Методы кросс-языкового поиска документов (Денис Зубарев, ISPRASOPEN-2019)
Материал из 0x1.tv
- Докладчик
- Денис Зубарев


Cравниваются различные методы кросс-языкового поиска похожих документов.
Для сравнения используется русско-английская языковая пара.
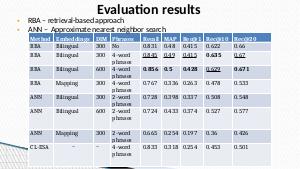
Сравниваются известные методы, такие как CL-ESA, с методами, основанными на кросс-языковых эмбеддингах. Для поиска документов используется приближенный поиск ближайшего соседа (ANN), использующий расстояния между векторами, представляющими документы.
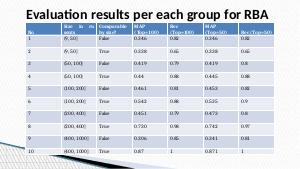
Также применяется более традиционный подход с использованием инвертированного индекса, с дополнительным шагом: отображение ключевых слов с одного языка на другой с помощью кросс-языковых эмбеддингов. Для экспериментальной оценки всех методов используются русские статьи из Википедии, которые имеют аналоги в англоязычной версии.
Проведенные эксперименты показывают, что подход с инвертированным индексом показывает лучшие результаты по двум метрикам: полнота и средняя точность (MAP).
In this paper, we compare different methods for cross-lingual similar document retrieval. We focus on Russian-English language pair. We compare well-known methods like Cross Lingual Explicit Semantic Analysis (CL-ESA) with methods based on cross-lingual embeddings. We use approximate nearest neighbor (ANN) search to retrieve documents based entirely on distances between learned document embeddings. Also we employ a more traditional approach with usage of inverted index, with extra step of mapping top keywords from one language to other with the help of cross-lingual word embeddings. We use Russian-English aligned Wikipedia articles to evaluate all approaches. Conducted experiments show that an approach with inverted index achieves better performance in terms of recall and MAP than other methods.
Видео
Презентация














!.jpg)
Примечания и ссылки
Plays:12 Comments:0