Apache Hadoop 2.0 (YARN). Последние тенденции в обработке больших данных (BigData)
Материал из 0x1.tv
Содержание
Аннотация
- Докладчик
- Алексей Костарев


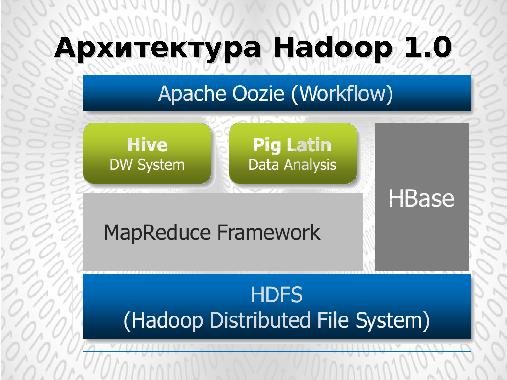
Вплоть до 2012 года основным моделью обработки больших объемов данных в Apache Hadoop был фреймворк MapReduce, обеспечивающий координацию процессов обработки данных (Map), распределенных по серверам кластера и процессов формирования итоговых результатов обработки (Reduce).
Все разрабатываемые в рамках Apache Hadoop продукты укладывались в прокрустово ложе этой технологии.
В апреле 2012 года разработчики компании Hortonworks предложили новую модель координации процессов обработки больших данных — YARN (Yet Another Resource Negotiator) которая в настоящее находит все большее распространение при создании программного обеспечения в области BigData. В докладе рассматриваются основные принципы программной среды YARN, средства координации процессов и перспективы использования данной технологии в разрабатываемом в рамках ГК «ИВС» репозитория C2R.
Видео
Слайды











Расширенные тезисы
Модель MapReduce
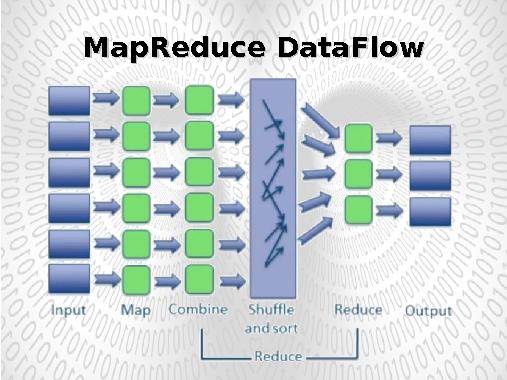
Модель MapReduce распределённых вычислений была предложена компанией Google для параллельных вычислений над очень большими (до несколько петабайт) наборами данных в компьютерных кластерах. Суть модели состояла в распределённом хранении и обработке однородных данных. В отличие от модели централизованной обработки данных (передача данных к вычислителю) модель MapReduce предоставляла механизм распределенной обработки (передача вычислений к данным).
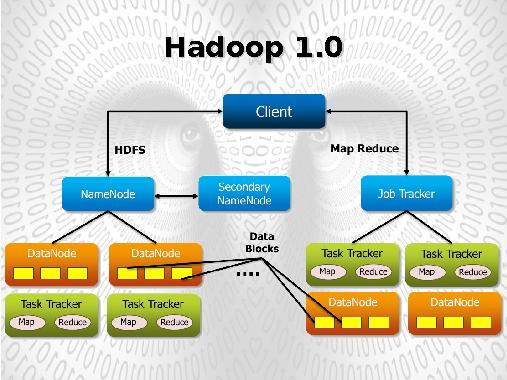
На каждом сервере, где хранятся обрабатываемые данные, запускается процесс Map, выполняющий обработку части данных, хранящейся на этом сервере. Результатом обработки является список пар ключ→значение которые передаются и процессам Reducer, формирующим итоговый результат.
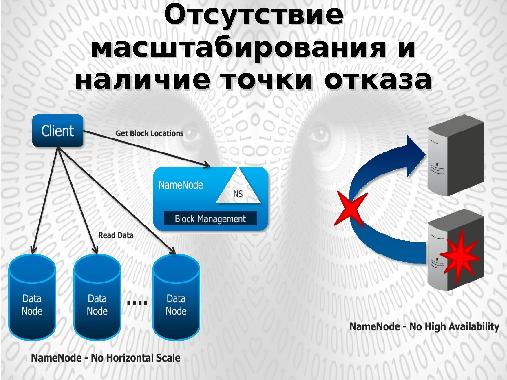
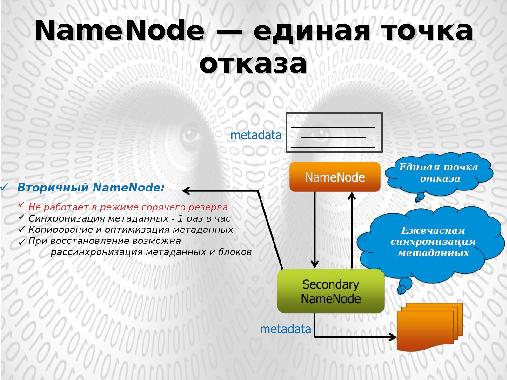
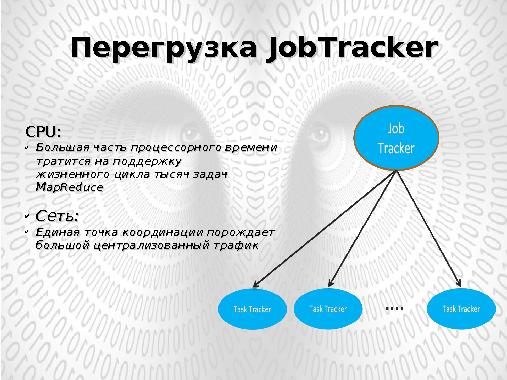
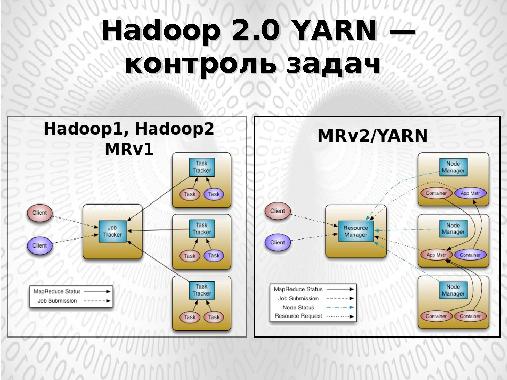
Координацию задач (Task) в рамках каждой работы (Job) производит центральный процесс JobTracker, отвечающий за управление ресурсами кластера, запуском задач Map, Reduce на узлах кластера и их перезапуском в случае сбоя.
Процессы TaskTracker, функционирующие на всех обрабатывающих узлах кластера отвечают лишь за запуск/останов задачи по запросу JobTracker и предоставления ему информации о статусе выполняемых задач.
Модель MapReduce является удобной средой для выполнения широкого класса задач обработки больших данных (BigData). Но существуют алгоритмы в области обработки графов (Google Pregel/Apache Giraph) и итеративного моделирования (Message Passing Interface — MPI ) реализация которых в модели MapReduce затруднена. Более того, так как модель MapReduce ориентируется на пакетную обработку данных, то реализация задач, требующих обработки в режиме реального (или близкого к реальному) времени (таких как потоковая обработка) в ее рамках невозможна.
В связи с этим В апреле 2012 года разработчики компании Hortonworks предложили новую модель координации процессов об работки больших данных — YARN (Yet Another Resource Neogitator).
Модель YARN
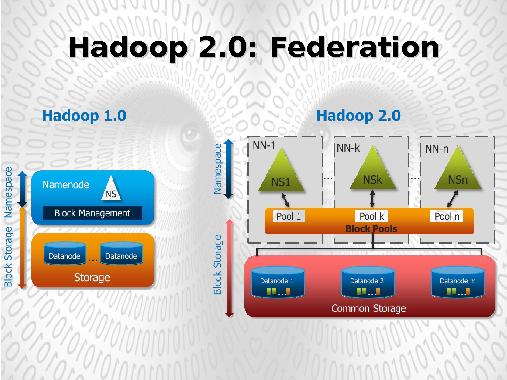
Фундаментальная идея модели YARN лежит в разделении 2-х основных функций JobTracker’а управление ресурсами и управления задачами.
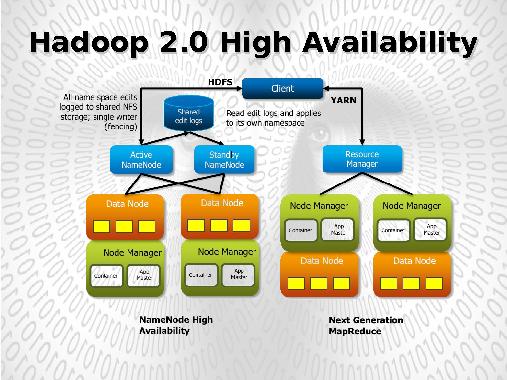
За управление ресурсами отвечает единый на весь кластер ResourceManager (см. рис. 2). Выполнение же каждой запускаемой в рамках кластера приложения отвечает отдельный демон — ApplicationMaster.
Таким образом каждый ApplicationMaster отвечает за запуск, выполнение и завершение своего приложения. В своей работе он:
- запрашивает наличие ресурсов у ResourceManager, определяет список серверов на которых необходимо запустить требуемые процессы;
- по полученному списку серверов обращается к NodeManager’ам данных серверов для запуска необходимого количества процессов (Container’s) для обработки данных;
- контролирует выполнение и завершение всех процессов работающих в рамках данного приложения.
Данная модель позволяет запускать и контролировать выполнение широкого класса задач по обработке данных включая задачи по обработке графов, постоянно функционирующие задачи по обработке потоковых данных, сервера распределенных баз данных и так далее.
_%D0%B2_%D0%BC%D0%BE%D0%B4%D0%B5%D0%BB%D0%B8_YARN.png)
Стандартные задачи MapReduce в этой модели являются лишь одним из типов поддерживаемых приложений.
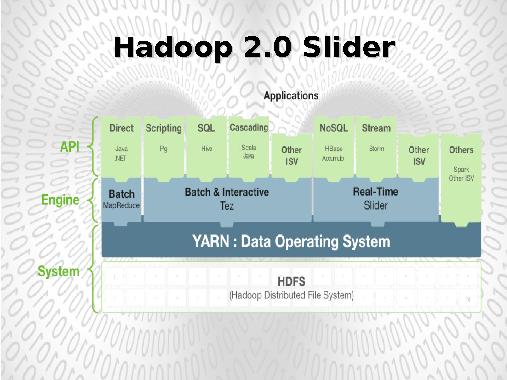
Текущее состояние платформы YARN (Hortonworks)
На настоящий момент (сентябрь 2014) наиболее активное участие в развитии модели YARN принимает компания Hortonworks.
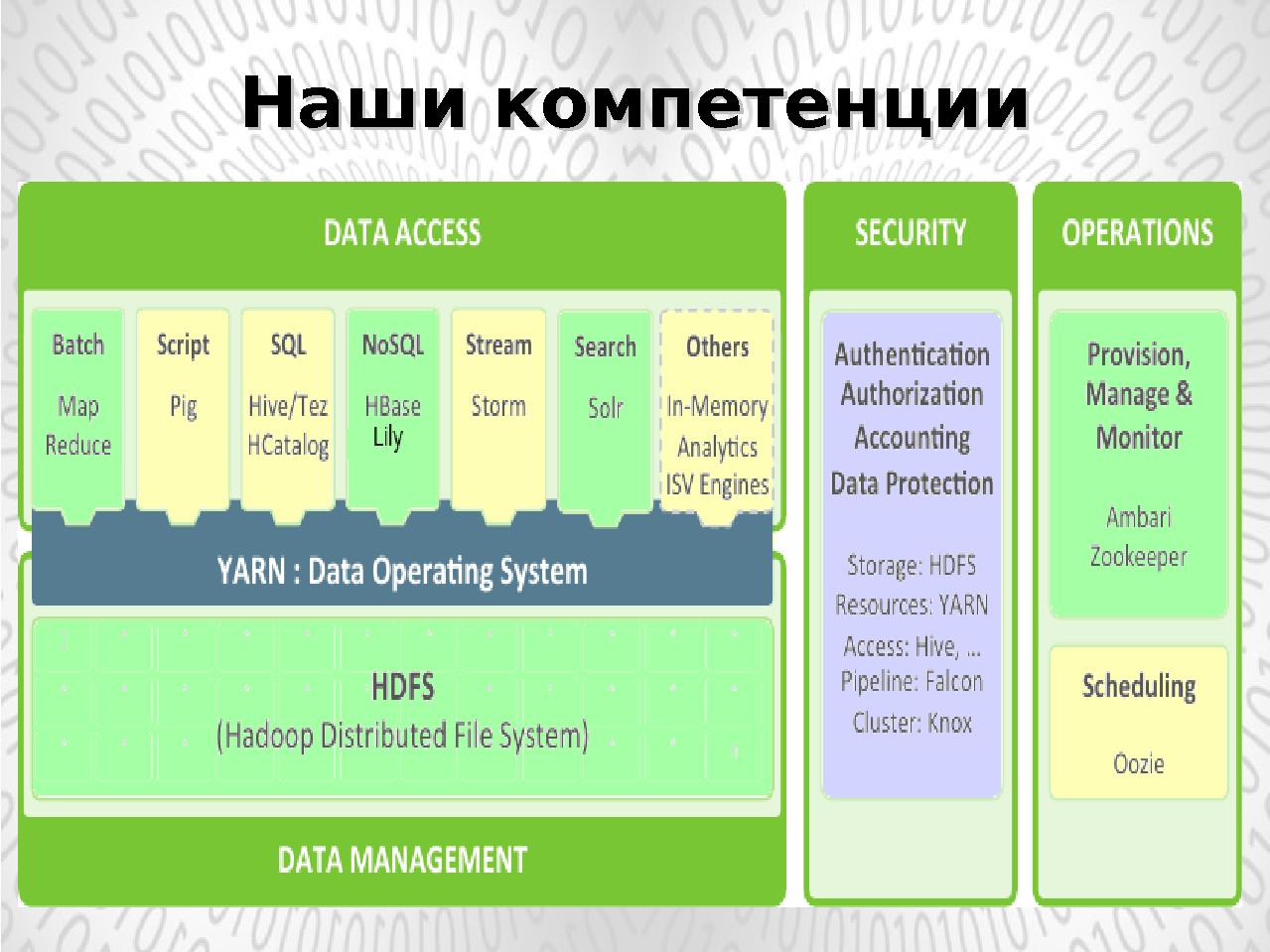
На рисунке отображены основные приложения, поддерживаемые в рамках платформы YARN.
Наиболее существенным нововведением нацеленным на адаптацию существующего программного обеспечения к модели YARN является предложенная в апреле 2014 года оболочка Slider, позволяющая без изменения кода интегрировать приложения в платформу YARN.
К этим приложениям, приведенным на рисунке, относятся:
- NoSQL база данных HBase,
- потоковая система обработки данных Storm,
- поисковая система Solr и другие приложения.
Slider позволяет запускать в рамках одного кластера несколько версий одно приложения, что обеспечивает весь цикл разработки приложений: создание, отладка, эксплуатация.
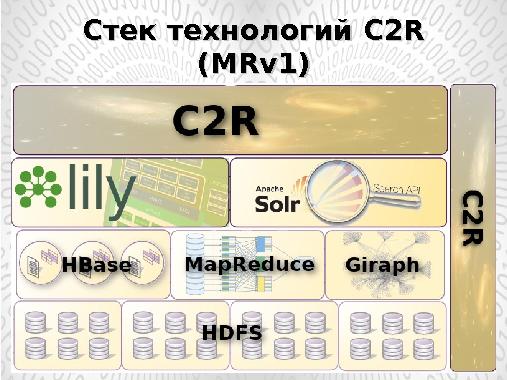
Разрабатываемый в рамках группы компаний ИВС облачный контент-репозиторий C2R использует часть приложений, поддерживаемых моделью YARN : NoSQL базу данных HBase, поисковую система Solr, framework MapReduce. В ближайшее время планируется перевод репозитория C2R на данную платформу и использование всего комплекса приложений платформы.
- Литература
- [1]
- Костарев А.Ф., Полещук А.Н., Контент-репозиорий C2R. Свидетельство о государственной регистрации программы для ЭВМ №2011617248/, 2011
- [2]
- Introducing Apache Hadoop YARN — http://hortonworks.com/blog/introducing-apache-hadoop-yarn/
- [3]
- Hortonworks Data Platform — http://hortonworks.com/hdp/
Примечания и отзывы
Plays:146
Comments:0