Настройка и использование нейросетей в «Альт» для анализа и обработки результатов экспериментов (Игорь Воронин, OSEDUCONF-2021)
Материал из 0x1.tv
- Докладчик
- Игорь Воронин


Системы поддержки принятия решений всё больше входят в нашу повседневность. Мы уже не замечаем, что поисковые системы подсказывают результаты запросов — с учётом наших предпочтений.
В нашей повседневности и в работе мы всё больше и больше принимаем решения опираясь на подсказки которые получаем от искусственного интеллект.
Содержание
Видео
Презентация







Thesis
Под работой искусственного интеллекта в последнее время подразумевается функционирование нейросети. Поисковики формируют новостную ленту по нашим интересам, основываясь на нейросетях.
Алиса из Яндекса больше знает о наших предпочтениях, чем мы сами, поскольку является нейросетью.
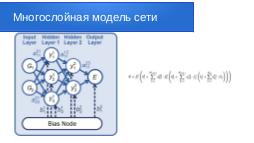
Нейросеть — это математическая модель, которая получает на вход один набор данных, а на выходе, после ряда преобразований, выдаёт другой набор данных. Такие преобразования осуществляются на основе полученных данных, по стандартным математическим алгоритмам, с учётом так называемых весовых коэффициентов.
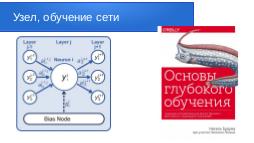
Иначе говоря, нейросеть — это программа, которая состоит из конечных автоматов как узлов и все эти узлы связаны между собой связями. Каждая связь имеет весовой коэффициент. Узлы объединяются в слои. Чем больше слоёв, тем более точный результат может выдавать такая нейросеть, после обучения.
Прогресс экспериментальных методов привёл к новым знаниям. Однако интерпретация этих экспериментальных знаний, совершение новых открытий, невозможно без дополнительной обработки при помощи программного моделирования. Например, не возможно понять структуру нового материала на атомном уровне без взаимодействия экспериментов и теории. Несмотря на современные методы исследований, которые предлагает сканирующие туннельные микроскопы, просвечивающая электронная микроскопия и др. необходимость использования расчётов теоретических исследований так же возрастает.
Для предсказания заданных параметров нужно провести большие объёмы вычислений и как новые принципы организации расчётных алгоритмов, для решения этой задачи, используется обучение машинному программированию таких нейросетей (англ. MLP)
[woronin1-img001]
Процесс обучения — это выставление весов на связях между узлами используемой нейросети. Для проведения обучения нам нужны две выборки из набора данных (dataset): одна обучающая на которой происходит процесс обучения самой нейросети, вторая тестовая, запустив которую, мы должны убедится, что сеть обучена и, например, распознаёт заданные предметы на проставленных изображениях с достаточной нам точностью. Желательно конечно чтобы точность была 100%, но на всех снимках этого достигнуть практически не возможно, поэтому при задании на разработку нейросети мы должны полагаться на реальные значения. Обычная практика — это 80% снимков на обучение и 20 % на тестирование.
Поскольку количество весовых параметров Xi и Ai часто составляет порядки нескольких тысяч, то зачастую невозможно найти глобальный минимум в этом процессе оптимизации.
Однако найти множество приемлемых локальных минимумов несложно — это будем называть обучением. Обучение нейросети очень требовательно и может занять несколько недель, особенно при использовании больших наборов данных. Поэтому чем более производительные процессоры, чем больше вычислительной мощности у вас имеется в распоряжении, тем более быстрый процесс будет подготовки сети для работы.
Для обучения и тренировки сети рассчитываются количества весовых параметров, которые заданы архитектурой сети. Именно от количества скрытых слоёв и нейронов на слой зависит производительность всей системы и точность результата
- Вариант (a), недообученная сеть, здесь ошибка подгонки велика, и нейросеть не может точно воспроизвести ожидаемый результат.
- Вариант (б). Нормально обученная и оттестированная сеть
- Вариант (в). Если будет использовано ещё больше параметров, путём увеличения размера нейросети, то может произойти переобучение. Что повлечёт плохое общее представление результата, и, к сожалению, не может быть обнаружено ошибками на этапе тестирования сети.
Существует несколько вариантов обнаружения и предотвращения такого переобучения.
[woronin1-img002]
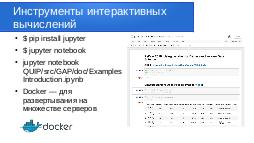
Инструментом для обучения и использования нейросетей, является оболочка Jupyter — это среда для интерактивных вычислений, которая делает использование Python намного проще и интуитивно понятнее. Особенно полезной является его среда записной книжки, которая предоставляет удобный способ экспериментировать с кодом, просматривать результаты и фиксировать на будущее свои успехи.
[woronin1-img003]
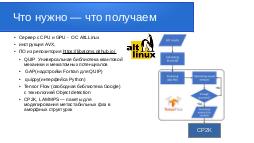
Обязательные и необходимые компоненты, которые должны быть установлены на сервере для работы с Jupiter: GCC, gfortran, Python, библиотеки линейной алгебры.
$ apt-get install gcc gfortran python python-pip libblas-dev liblapack-dev
Предпочтения $ pip install numpy ase f90wrap
Для оболочек Python (quippy) минимальные требования:
- Python 3
- NumPy http://www.numpy.org (numpy>=1.5.0)
$ pip install jupyter $ jupyter notebook $ jupyter notebook QUIP/src/GAP/doc/ExamplesIntroduction.ipynb
Doсker — удобный инструмент для развёртывания вашей обученной нейросети на множестве серверов
Для обучения по образам мы берём фотографии нужных нам объектов. Например мы хотим распознавать маски на лицах. Для обучения сети нам нужно порядка 1000 снимков. Каждый снимок перед началом запуска обучения нам нужно растегеть. Т.е в специальной программе указать теги — координаты на снимке тех мест где точно изображены наши искомые маски на лицах. Это делает оператор вручную. В результате по каждому снимку получаются два файла: один сам с изображением и второй в формате XML с указанием координат на снимке искомого объекта.
После того, как набор снимков мы подготовили должным образом, мы приступаем к запуску на сервере нейросети.
Чтобы использовать готовые библиотеки и не писать программный код с нуля самостоятельно, мы можем выбрать один из двух вариантов. Компания Гугл предоставляет возможность использовать её сервера — с уже предуставновленным программным обеспечением для работы с нейросетями. В этом случае наборы файлов с картинками вы можете положить на свой раздел Гугл диска — и при настройки сети указать логин и путь к этим файлам. Тогда вам ничего никуда больше копировать не придётся, Гугл сам найдёт на своих серверах нужные ресурсы, и подключит их в работу. Но в этом случае могут возникать независимые от вас ограничения в использовании процессорного времени на серверах, поэтому мы предпочитаем использовать собственные сервера, в частности, на российской платформе Alt Liux p9. В этой ОС мы легко настраиваем окружение необходимых библиотек самостоятельно. Alt Liux p9 нам даёт возможность не быть привязанным к условиям компании Гугл, которые при большой загрузке могут начать снижать производительность работы ваших приложений. На своих серверах вы полностью может распоряжаться вашими ресурсами как вам будет нужно.
Для начал работ по развёртыванию сети необходимо подготовиться и ответить на несколько вопросов:
- Какой производительности сервер необходим?
- Какой язык планируется использоваться для работы с нейросетью?
- Какие библиотеки понадобятся для работы?
Основные вычисления производятся, как правило, на CPU сервера, но бывают и такие расчёты, которые можно осуществлять на видео картах — GPU.
Если предполагается осуществлять расчёты на CPU, то обязательно в нём должна быть инструкция AVX, наличие которой мы легко обнаружим следующей командой
$cat /proc/cpuinfo | grep avx
Для работы нейросети как правило используют язык высокого уровня Python, поскольку очень много различных разработок уже реализованы на этом языке. И достаточно много библиотек имеется в свободном доступе на GitHub.com. Библиотеки от Гугл, которые могут быть использованы для этих целей это: и
Для использования различного окружения можно использовать среду — это инструмент для управления пакетами и установщик с куда большим функционалом, чем в pip. Conda может обрабатывать зависимости библиотек вне пакетов Python, а также сами пакеты Python.
[woronin1-img004] [woronin1-img005]

!.jpg)
Примечания и ссылки
Plays:5 Comments:0