Оптимизация СПО для платформы Эльбрус (OSSDEVCONF-2021)
Материал из 0x1.tv
- Докладчик


Рассмотрены различные методы оптимизации ПО для архитектуры Эльбрус. Представлены результаты оптимизации СПО проектов и даются практические рекомендации по подобной работе.
Содержание
Видео[править вики-текст]
Презентация[править вики-текст]














Thesis[править | править вики-текст]
Введение[править | править вики-текст]
Эльбрус (e2000, e2k), в отличие от большинства других архитектур, использует набор инструкций с широким командным словом (VLIW) и позволяет выполнять десятки команд общего назначения за такт (до 25 для 4-го поколения, до 50 для 5-го). Это свойства приводят к гораздо более сильной зависимости производительности кода от степени его оптимизации как компилятором, так и программистом, c учётом особенностей архитектуры.
Рассмотрим способы оптимизации кода от простого к сложному.
Новые версии компилятора[править | править вики-текст]
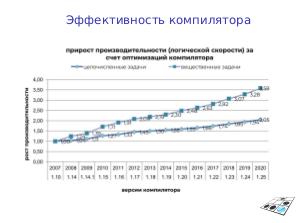
Внутренний параллелизм и оптимальное заполнение VLIW — сложная задача, поэтому даже без изменения кода можно получить его существенное ускорение, используя последнее поколение компилятора. Например, прирост производительности между lcc-1.10 и lcc-1.25 составляет 2.05 раз для целочисленных вычислений и 3.58 раз для плавающей запятой[1].
Оптимизация для целевого процессора[править | править вики-текст]
lcc позволяет компилировать как приложения, работающие на любой архитектуре, начиная с заданной (-march), так и для конкретной модели процессора (-mtune). Во втором случае код получается быстрее, но он не будет работать на других моделях процессоров. Эксперименты с ядром показали прирост от 0.5% (мало, но статистически достоверно), до 8% в случае с 1С+.
Профилирование[править | править вики-текст]
Профилирование по семантике аналогично gcc (-fprofile-generate, -fprofile-use), но сложнее в практической эксплуатации. Для xz получен прирост . Код доступен в Сизифе[2], где можно посмотреть пример практического применения и обхода проблем.
Использование SIMD[править | править вики-текст]
Для SIMD оптимизаций предпочтительно использовать интринсики (встроенные фукнции компилятора), а не писать всё на непосредственно на ассмеблере. Основные особенности:
Векторные команды x86[править | править вики-текст]
SIMD команды Эльбруса копируют векторные команды x86, но есть различия:
- Нет варианта некоторых команд, например
_mm_dp_ps(), она эмулируется компилятором, поэтому будет работать медленно. - Операция Shuffle на Эльбрусе может использовать таблицу в 2 регистра, поэтому можно написать более эффективный код.
Векторные интринсики x86[править | править вики-текст]
lcc понимает интринсики от MMX до AVX2, используя эквивалентные команды для Эльбруса. Если эквивалента не будет, то будет использована медленная эмуляция.
Особенности архитектур[править | править вики-текст]
v3,v4: 64-х разрядные регистры и поддержку почти всех SSE4.1 команд, одна векторная инструкция вычисляет только 64-бит результата. Медленно читает невыровненные данные, в том числе если данные выровнены, но компилятор об этом не знает.
v5: регистры 128-разрядные, появились эквиваленты векторных команд, которые обрабатывают 128-бит. Быстрее читает невыровненные данные.
v6: предполагается ускорение работы с невыровненными данными.
Выбор интринсиков[править | править вики-текст]
Удобнее использовать интринсики x86, чем Эльбруса:
- Их можно скомпилировать как для v3 так и для v5, для эмуляции SSE интринсика компилятор сгенерирует одну команду для v5 и две команды для v3. На v3 будет использовано в два раза больше регистров. Но регистров у Эльбруса много (256). Зато не нужно писать отдельные версии кода для v3 и v5, что сокращает разработку.
- Оптимизацию можно разрабатывать и отлаживать на x86, лишь в финале проверяя на Эльбрусе. Небольшая часть вещей специфичных для Эльбруса выносится в макросы (которые эмулируют то же самое на x86).
- AVX команды эмулируются тем же образом, как SSE на v3. Использовать не рекомендуется из-за большого перерасхода регистров.
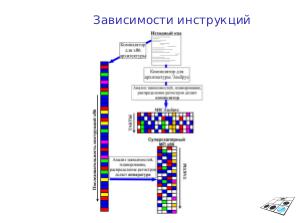
Зависимости между данными[править | править вики-текст]
Компилятор для Эльруса должен заранее знать об отсутствии зависимости между данными чтобы сгенерировать быстрый код. Например, для кода:
for (i = 0; i < n; i++) dst[i] = src[i] + x;
компилятор не знает, существует ли зависимость между данными (например, что dst будет указывать на src + 1). Поэтому вставит ожидание между записью dst и чтением src из следующей итерации. Чтобы этого не происходило, нужно указывать #pragma ivdep перед циклом.
Выравнивание данных[править | править вики-текст]
В lcc-1.25 не работают__attribute__((aligned(N))) или __builtin_assume_aligned(ptr, N), но есть два способа этого добиться:
- Опция lcc
-faligned, но тогда любые указатели будет считаться выровненными, что неудобно и опасно в больших проектах. - Прямой сброс младших бит указателя:
ptr = (T*)((intptr_t)ptr & -8);тогда LCC понимает что память выровнена. Но если придёт невыровненный указатель то не будет ошибки, но будут неправильные вычисления, или придётся добавить assert (что лишний код, замедлит при использовании в цикле). Также это лишняя операция AND, что критично в части кода (например циклы или макросы).
Оптимизированное СПО[править | править вики-текст]
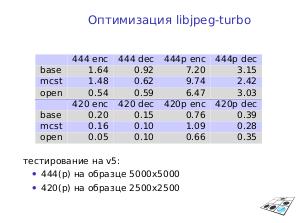
На Эльбрус портированы или оптимизированы д14 популярных СПО проектов[3], включая ffmpeg, x264, libjpeg-turbo — всего 33 тыс. строк, 1.3 МБ исходного кода. Они уже доступны в Сизифе, ведётся взаимодействие с апстримами.
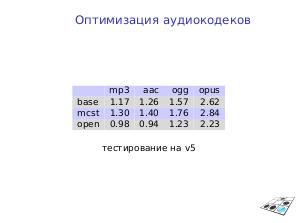
| Аудио | mp3 | aac | ogg | opus |
|---|---|---|---|---|
| base | 1.17 | 1.26 | 1.57 | 2.62 |
| mcst | 1.30 | 1.40 | 1.76 | 2.84 |
| open | 0.98 | 0.94 | 1.23 | 2.23 |
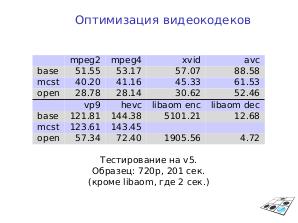
| Видео | mpeg2 | mpeg4 | xvid | avc | vp9 | hevc |
|---|---|---|---|---|---|---|
| base | 51.55 | 53.17 | 57.07 | 88.58 | 121.81 | 144.38 |
| mcst | 40.20 | 41.16 | 45.33 | 61.53 | 123.61 | 143.45 |
| open | 28.78 | 28.14 | 30.62 | 52.46 | 57.34 | 72.40 |
Результаты для основных кодеков в сёк (меньше — лучше) в режиме декодирования. Тестировалось на 720p, 201 сёк. base — исходный код, mcst — бинарные файлы МЦСТ, open — опубликованное открытое решение.
!.jpg)
Примечания и ссылки[править вики-текст]
- ↑ Прирост производительности за счёт оптимизации компилятора https://www.altlinux.org/lcc#/media/File:Lcc-performance.jpg
- ↑ xz: поддержка профилирования на e2k http://git.altlinux.org/gears/x/xz.git?p=xz.git;a=commit;h=7ed55a11d0643c5b53234c700163b72a41a7af30
- ↑ Патчи оптимизации для e2k разного СПО https://github.com/ilyakurdyukov/e2k-ports
{kind=link}
- Эльбрус upstream https://www.altlinux.org/Эльбрус/upstream
Plays:0 Comments:0