Программирование на C для PostgreSQL (Александр Коротков, LVEE-2015)
Материал из 0x1.tv
Содержание
Аннотация
- Докладчик
- Александр Коротков


PostgreSQL offers great extendability. Users can add literally everything on their own: data types, functions, operators, index types, procedural languages and so on. But in order to use the full power of these features one should write C code for PostgreSQL. Traditionally it's assumed that barrier to entry of C programming for PostgreSQL is very high. That's why extendability of PostgreSQL is no as demanded as it could be.
The goal of present talk is to overcome this circumstances.
Видео
Слайды





































Тезисы
PostgreSQL обладает отличной расширяемостью, пользователи могут добавлять сами буквально всё: типы данных, функции, операторы, типы индексов, языки хранимых процедур и т.д. Но для того, чтобы использовать многие из этих возможностей, нужно уметь программировать под PostgreSQL на C.
Традиционно считается, что это сложно и порог вхождения очень велик. Из-за этого вся мощь расширяемости PostgreSQL оказывается не так востребована, как могла бы быть. Мне хотелось бы это обстоятельство постепенно преодолевать. Действительно, как и в любом большом проекте, написанном на языке C, программирование под PostgreSQL имеет свои особенности.
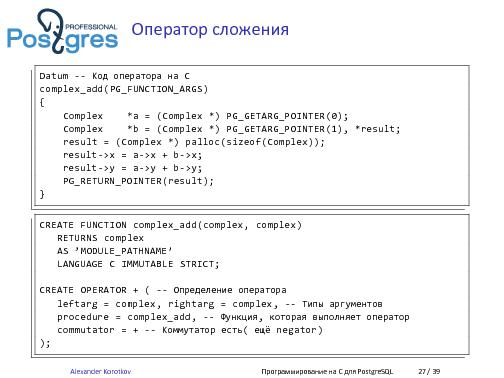
В PostgreSQL используется свой calling convention, благодаря которому функции, написанные как на C, так и на процедурных языках, могут быть видны из SQL. Есть универсальный тип данных – Datum, к которому может быть приведено значение любого типа. Параметры и результат передаются как Datum. Ниже приведён пример функции, использующей PostgreSQL calling convention.
PG_FUNCTION_INFO_V1(increment); Datum increment(PG_FUNCTION_ARGS) { int32 arg = PG_GETARG_INT32(0); PG_RETURN_INT32(arg + 1); }
В PostgreSQL есть свой менеджер памяти: любое выделение памяти осуществляется в рамках некоторого контекста памяти. Контексты памяти, в свою очередь, образуют иерархическую структуру. Ниже приведён шаблон функции, которая возвращает набор строк (set-returning function). Такая функция вызывается для каждой отдельной строки. Память, которую эта функция выделяет, будут освобождена перед следующим вызовом, но также доступен контекст памяти, которых сохраняется между вызовами.
Datum my_set_returning_function(PG_FUNCTION_ARGS) { FuncCallContext *funcctx; Datum result; if (SRF_IS_FIRSTCALL()) { MemoryContext oldcontext; funcctx = SRF_FIRSTCALL_INIT(); oldcontext = MemoryContextSwitchTo(funcctx->multi_call_memory_ctx); /* Инициализация структур памяти, которая выполняется только один раз */ пользовательский код MemoryContextSwitchTo(oldcontext); } /* Инициализация структур памяти, которая выполняется каждый раз */ пользовательский код funcctx = SRF_PERCALL_SETUP(); пользовательский код /* Нужно ли вернуть ещё одну строку или все строки уже возвращены? */ if (funcctx->call_cntr < funcctx->max_calls) { /* Возврат следующей строки результата (result) */ пользовательский код SRF_RETURN_NEXT(funcctx, result); } else { /* Все строки уже были возвращены, выполняется освобождение использованных ресурсов, если нужно */ пользовательский код SRF_RETURN_DONE(funcctx); } }
Благодаря тому, что любой контекст памяти можно очистить в любой момент времени, во многих случаях можно не освобождать отдельно каждый участок памяти. При этом накладные расходы несравнимо малы по сравнению с применением сборщика мусора.
Посылать к БД SQL-запросы можно напрямую в тот же backend, из которого вызвана функция. Для этого есть специальный интерфейс – SPI. Ниже приведён пример функции, который выполняет запрос и выводит его результаты в виде INFO сообщений. Её аргументами являются текст запроса в виде text, и максимальное число выводимых строк ответа.
int execq(text *sql, int cnt) { char *command; int ret; int proc; /* Преобразуем text в C-строку */ command = text_to_cstring(sql); SPI_connect(); ret = SPI_exec(command, cnt); proc = SPI_processed; /* * Если удалось получить строки, то выводим их через elog(INFO). */ if (ret > 0 && SPI_tuptable != NULL) { TupleDesc tupdesc = SPI_tuptable->tupdesc; SPITupleTable *tuptable = SPI_tuptable; char buf[8192]; int i, j; /* Цикл по строкам ответа */ for (j = 0; j < proc; j++) { HeapTuple tuple = tuptable->vals[j]; /* Цикл по полям строки ответа */ for (i = 1, buf[0] = 0; i <= tupdesc->natts; i++) snprintf(buf + strlen (buf), sizeof(buf) - strlen(buf), " %s%s", SPI_getvalue(tuple, tupdesc, i), (i == tupdesc->natts) ? " " : " |"); elog(INFO, "EXECQ: %s", buf); } } SPI_finish(); pfree(command); return (proc); }
Но если немного привыкнуть, то для того, кто уже имеет опыт на C, программировать под PostgreSQL не так уж и сложно. А благодаря тому, что уже есть готовые удобные макросы, функции, структуры данных, это может быть даже проще, чем на чистом C.
Примечания и отзывы
Plays:152 Comments:0