Машинное обучение в электронной коммерции – практика использования и подводные камни (Александр Сербул, SECR-2017) — различия между версиями
Материал из 0x1.tv
StasFomin (обсуждение | вклад) |
StasFomin (обсуждение | вклад) (Batch edit: replace PCRE \{\{youtubelink\|([^\}]*)\}\} with {{youtubelink|\1}}{{letscomment}}) |
||
;{{SpeakerInfo}}: {{Speaker|Александр Сербул}}
<blockquote>
Доклад позволит соориентироваться в плеяде современных алгоритмов машинного обучения в разрезе прикладного использования для электронной коммерции и выбрать необходимые бесплатные библиотеки для реализации задач. Мы поделимся практическим опытом и историями успеха использования данных технологий в продакшн-среде.
Также особое внимание уделим технике использования популярных платформ и библиотек: Apache Spark, Spark MLlib, Hadoop, Amazon Kinesis, deeplearning4j. Отдельно остановимся на особенностях обработки “больших данных”, выборе и разработке параллельных алгоритмов для ML.
</blockquote>
{{VideoSection}}
{{vimeoembed|240325309|800|450}}
{{youtubelink|PGaNt8qcvvg}}{{letscomment}}
{{SlidesSection}}
[[File:Машинное обучение в электронной коммерции – практика использования и подводные камни (Александр Сербул, SECR-2017).pdf|left|page=-|300px]]
{{----}}
[[File:{{#setmainimage:Машинное обучение в электронной коммерции – практика использования и подводные камни (Александр Сербул, SECR-2017)!.jpg}}|center|640px]]
{{LinksSection}}
* [http://2017.secr.ru/program/submitted-presentations/machine-learning-in-e-commerce Страничка доклада на сайте конференции]
<!-- <blockquote>[©]</blockquote> --> | |||
Версия 16:42, 19 октября 2018
- Докладчик
- Александр Сербул


Доклад позволит соориентироваться в плеяде современных алгоритмов машинного обучения в разрезе прикладного использования для электронной коммерции и выбрать необходимые бесплатные библиотеки для реализации задач. Мы поделимся практическим опытом и историями успеха использования данных технологий в продакшн-среде.
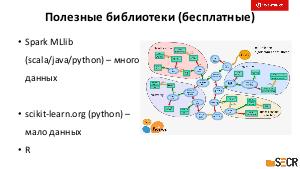
Также особое внимание уделим технике использования популярных платформ и библиотек: Apache Spark, Spark MLlib, Hadoop, Amazon Kinesis, deeplearning4j. Отдельно остановимся на особенностях обработки “больших данных”, выборе и разработке параллельных алгоритмов для ML.
Видео
Посмотрели доклад? Понравился? Напишите комментарий! Не согласны? Тем более напишите.
Презентация
























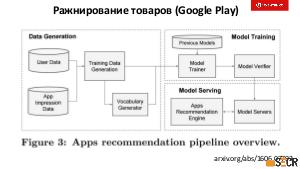
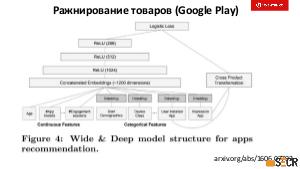


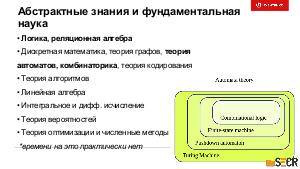



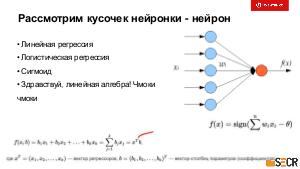


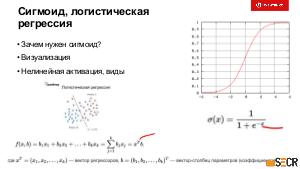
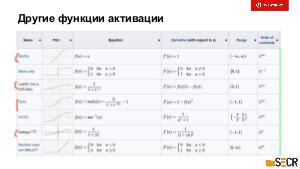
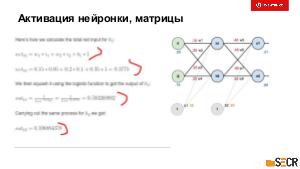

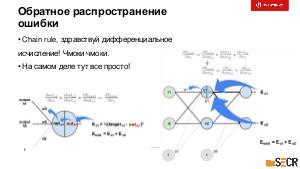




























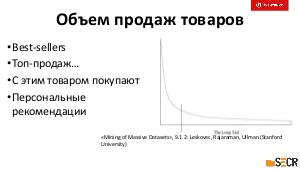

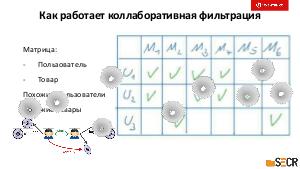




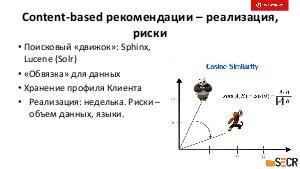






















!.jpg)
Примечания и ссылки
Plays:240
Comments:0