Проект технологии извлечения знаний из исходных текстов на языках С++ и Csharp с использованием общего промежуточного представления
Материал из 0x1.tv
Аннотация
- Докладчик
- Алексей Пустыгин


Использование высокоуровневого промежуточного представления часто может оказаться полезным в процессе автоматического извлечения знаний из исходных текстов программ. Особенно это заметно, когда необходимо анализировать исходные тексты на нескольких языках программирования, поскольку формат такого представления может быть расширен для описания нескольких языков. Это упрощает процесс создания утилит для автоматического извлечения знаний из исходных текстов.
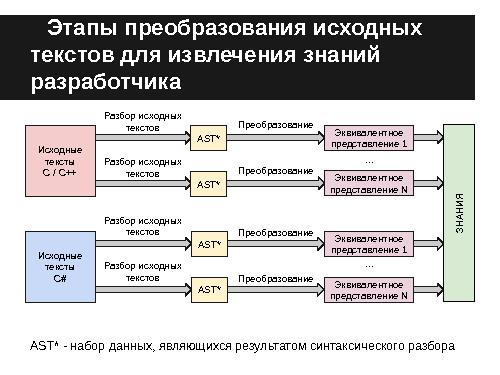
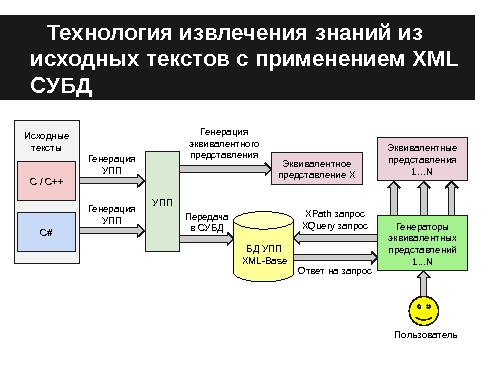
Извлечение знаний из исходных кодов программ является задачей обработки текстов. Для её решения нужен набор программных инструментов для каждого типа анализа или получения эквивалентных представлений. Поскольку в каждом случае осуществляется разбор исходного текста, данную функцию целесообразно выделить в самостоятельный функционал — генератор промежуточного представления.
В случае анализа гетерогенных исходных текстов, то есть текстов на нескольких языках программирования, задача становится еще сложнее.
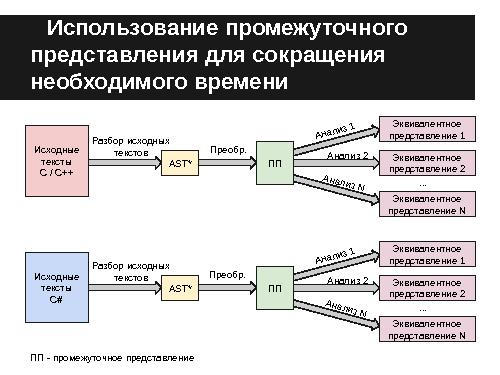
Простейшим решением данной проблемы является создание генераторов промежуточного представления, специфичных для каждого языка, однако, данный подход не является эффективным. Это связано с тем, что создание таких инструментов — сама по себе трудоёмкая задача.
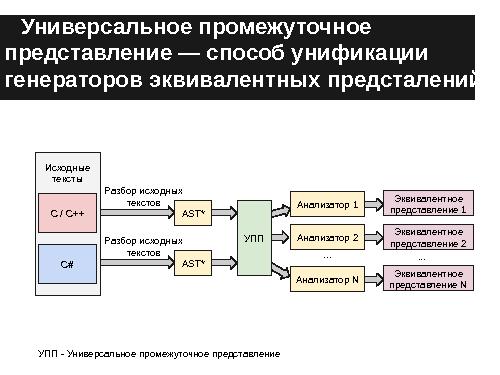
В предыдущих работах [2] предлагалось решение этой проблемы путём введения единого универсального промежуточного представления исходных текстов на различных ЯП.
Для извлечения информации из исходных текстов на ЯП C, C++, C# были поставлены задачи:
- 1. Предложить формат для построения промежуточного представления гетерогенных текстов на C, C++ и C#.
- 2. Спроектировать инструменты для получения такого представления.
Видео
Посмотрели доклад? Понравился? Напишите комментарий! Не согласны? Тем более напишите.
Слайды




















Расширенные тезисы
Формат промежуточного представления должен отвечать некоторому набору критериев, среди них можно выделить:
- 1. Простота реализации инструментов для автоматической обработки,
- 2. Расширяемость — простота добавления новых языковых конструкций,
- 3. Читабельность — удобство восприятния человеком.
Среди распространённых форматов представления структурированных данных этому набору критериев удовлетворяют XML[1], JSON[2] и YAML[3].
Стек технологий XML предоставляет инструменты, которые можно использовать для решения задачи извлечения знаний из исходных текстов программ путём обработки их промежуточного представления. Из них можно выделить следующие:
- 1. XPath[4] — язык запросов для выборки и навигации по узлам XML документа, вычисления некоторых его метрик, что позволяет эффективно его использовать для задачи извлечения знаний. Является стандартом консорциума W3C.
- 2. XQuery[5] — функциональный язык запросов, разработанный для выполнения запросов и трансформации коллекций структурированных и неструктурированных данных. Является официальной рекомендацией W3C.
- 3. XSLT[6] — язык для трансформации XML документов в другие XML документы, объекты HTML или XSL, которые затем могут быть преобразованы в PDF, PostScript, SVG или PNG. Т.е. позволяет получить, например, визуальное эквивалентное представление, пригодное для анализа. Является официальной
рекомендацией W3C.
- 4. XML-базы данных, например, Sedna[7] (лицензия Apache License 2.0) или BaseX (лицензия BSD)[8], которые можно использовать в качестве единого хранилища знаний об исходного коде
одного или нескольких проектов.
Таким образом, выбор формата XML как основы для промежуточного представления позволяет сократить затраты на создание инструментов анализа и построения эквивалентных представлений.
JSON и YAML, в свою очередь не обеспечивают возможностей XML, в силу отсутствия для них подобного инструментария.
Для получения промежуточного представления исходного кода предполагается использовать абстрактное синтаксическое дерево (AST)[9], дополненное семантической информацией. Среди существу- ющих форматов представления в контексте задачи извлечения знаний можно выделить следующие:
- SrcML (Source Markup Language)[10] — открытое документоориентированное представление исходных текстов, поддерживающее языки C, C++ (CppML), Java (JavaML), частично C# (SrcML.Net).
Основным его недостатком является отсутствие важных атрибутов в узлах AST, что не позволяет проводить полный анализ кода.
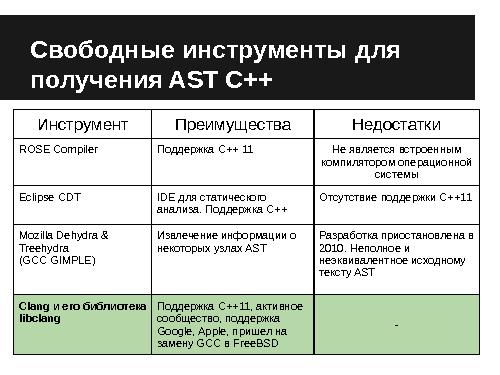
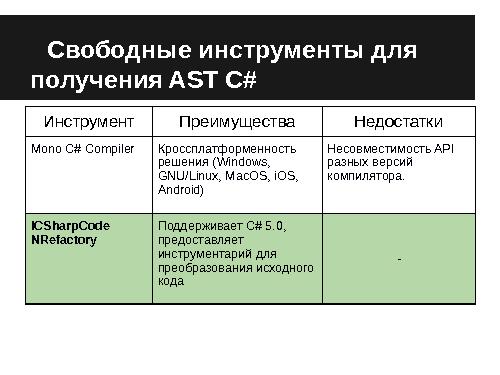
- Специфические для языков представления, такие как GCC-XML[11] (основанное на внутреннем представлении компилятора GCC), cpp2xml[12], не обладающие свойством универсальности. Для поиска возможных альтернативных решений был произведен поиск инструментов для получения AST. В таблице 1 приведен их обзор.
Главным требованием к формату промежуточного представления было включение в состав атрибутов узлов такого набора тегов, который позволяет удовлетворить требованиям спецификации языков при разборе всех синтаксических конструкций, описанных в стандартах. Источниками для создания формата промежуточного представления послужили следующие документы:
Для генерации промежуточного представления по C++ и C# по спроектированному формату были выбраны следующие инструменты, удовлетворяющие заданным критериям (полнота, актуальность инструмента, предполагаемые затраты на разработку промежуточного представления):
- Clang и его библиотека libclang (для языков C/C++), которые обеспечивают поддержку С++11, Objective-C, поддерживаются активным сообществом, крупными компанями (например Apple, Google), включают SDK и отдельную библиотеку для получения AST.
Библиотека libclang — неотъемлемая часть инструментария clang, которая ппрпедназначена для статического анализа и автозавершения кода и. используется в IDE Xcode от Apple.
- ICSharpCode.NRefactory[15]. (для языка C#) — библиотека, основанная на исходном коде компилятора Mono, предоставляющая инструментарий для преобразования исходного кода и поддерживает последнюю версию спецификации языка C# 5.0.
В результате проделанной работы был разработан формат универсального промежуточного представления[16] для языков C, C++ и C#, а также составлен эскизный проект технологии извлечения знаний из исходных текстов, использующий данное представление, которое соответствует необходимому набору критериев и может быть расширено для поддержки новых синтаксических конструкций, в том числе других языков.
- См. также
- Зубов М.В. Статический анализ ПО с помощью его промежуточных представлений и технологий с открытым исходным кодом / М.В. Зубов, А.Н. Пустыгин, Е.В. Старцев // Материалы 2-й Междунар. конф. «FOSS. Lviv–2012», Львов. — Львiв: Сорока, 2012. — С. 165–168.
- Crossplatform, open source .NET development framework
- en-US/docs/Dehydra Dehydra.
- Eclipse CDT (C/C++ Development Tooling).
- ROSE compiler infrastructure.
Примечания и отзывы
- ↑ Extensible Markup Language (XML)
- ↑ JSON (JavaScript Object Notation)
- ↑ . YAML: YAML Ain’t Markup Language.
- ↑ XML Path Language (XPath). W3C Recommendation, 16 November 1999
- ↑ 1.0: An XML Query Language (Second Edition). W3C Recommendation, 14 December 2010.
- ↑ XSL Transformations (XSLT). W3C Recommendation, 16 November 1999.
- ↑ Fomichev A., Grinev M., Kuznetsov S. Sedna: A Native XML DBMS // SOFSEM 2006: Theory and Practice of Computer Science. Lecture Notes in Computer Science. 2006. Vol. 3831. P 272-281.
- ↑ BaseX. The XML Database
- ↑ А. Ахо, М. Лам, Р. Сети, Д. Ульман. Компиляторы: принципы, технологии и инструментарий. — М.: Вильямс, 2010. — 1184 с.
- ↑ Collard M.L., Kagdi H.H., Maletic, J.I. An XML-Based Lightweight C++ Fact Extractor // Program Comprehension, 2003. 11th IEEE International Workshop. May 10 — 11, 2003. P. 134-143.
- ↑ GCC-XML
- ↑ The C++2XML page
- ↑ C# Language Specification 5.0.
- ↑ Working Draft, Standard for Programming Language C++
- ↑ NRefactory library
- ↑ Формат универсального промежуточного представления
Plays:63 Comments:0