Система HJudge или как автоматизировать проверку заданий при изучении работы с большими данными (OSEDUCONF-2017)
Материал из 0x1.tv
Содержание
Аннотация
- Докладчики


Тестирование приложения для обработки больших массивов данных в большинстве случаев сводится к запуску приложения на небольших тестовых выборках. Однако если мы имеем дело с большими данными, то даже тестовая выборка может занимать несколько гигабайт. Соответственно, результат работы приложения тоже может быть большим. Проверка такого результата на корректность становится трудоёмким процессом. Тестирование Hadoop-приложений включает проверку (1) корректности сборки приложения, (2) успешности его запуска на Hadoop-кластере, (3) результата работы. В рамках курсов обработки больших данных обычно затрагивается несколько сервисов экосистемы Hadoop, что увеличивает сложность создания единого интерфейса для тестирования таких приложений. В применении к высшей школе, при тестировании приложений нужно учесть и то, что разные ошибки в коде по-разному влияют на результат. Иными словами, в целях более справедливого оценивания работ студентов нужно иметь богатый набор тестов для идентификации ошибок программы. Существуют различные программные продукты, решающие одну или несколько из описанных проблем. Однако не найдено системы, которая бы решала все эти проблемы одновременно.
Это создало предпосылки для разработки своего продукта — системы «HJudge», о которой и пойдёт речь в докладе.
Видео
Слайды































Тезисы
Вступление
В рамках любого образовательного технического курса незаменимую роль играют практические задания. Они дают возможность студентам попрактиковаться в пройденном материале, а преподавателям — оценить их навыки. Однако проверка заданий является довольно рутинной работой и при большом количестве участников курса требует серьёзных затрат времени. Отсюда вытекает необходимость автоматизации этого процесса.
Курс ХОБОД
Хранение и обработка больших объёмов данных (или BigData) — это курс, который читается для студентов 1-го года магистратуры ФИВТ МФТИ с 2015 г. Курс призван дать начальные знания в области хранения и обработки данных, для работы с которыми недостаточно одной машины[1]. Практическую часть курса составляют программы, разрабатываемые с использованием сервисов экосистемы Hadoop (Hadoop, Hive, Spark, HBase). Чтобы исключить возможность решения заданий обычными средствами, студентам выдаются большие датасеты (несколько десятков гигабайт).
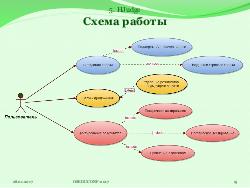
Процесс проверки заданий
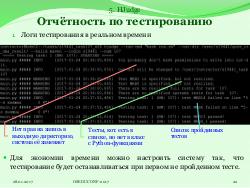
Студент оформляет пост в системе Piazza [2] по определённым правилам и выкладывает свою программу на Hadoop-кластер. Далее преподаватель собирает программу и запускает её. Во время работы программы с помощью интерфейса JobTracker[3] наблюдается состояние её выполнения. После отработки приложения на кластере проверяются его результаты. Последняя стадия проверки — это Code review, в рамках которого проверяется грамотность написанного кода. Такой метод проверки задач имеет свои преимущества при небольшом количестве заданий.
Автоматизация проверки заданий
Процесс проверки заданий, описанный выше, можно свести к тестированию Hadoop-приложений. Тестирование включает проверку:
- корректности сборки приложения,
- успешности его работы на Hadoop-кластере,
- результата работы.
Существует много библиотек, способных решить отдельно каждую из проблем. Например, этап (1) можно провести с помощью Maven[4]. Этап (2) можно провести с помощью инструментов, входящих в поставку Hadoop [5]. Проверить результат работы приложения теоретически можно и с помощью утилиты diff. Но из-за большого размера (а иногда и количества) выходных файлов это практически невозможно. Кроме того, в рамках курсов обработки больших данных обычно затрагивается несколько сервисов экосистемы Hadoop, что увеличивает сложность создания единого интерфейса для тестирования приложений.
Единой системы, которая бы покрыла все описанные выше проблемы, на данный момент не существует. Это послужило толчком к разработке HJudge.
Система HJudge и её применение при проверке заданий
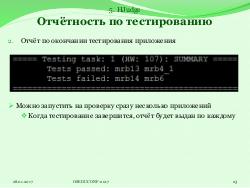
Система HJudge — это программа, написанная на Python 2.7 и используемая для тестирования приложений, разработанных на Hadoop, Hive, Spark, HBase. Входными данными системы являются параметры запуска одного или нескольких тестируемых заданий. Они могут вводиться в виде аргументов командной строки либо с помощью конфигурационного файла. В качестве результата система выдаёт отчёт о проведённом тестировании.
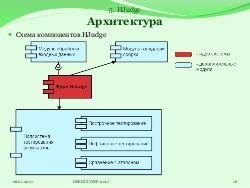
В первом приближении архитектура HJudge состоит из основной части и расширяемого набора встраиваемых тестов. Основная часть состоит из ядра и нескольких модулей, каждый из которых отвечает за определённый этап работы приложения:
- модуль обработки входных данных;
- модуль валидации сборки;
- модуль проверки корректности запуска.
Тесты для данных модулей уже разработаны и поставляются вместе с системой. В большинстве случаев их достаточно, однако есть возможность встраивать свои.
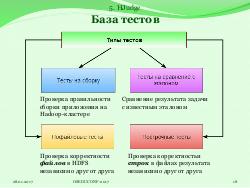
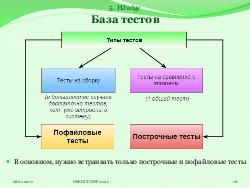
Также существует отдельная компонента, отвечающая за проверку результата работы приложения. В эту компоненту можно встраивать тесты трёх типов:
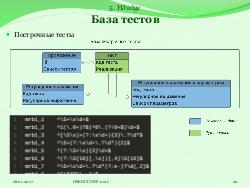
- Построчные тесты — проверяют корректность отдельно взятой строки вне зависимости от других;
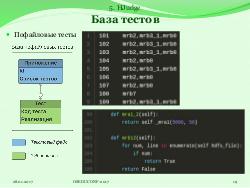
- Пофайловые тесты — проверяют корректность одного файла;
- Тесты на сравнение с эталоном — сравнивают фрагменты данных результата с фрагментами данных, сгенерированными эталонным приложением.
Тест представляет собой обычную Python-функцию. Для встраивания теста в систему достаточно добавить эту функцию в класс, соответствующий типу теста. По умолчанию система настроена так, что тестирование приложения завершается, если не пройден хотя бы один тест. Это экономит время и ресурсы тестирования.
Ещё одной замечательной особенностью HJudge, облегчающей проверку заданий, является возможность тестирования сразу нескольких заданий. Она реализуется с помощью конфигурационного файла, в котором указываются данные о тестируемых заданиях.
На данный момент исходные коды системы HJudge ещё не выложены в открытый доступ, они хранятся на кафедральном репозитории.
Планы по дальнейшему развитию
- Интеграция с платформой Piazza. Поскольку студенты работают с Piazza, планируется интегрировать HJudge с ней — реализовать автоматическую передачу информации о задании с Piazza в систему.
- Интеграция с облачной платформой Everest[6]. Запуск системы как web-сервис позволит пользоваться ею не только преподавателям, но и студентам, поскольку можно будет ограничить доступ к тестам.
- Реализация возможности добавлять тесты, написанные на языках, отличных от Python.
Выводы
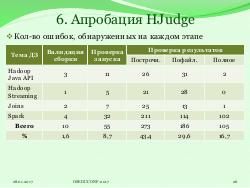
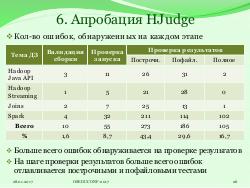
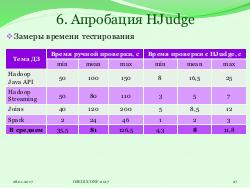
- Система HJudge успешно проявила себя на курсах ХОБОД и «Многопроцессорные вычислительные системы» в 2016 году в качестве проверяющей системы, позволив уменьшить время проверки заданий в среднем в 8–10 раз.
- В 2016 году HJudge была поставлена на баланс кафедры АТП ФИВТ МФТИ.
Примечания и отзывы
- ↑ Ивченко О. Н., Драль А. А. Hjudge: система тестирования приложений в экосистеме Hadoop // Сборник научных трудов МФТИ «Модели и методы обработки информации», г. Долгопрудный: МФТИ (ГУ), 2016 — 112–122.
- ↑ Piazza. The incredibly easy, completely free Q&A platform, piazza.com. — Название с экрана.
- ↑ Tom White. Hadoop: The Definitive Guide, издание 3, O’Reilly, 657.
- ↑ Maven. Introduction to the Build Lifecycle, maven.apache.org. — Название с экрана.
- ↑ Hadoop Wiki. How to develop Hadoop Tests, wiki.apache.org. — Название с экрана.
- ↑ O. V. Sukhoroslov, A. O. Rubtsov, S. Yu. Volkov. Development of distributed computing applications and services with Everest cloud platform // Computer Research and Modeling, г. Москва: ИППИ РАН, 2015 — 593–599.
!.jpg)
Plays:83
Comments:0