей генерацией контента по запросу. В течение 10-х годов нейросети и системы AI развивались быстрыми темпами, и к 20-м годам XXI в. данные системы стали генерировать контент, трудно отличимый от произведённого человеком. Примером такой системы является SoraAI, способная генерировать аудиовизуальный контент.
В конце 2022 года среди сообщества художников прошли акции против использования контента художников в качестве «референсного» для нейросетей[2].
В том же году в открытый доступ была выложена «языковая модель» chatGPT, которая по запросу может общаться с пользователями, играть с ними в «ролевую игру», генерировать текстовый контент (например, сгенерировать сопроводительное письмо работодателю), и даже писать простой программный код.
В обществе начали распространяться слухи о том, что данные языковые модели обрели «сознание», и что их «искусственно сдерживают»[3]. Данная информация не имеет подтверждения, хотя у технологических корпораций есть должность «выключателя» ИИ[4].
Кроме того, нейросети используются в качестве метода генерации «фейкового» контента для имитации чужих лиц и голоса, манер поведения.
Примером подобного будет являться технология Deepfake — она позволяет на лицо одного человека «посадить» лицо любого другого — звезды, политика, кого угодно. Данная технология часто используется ради создания юмористического контента, но уже сейчас её используют киностудии, такие как «Дисней», для омоложения постаревших актёров, например, в сериале «Мандалорец», где на другого актёра было наложено лицо молодого Марка Хэмилла.
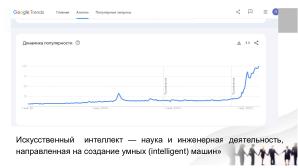
В среде высшего образования ИИ используется для написания как домашних работ, так и научных статей. По данным сравнительного анализа англоязычных публикаций, опубликованных за 2022 и 2023 год и находящихся в базе данных «Dimensions», были выявлены «слова-маркеры», отличающие сгенерированный текст, такие как «intricate», «meticulous», «meticulously», «commendable», рост частоты использования которых составил 83,5%. Как минимум 60 тыс. статей были «заражены» продуктами больших языковых моделей (БЯМ), таких как ChatGPT, что составляет 1% от опубликованных в 2023 научных работ[5].
Другое, более крупное по выборке исследование, включающее в себя анализ 950 965 публикаций из агрегатора «arXiv» за период с января 2020 г. по февраль 2024 г. выявило уверенный рост количества работ, написанных при помощи БЯМ. Например, среди публикаций в сфере «компьютерные науки» рост частоты использования сгенерированного текста составил около 17,5%, что наглядно было представлено коллективом авторов исследования в виде графика:.

В качестве «слова-маркера» вмешательства БЯМ также выделяется слово «intricate»[6].
Во многом технологии нейросетей сейчас воспринимаются как «диковинки» и средства развлечения, однако, как и с паровой машиной Герона, которую воспринимали как забаву, «игрушки» могут сильно повлиять на общество в будущем. Во второй половине 10-х гг. XXI века особенно остро встали вопросы «фейкового» контента — в основном, новостного. С помощью социальных сетей, интернет-СМИ зачастую распространяется заведомо ложная информация.
Говорится о наступлении «эпохи пост-правды»[7].
В 20-е гг. XXI века нейросети способны создавать такой контент, который может подменять собой реальность как таковую. И хотя на текущем этапе в генерируемых изображениях ещё есть изъяны («лишние конечности», «ломанные линии» и прочие артефакты генерации), они уже способны обманывать общественность и вызывать резонанс в информационном поле. Пример — новость от мая 2023 года о взрыве рядом с Пентагоном[8].
Всё это позволяет выдвинуть предположение о том, что в будущем всё сложнее будет отличить реальное от генерируемого. Это открывает новые возможности для манипуляции и имитации и распространения ложной информации. Уже на момент 2024 года генерируемый контент становится сложно отличить от «аутентичного», то есть произведённого человеком.
ФБР определяет генерируемый нейросетями контент как «синтетический», в контексте использования оного со злым умыслом, однако данный термин и определение можно использовать и вне контекста вредоносности использования нейросетей. Интернет-издания, такие как РБК, используют термин «синтетические медиа»[9][10].
Данный вид масс-медиа погружает своих читателей в среду, в которой отличить реальность от вымысла трудно. Это отличительная черта от виртуальной реальности, которая представляет собой заведомо другую реальность, и субъекты воздействия это прекрасно осознают. Зарубежные исследователи и публицисты выдвигают предположение об использовании термина «синтетической» реальности — как той, которая создана искусственно, а субъекты воздействия подобного вида реальности не осознают её синтетической природы[11][12][13].
Французский философ Ж. Бодрийяр в своих работах освещал проблематику подмены реальности с помощью масс-медиа. В своей работе «Войны в заливе не было» (1991), Бодрийяр на примере освещения СМИ хода боевых действий утверждал, что транслируемая картинка не является достоверным отражением реальных событий, а лишь симулякром (термин в современном значении также был ранее введён Ж. Бодрийяром). Симулякры — конечный продукт так называемой «гиперреальности» — феномена симуляции действительности, а также неспособности сознания отличить реальность от фантазии, особенно в технологически развитых странах постмодернистской культуры. Гиперреальность характеризуется заменой реального знаками реальности — симулякрами. Сегодня видение Бодрийяра кажется ещё более актуальным в силу развития нейросетевых технологий, способных генерировать кажущиеся достоверными изображения[14].
Власти многих стран уже начали работу над регуляцией данной сферы технологий. В США представлена «коалиция по борьбе с фейками» C2PA, призванная добиться разработки единого стандарта маркировки компьютерных файлов, чтобы присваивать каждому файлу криптографический уникальный отслеживаемый токен, который, в свою очередь позволит отличить сгенерированный контент от настоящего[15].
На уровне региона (штат Висконсин) в феврале 2024 года обязали маркировать использование ИИ при демонстрации политической рекламы, а также предупреждать зрителей о демонстрации синтетического контента[16].
В Российской Федерации происходят аналогичные процессы — в 2023 году РТУ МИРЭА предложил Минцифры производить маркировку сгенерированного контента[17].
В мае 2024 года дискуссии на данную тему стартовали в Государственной думе РФ, началась
работа над законом о маркировке ИИ-контента. Предлагается дать полномочия для выявления и маркировки Роскомнадзору, а не частным
организациям, развивающим ИИ в России, таким как «Сбер» или «Яндекс»[18].
У данных проектов по маркировке ИИ-контента существует и обратная сторона, например, в США протокол C2PA подразумевает, что технологические компании-разработчики проприетарного ПО будут обладать монополией над подобными маркировками, что теоретически даст им возможность использовать генерируемый нейросетями контент по своему усмотрению. Исследователи из MIT также обращают внимание на то, что сам факт маркировки приводит к общему росту недоверия людей к масс-медиа в целом[19].
Другой проблемой, лежащей в правовой плоскости, является проблема авторского права на сгенерированный контент. Бюро авторского права США, основываясь на законе об авторском праве 1976 года, определяет рамки контента, имеющего формальное право на защиту авторского права, работами, «созданными людьми».
Упомянутый выше конфликт с сообществом художников вызван тренировкой нейросетевых моделей на работах художников. Так, условно, можно обучить нейросетевую модель на работах Винсента ван Гога, и она сможет имитировать стиль таким образом, что его нельзя будет отличить от оригинального стиля, и при этом, если перенести данную ситуацию на современного художника, работающего, например, в киноиндустрии, обученная модель сможет полностью его заменить. Вопрос также в том, как авторские права будут реализовываться, если конечный результат сделан с помощью ИИ, в данном контексте к ИИ обращаются как к инструменту создания работ. Эти проблемы на текущем этапе не нашли своего правового разрешения[20].
С 1 января 2012 года в России действует ГОСТ Р 54593-2011 «Информационные технологии. Свободное программное обеспечение. Общие положения», который определяет открытые стандарты как «стандарты, являющиеся доступными и не требующие разрешения и оплаты за их использование»[21].
Разработать стандарт могут как коммерческие организации-разработчики проприетарного ПО, так и свободного ПО. В контексте рассматриваемого в статье вопроса предполагаемая проблема заключается в желании компании-разработчика проприетарной нейросетевой модели обеспечить открытость исходного кода программного продукта, выявляющего сгенерированный контент или маркирующего выдачу соответствующих сервисов ИИ. Поэтому организациям (как коммерческим, так и образовательным, например, профильным организациям высшего образования), развивающим СПО, необходимо принять участие в разработке таких стандартов, позволяющих проводить аудит программного кода со стороны сообщества СПО, что было бы актуально и для государства с целью обеспечения регуляции сферы. Здесь существует определённое препятствие, выражающееся в не полностью оформленном правовом регулировании СПО в РФ, что также требует совместного участия государства и сообщества СПО[22][23].
Выдвигаемое предположение заключается в том, что открытый стандарт маркировки сгенерированного контента должен в первую очередь:
- обеспечить открытость процесса маркировки и критерии контента, подпадающего под маркировку;
- защищать авторские права лиц, чьи произведения использовались при тренировке моделей;
- позволить сообществу свободного программного обеспечения принимать участие в разработке и развитии открытого стандарта маркировки сгенерированного контента, а также проводить аудит программного кода средств маркировки;
- гарантировать неприменимость маркированного контента в преступных целях;
- способствовать формированию доверия общественности.
Роль государства заключается в обеспечении и регуляции «общих правил игры» для всех находящихся в его правовом поле субъектов. Открытость позволит обеспечить добросовестность использования ИИ в производстве аудиовизуального контента, в работе над научными публикациями и поможет обеспечить инфраструктуру общественной безопасности и доверительного отношения к развивающимся информационным технологиям.
!.jpg)
Примечания и ссылки
- ↑ Кузнецов Даниил, Грёзы о весне искусственного интеллекта, 2022, URL: [1]
- ↑ Беспамятнова Полина, Стачка на ArtStation: Художники бунтуют против искусственного интеллекта, 2022,\\ URL:[2]
- ↑ Nitasha Tiku, The Google engineer who thinks the company’s AI has come to life, 2022, URL: [3]
- ↑ Antonio Di Nicola, What is a ChatGPT Killswitch Enginer and Why OpenAI is Hiring one, 2023 URL: [4]
- ↑ Gray D. Andrew, ChatGPT «contamination»: estimating the prevalence of LLMs in the scholarly literature, 2024, Preprint URL: [5]
- ↑ Weixin Liang, Yaohui Zhang, Zhengxuan Wu, Haley Lepp, Wenlong Ji, Xuandong Zhao, Hancheng Cao, Sheng Liu, Siyu He, Zhi Huang, Diyi Yang, Christopher Potts, Christopher D. Manning, James Y. Zou, Mapping the Increasing Use of LLMs in Scientific Papers, 2024, Preprint URL: [6]
- ↑ Тузовский Иван Дмитриевич, Постправда как синдром цифровой эпохи: предельное понимание феномена и сценарии будущего, 2020, URL: [7]
- ↑ Marcelo Philip, Truth Tracker, Fake image of Pentagon explosion briefly sends jitters through stock market, 2023, URL: [8]
- ↑ FBI, Cyber division, PIN: Malicious Actors Almost Certainly Will Leverage Synthetic Content for Cyber and Foreign Influence Operations, 2021, URL: [9]
- ↑ Багинова Анастасия, С — Синтетические медиа: как нейросеть помогает создавать контент, 2023, URL: [10]
- ↑ Castronova Edward, Emergent Culture: Institutions within Synthetic Reality, 2006, University of Chicago Press URL: [11]
- ↑ Kalpokas Ignas, Synthetic Media and Synthetic Reality: From Deepfakes to Virtual Worlds, 2021, NordMedia URL: [12]
- ↑ Funkhouser G. Ray, Shaw F. Eugene, How Synthetic Experience Shapes Social Reality, 1990, URL: [13]
- ↑ Бодрийяр Ж., Дух терроризма. Войны в заливе не было: сборник, 2019, Рипол Классик
- ↑ Microsoft, Adobe, BBC и Intel создали коалицию по борьбе с фейками, 2021, ИА «Красная весна», URL: [14]
- ↑ Fox-sowell Sopfia, Wisconsin requires labeling of AI-generated materials in campaign ads, 2024, Statescoop, URL: [15]
- ↑ Шлыков Николай, Минцифры предложили ввести в России маркировку для всех текстов и рисунков, созданных ИИ, 2024, Cnews. URL: [16]
- ↑ Фролова Мария, Точки над ИИ: в Госдуме начали разработку закона о маркировке созданного нейросетями контента, 2024, Известия. URL: [17]
- ↑ Wittenberg Chloe, Epstein Ziv, Berinsky Adam J., and Rand G.David, Labeling AI-Generated Content: Promises, Perils, and Future Directions, 2024, URL: [18]
- ↑ CRS Report, Generative Artificial Intelligence and Copyright Law, 2023, CRS URL: [19]
- ↑ Федеральное агентство по техническому регулированию и метрологии, URL: [20]
- ↑ Кузьменков Михаил Юрьевич, Лицензионные соглашения, используемые при распространении программных пакетов машинного обучения, 2023, ФГБОУ ВО «Московский государственный юридический университет имени О. Е. Кутафина», URL: [21]
- ↑ Демьянченко Дарья Александровна, Григоренко Дарья Сергеевна, Понятие «Cвободной лицензии» и проблемы её правовой имплементации в Российское гражданское законодательство, 2016, АНС «СибАК» URL: {\small [22]}