Развёртывание нейросети на базе ОС «Альт» для обнаружения онкологических заболеваний (Игорь Воронин, OSEDUCONF-2022) — различия между версиями
Материал из 0x1.tv
StasFomin (обсуждение | вклад) |
StasFomin (обсуждение | вклад) |
||
| (не показаны 2 промежуточные версии этого же участника) | |||
;{{SpeakerInfo}}: {{Speaker|Екатерина ЛапшинаИгорь Воронин}}
<blockquote>
В статье обсуждаются способы развёртывания и обучения глубокой сверточной нейросети в контейнере Docker, на базе ОС
Альт. Рассмотрены варианты разработки программного кода с использованием свободного программного обеспечения, которое позволяет создать программный продукт с минимальным набором навыков через визуальные интерфейсы и конструкторы с помощью Low-code платформы.необходимые ресурсы для создания разных моделей распознавания результатов анализов пациентов
по спектрограммам.
Предлагается решение — для определения онкологических заболеваний по спектрограммам из карт
опухолевой области мозга.
</blockquote>
{{VideoSection}}
{{vimeoembed|917658695|800|450}}
{{youtubelink|}}
|U7ZY6Wd_1Ys}}
{{SlidesSection}}
[[File:Тенденции разработки программного обеспечения с использованием Low-code платформРазвёртывание нейросети на базе ОС «Альт» для обнаружения онкологических заболеваний (Екатерина ЛапшинаИгорь Воронин, OSEDUCONF-2022).pdf|left|page=-|300px]]
{{----}}
== Thesis ==
Low-code платформы разработки — это приложение, которое предоставляет графический пользовательский интерфейс для
программирования и, таким образом, разрабатывает код с большей скоростью и сокращает затраченные усилия с минимальным
количеством кодирования.
Подобные платформы реализованы в числе, как свободное программное обеспечение (СПО)<ref name="d1">[https://www.hmong.press/wiki/Low-code_development_platform Платформа разработки low-code — определение]</ref>.
Такие среды разработки применяются для создания прикладного программного обеспечения через графический интерфейс
пользователя вместо стандартного программирования вручную. С помощью платформ Low-code возможно создание полностью
рабочего приложения, а в редких случаях — с использованием дополнительного кодирования. Данные среды разработки
также помогают сократить объём программирования, что позволяет ускорить создание приложений. Большим преимуществом
является то, что расширяется круг людей, которые могут внести свой вклад в разработку приложения. Low-code платформы
также могут снизить первоначальные затраты на настройку, обучение и обслуживание.
Недавнее исследование бостонской компании Mendix показало, что спрос на разработчиков среди ИТ-специалистов достиг
апогея. Почти шесть десяти (57%) говорят, что количество персонала, необходимого для разработки программного
обеспечения, увеличивается, а [https://www.reworked.co/information-management/whats-behind-the-explosion-of-low-code-and-no-code-applications/ стоимость разработки программного обеспечения растёт (61%)].
Также отметим, что в связи с растущими ожиданиями клиентов и изменением потребностей рынка после пандемии предприятия в отраслях всё
больше проявляют инициативу в создании цифрового контента для потребителей. Поэтому сегодня одним из актуальных решений
является работа с Low-code платформами.
Рассмотрим варианты Low-code платформ для различных целей.
* [https://nl-a
В современной медицине активно развиваются новые решения в области обработки и анализа данных полученных при помощи
рамановской спектроскопииnla-framework NL!A framework] — российский бесплатный low-code framework, позволяющий создавать полноценные бизнес-приложения. Модели, заложенные в кодогенератор NL!A framework, позволяют за считаные секунды создать полноценное рабочее бизнес-приложение;
* [https://www.outsystems.com/ OutSystem] — это надёжная и гибкая low-code платформа для разработки корпоративных мобильных и веб-приложений, которые разворачиваются в локальной или в гибридных средах;
*спектроскопии комбинационного рассеяния — когда спектроскопический метод исследования
используется для определения колебательных мод молекул и вибрационных мод в твёрдых телах. В данной работе проводится
анализ спектрограмм, на основе которых можно диагностировать и различить больную ткань живого человека от здоровой.
Для такой диагностики и распознавания спектров тканей была использована глубокая свёрточная нейросеть из пакета Keras — официального бэкэнда Tensorflow.
Оболочка Jupyter, делает использование Python намного проще и интуитивно понятнее даже для человека, далёкого от
программирования. Существуют платные серверы, где можно развернуть и использовать данную среду, с автообновлением и
регулярными backup-ами. В данной работе мы развернули нашу собственную нейросеть на серверном узле, с пропускной
способностью сети гигабит в секунду: [https://soware.ru/products/mendix Mendix] — это бескодовая (no-code) программная платформа, предоставляющая инструменты для создания, тестирования,развёртывания и проверки программных приложений.
Помимо бесплатных версий популярных платформ, также существуют различные варианты Low-code СПО с открытым исходным
кодом, таких как Appsemble, Skyve, Baserow и другие. Наличие таких разнообразных платформ://astera.laser.ru:8888/?token=c4d16a340eab7fbc5b285effd01127b0ada478413fb9b9ad]
В нашем случае мы использовали уже предустановленный Doсker — сконфигурированный для развёртывания на множестве
серверов.
<pre>
$ docker-compose up -d
</pre>
Определить адрес токена для доступа к серверу с запущенной нейросетью можно по команде:
<pre>
$ docker logs tf_test
</pre>
От медицинских работников были получены спектрограммы здоровых и больных тканей человека. Для обучения сети была
обработана выборка порядка 1000 спектрограмм. Сеть развёртывалась в операционной системе — на российской платформе
Alt p10. Основные вычисления производились на CPU сервере. Обязательным условием в нём должна быть инструкция AVX,наличие которой можно диагностировать следующей командой:
<pre>
$cat /proc/cpuinfo |grep avx
</pre>
Каждый файл исходных данных содержит информацию о длине волны и интенсивности. Для разбора итоговых данных мы
закодировали результаты в матрицу:
* [1,0,0] — abouttumoral (околоопухолевая область )
* [0,1,0] — healthy (здоровая область )
* [0,0,1] — sick (опухолевая область )
Делим датасет на тренировочную часть и тестовую в соотношении 85 к 15 параметром test_size=0.15
Были использованы предопределённые классы для слоёв:
* Dense() — полносвязный слой;
* Conv1D, Conv2D — свёрточные слои;
* MaxPooling2D, Dropout, BatchNormalization — вспомогательные слои
А также предопределённые классы моделей:
* Model — общий класс модели;
* Sequential — последовательная модель.
У каждого слоя и у модели в целом имеется свойство weights, содержащее список настраиваемых параметров (весовых
коэффициентов). В нашем случае сеть в себя включает 16,757,443 параметров.
Создаём архитектуру модели, которая является основой для определения MNIST dataset:
<pre>
model2 = Sequential()
model2.add(Conv1D(128, 4, activation='relu', input_shape=(1015,1),kernel_regularizer=
regularizers.l1_l2(l1=1e-5,l2=1e-4))) # 32 neurons
model2.add(Conv1D(128, 4, activation='relu', bias_regularizer=regularizers.l2(1e-4)))
# 32 neurons
model2.add(BatchNormalization())
model2.add(Activation('relu'))
model2.add(MaxPooling1D())
model2.add(Dropout(0.25))
model2.add(Conv1D(256, 2, activation='relu', kernel_regularizer=regularizers.l1_l2(
l1=1e-5, l2=1e-4))) # 64 neurons
model2.add(Conv1D(256, 2, activation='relu', bias_regularizer=regularizers.l2(1e-4)))
# 64 neurons
model2.add(BatchNormalization())
model2.add(Activation('relu'))
model2.add(MaxPooling1D())
model2.add(Dropout(0.25))
model2.add(Flatten())
model2.add(Dense(256, activation = 'relu', use_bias=False))
model2.add(BatchNormalization())
model2.add(Activation('relu'))
model2.add(Dense(128, activation = 'relu', use_bias=False))
model2.add(BatchNormalization())
model2.add(Activation('relu'))
model2.add(Dense(64, activation = 'relu', use_bias=False))
model2.add(BatchNormalization())
model2.add(Activation('relu'))
model2.add(Dropout(0.25))
model2.add(Dense(3, activation = 'softmax'))
model2.summary()
model2.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
model2_hist = model2.fit(xtrain, ytrain ,batch_size=128, epochs=100, verbose=1)
Total params: 16,757,443
Trainable params: 16,755,779
Non-trainable params: 1,664
</pre>
<pre>
Epoch 1/100
1/1 [=============================] - 2s 2s/step - loss: 1.7923 - accuracy: 0.2321
Epoch 100/100
1/1 [=============================] - 1s 713ms/step - loss: 0.3576 - accuracy: 0.9107
</pre>
Чтобы оценить итоговую точность модели на тестовой части датасета, выполняем следующие команды:
<pre>
acc = model2.evaluate(xtest, ytest)
print("Loss:", acc[0], "Accuracy:", acc[1])
pred = model2.predict(xtest)
print(np.round(pred,2))
1/1 [=============================] - 0s 229ms/step - loss: 9.8597 - accuracy: 0.9636
[[0.09 0.91 0. ]
[0.01 0.99 0. ]
[0. 1. 0. ]
[0. 1. 0. ]
[0.1 0.9 0. ]]
</pre>
[[File:Pereslavl-2022-woronin-woronin-woronin-img001.png|center|640px|thumb|model 2 — accuracy from epoch]]
Полученный результат говорит о популярности данных
решений и их развитии.
Есть ряд других причин, по которым предприятиям следует рассматривать Low-code платформы:
# Более быстрый выход на рынок;
# Повышение удовлетворённости клиентов;
# Снижение затрат на ИТ-инфраструктуру;
# Более эффективное управление приложениями;
# Лучшее управление ИТ;
Безусловно, подобные среды разработки — это не панацея, а лишь вариантдля создания программного продукта, поэтому
Low-code платформы имеют ряд минусов:
# Сложность в выборе подходящего ресурса;
# Ограничения в функционале;
# Зависимость от платформы;
Рассматривая плюсы и минусы Low-code платформ, можно сделать вывод, что они отлично подходят для быстрого создания
небольших проектов и увеличения количества реализуемых решений. Они сокращают разрыв между пользователями и
разработчиками, что позволяет в короткий срок получить работающий прототип и сформировать видение будущей системы.
Также можно проследить стремительное развитие данного направления и как СПО.
См также: Лапшина Е.том, что тестовые спектрограммы были распознаны с вероятностью 91% для здоровых тканей.
* https://keras.io/api/layers/
* https://keras.io/api/models/
* https://keras.io/guides/training_with_built_in_methods/
* https://proproprogs.ru/tensorflow/keras-posledovatelnaya-model-sequential
., Симонов В.Л. Преимущества информационных систем с веб-интерфейсом // XIX Международная конференция
«Современные информационные технологии в образовании, науке и промышленности» 29—30 апреля 2021 года, г. Москва.
{{----}}
[[File:{{#setmainimage:Тенденции разработки программного обеспечения с использованием Low-code платформРазвёртывание нейросети на базе ОС «Альт» для обнаружения онкологических заболеваний (Екатерина ЛапшинаИгорь Воронин, OSEDUCONF-2022)!.jpg}}|center|640px]]
{{LinksSection}}
<!-- <blockquote>[©]</blockquote> -->
<references/>
[[Категория:OSEDUCONF-2022]]
[[Категория:Draft]] | |||
Текущая версия на 03:27, 15 марта 2024
- Докладчик
- Игорь Воронин


В статье обсуждаются способы развёртывания и обучения глубокой сверточной нейросети в контейнере Docker, на базе ОС Альт. Рассмотрены необходимые ресурсы для создания разных моделей распознавания результатов анализов пациентов по спектрограммам.
Предлагается решение — для определения онкологических заболеваний по спектрограммам из карт опухолевой области мозга.
Содержание
Видео
Презентация








Thesis
В современной медицине активно развиваются новые решения в области обработки и анализа данных полученных при помощи рамановской спектроскопии или спектроскопии комбинационного рассеяния — когда спектроскопический метод исследования используется для определения колебательных мод молекул и вибрационных мод в твёрдых телах. В данной работе проводится анализ спектрограмм, на основе которых можно диагностировать и различить больную ткань живого человека от здоровой. Для такой диагностики и распознавания спектров тканей была использована глубокая свёрточная нейросеть из пакета Keras — официального бэкэнда Tensorflow.
Оболочка Jupyter, делает использование Python намного проще и интуитивно понятнее даже для человека, далёкого от программирования. Существуют платные серверы, где можно развернуть и использовать данную среду, с автообновлением и регулярными backup-ами. В данной работе мы развернули нашу собственную нейросеть на серверном узле, с пропускной способностью сети гигабит в секунду: [1]
В нашем случае мы использовали уже предустановленный Doсker — сконфигурированный для развёртывания на множестве серверов.
$ docker-compose up -d
Определить адрес токена для доступа к серверу с запущенной нейросетью можно по команде:
$ docker logs tf_test
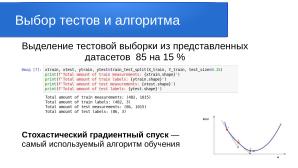
От медицинских работников были получены спектрограммы здоровых и больных тканей человека. Для обучения сети была обработана выборка порядка 1000 спектрограмм. Сеть развёртывалась в операционной системе — на российской платформе Alt p10. Основные вычисления производились на CPU сервере. Обязательным условием в нём должна быть инструкция AVX,наличие которой можно диагностировать следующей командой:
$cat /proc/cpuinfo |grep avx
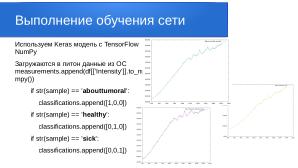
Каждый файл исходных данных содержит информацию о длине волны и интенсивности. Для разбора итоговых данных мы закодировали результаты в матрицу:
- [1,0,0] — abouttumoral (околоопухолевая область )
- [0,1,0] — healthy (здоровая область )
- [0,0,1] — sick (опухолевая область )
Делим датасет на тренировочную часть и тестовую в соотношении 85 к 15 параметром test_size=0.15
Были использованы предопределённые классы для слоёв:
- Dense() — полносвязный слой;
- Conv1D, Conv2D — свёрточные слои;
- MaxPooling2D, Dropout, BatchNormalization — вспомогательные слои
А также предопределённые классы моделей:
- Model — общий класс модели;
- Sequential — последовательная модель.
У каждого слоя и у модели в целом имеется свойство weights, содержащее список настраиваемых параметров (весовых
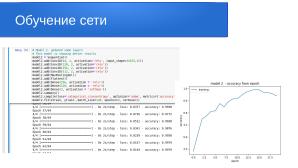
коэффициентов). В нашем случае сеть в себя включает 16,757,443 параметров.
Создаём архитектуру модели, которая является основой для определения MNIST dataset:
model2 = Sequential()
model2.add(Conv1D(128, 4, activation='relu', input_shape=(1015,1),kernel_regularizer=
regularizers.l1_l2(l1=1e-5,l2=1e-4))) # 32 neurons
model2.add(Conv1D(128, 4, activation='relu', bias_regularizer=regularizers.l2(1e-4)))
# 32 neurons
model2.add(BatchNormalization())
model2.add(Activation('relu'))
model2.add(MaxPooling1D())
model2.add(Dropout(0.25))
model2.add(Conv1D(256, 2, activation='relu', kernel_regularizer=regularizers.l1_l2(
l1=1e-5, l2=1e-4))) # 64 neurons
model2.add(Conv1D(256, 2, activation='relu', bias_regularizer=regularizers.l2(1e-4)))
# 64 neurons
model2.add(BatchNormalization())
model2.add(Activation('relu'))
model2.add(MaxPooling1D())
model2.add(Dropout(0.25))
model2.add(Flatten())
model2.add(Dense(256, activation = 'relu', use_bias=False))
model2.add(BatchNormalization())
model2.add(Activation('relu'))
model2.add(Dense(128, activation = 'relu', use_bias=False))
model2.add(BatchNormalization())
model2.add(Activation('relu'))
model2.add(Dense(64, activation = 'relu', use_bias=False))
model2.add(BatchNormalization())
model2.add(Activation('relu'))
model2.add(Dropout(0.25))
model2.add(Dense(3, activation = 'softmax'))
model2.summary()
model2.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
model2_hist = model2.fit(xtrain, ytrain ,batch_size=128, epochs=100, verbose=1)
Total params: 16,757,443
Trainable params: 16,755,779
Non-trainable params: 1,664
Epoch 1/100 1/1 [=============================] - 2s 2s/step - loss: 1.7923 - accuracy: 0.2321 Epoch 100/100 1/1 [=============================] - 1s 713ms/step - loss: 0.3576 - accuracy: 0.9107
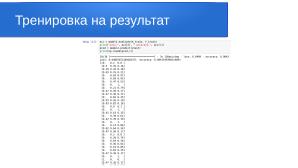
Чтобы оценить итоговую точность модели на тестовой части датасета, выполняем следующие команды:
acc = model2.evaluate(xtest, ytest)
print("Loss:", acc[0], "Accuracy:", acc[1])
pred = model2.predict(xtest)
print(np.round(pred,2))
1/1 [=============================] - 0s 229ms/step - loss: 9.8597 - accuracy: 0.9636
[[0.09 0.91 0. ]
[0.01 0.99 0. ]
[0. 1. 0. ]
[0. 1. 0. ]
[0.1 0.9 0. ]]

Полученный результат говорит о том, что тестовые спектрограммы были распознаны с вероятностью 91% для здоровых тканей.
- https://keras.io/api/layers/
- https://keras.io/api/models/
- https://keras.io/guides/training_with_built_in_methods/
- https://proproprogs.ru/tensorflow/keras-posledovatelnaya-model-sequential
!.jpg)