Применение онтологического подхода для анализа текстов в облачном контент-репозитории C2R (Алексей Костарев, OSEDUCONF-2014) — различия между версиями
Материал из 0x1.tv
StasFomin (обсуждение | вклад) |
StasFomin (обсуждение | вклад) (→Видео) |
||
== Видео ==
{{vimeoembed|86260097|800|450}}
{{youtubelink|tHAx3qy3n4I}}
<!-- {{webm-oseduconf|}} -->
<poll>
ALTERNATIVE
REVOTE
UNIQUE
Оцените доклад «{{PAGENAME}}»:
Отлично!
Хорошо.
Нормально…
Не очень :(
Просто хочу узнать результаты.
</poll>
== Слайды == | |||
Версия 13:08, 1 ноября 2014
Содержание
Аннотация
- Докладчик
- Алексей Костарев


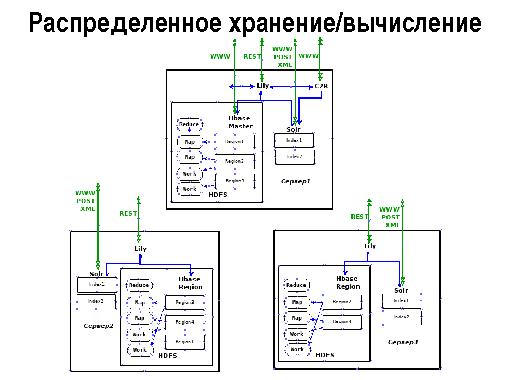
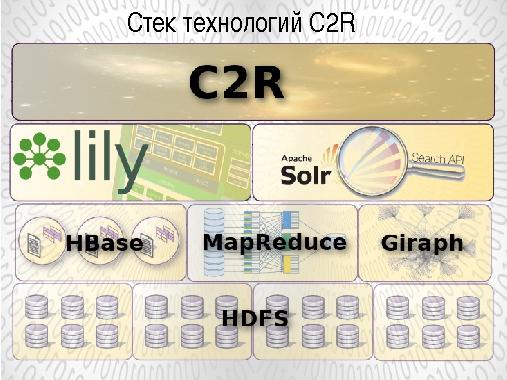
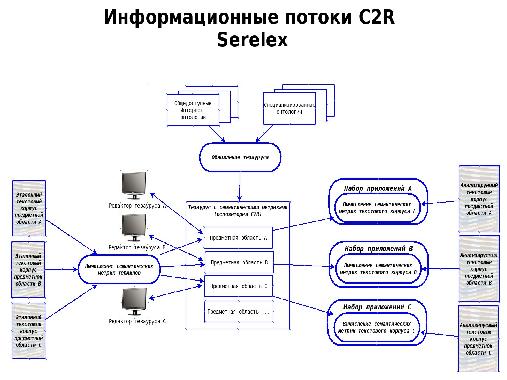
В докладе обсуждаются основные концепции применения онтологического подхода для анализа текстов в рамках совместных работ ГК ИВС (группы компаний ИВС) и ПГНИУ (Пермский Государственный Научно-Исследовательский Университет). В качестве хранилища текстов и онтологий используется репозиторий C2R, функционирующий в кластере Apache Hadoop и использующий облачные программные продукты HDFS, HBase, Lily, Solr под свободными лицензиями.
Создание и ведение онтологий обеспечивается на основе данных Википедии и тематических текстовых корпусов с применением алгоритмов семантического анализа связности слов Serelex и механизмов логического вывода. Все разрабатываемые алгоритмы планируется реализовать в рамках технологий распределенных вычислений MapReduce и Apache Giraph, что обеспечивает неограниченную масштабируемость созданного решения, возможность хранения и обработки в единой базе онтологий для различных тематических областей, обработку за приемлемое время огромных (сотни петабайт) объемов данных.
Видео
Слайды


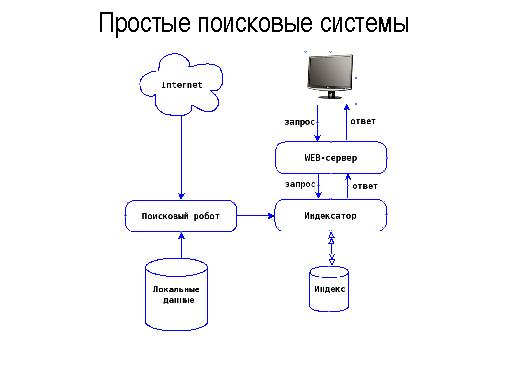
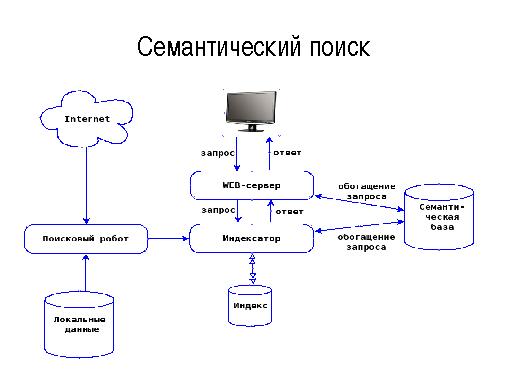
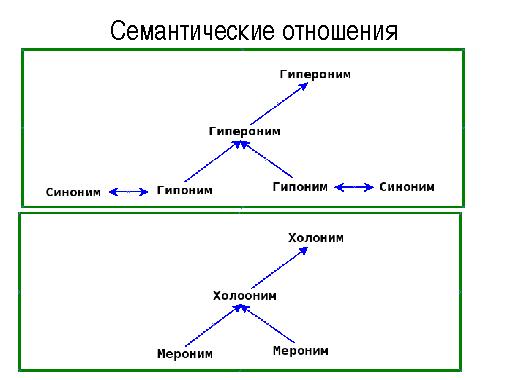
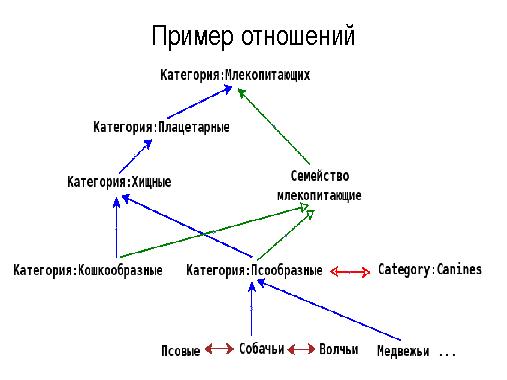



Расширенные тезисы
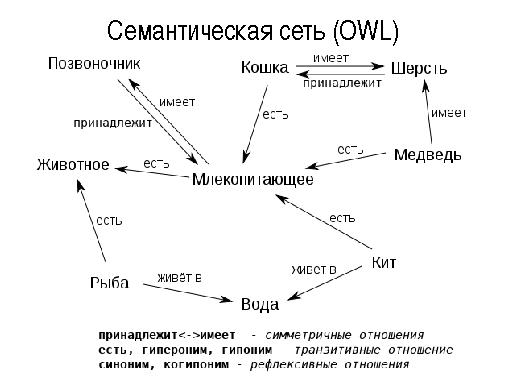
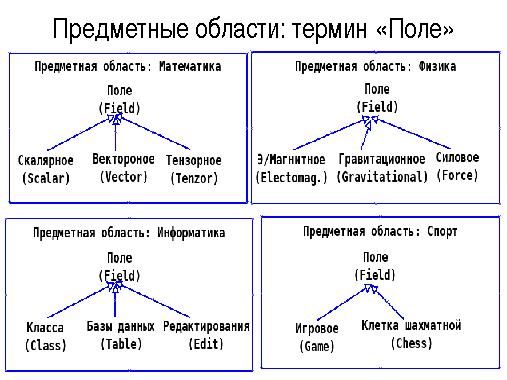
В последнее время для анализа текстов все чаще используют механизмы, позволяющие учитывать семантические аспекты языка — синонимы, гиперогимы, гипонимы, когипонимы и т.д. Это позволяет проводить поиск и анализ текстов не только по значениям кон- кретных слов, но и использовать семантически близкие термины для указанной предметной области. Большое значение в этой связи имеет создание онтологий терминов для различных предметных областей и поддержка их в актуальном состоянии.
Онтологии представляют собой графы различной структуры:
- ориентированные/неориентированные;
- взвешенные/невзвешенные;
- полные/k-полные;
- дерево/лес/сеть/...
- и т. п.
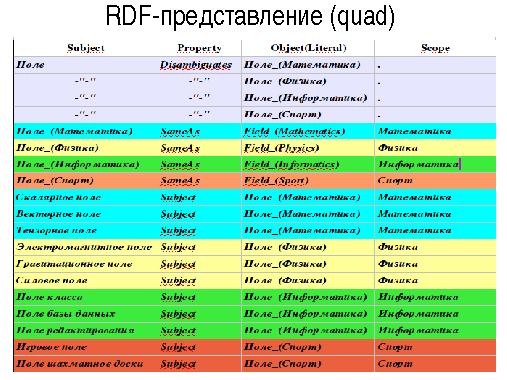
Основная проблема при работе с ними связана как с большим объемом графов онтологии для каждой предметной области, так и с необходимостью поддерживать на одном множестве терминов большое число графов, описывающие различные предметные области. Другая немаловажная проблема связана с большим объемом вычислительных операций и операций ввода вывода, необходимых как для создания и ведения онтологий, так и для анализа входных текстов с использованием семантических отношений, описанных в онтологиях.
Возможное решение этих проблем лежит в применении технологий распределенного хранения и обработки информации, позволяющих использовать всю вычислительную мощность, оперативную и дисковую память кластера для решения этого класса задач.
Репозиторий C2R, разработанный нами в 2010-2012 годах, использует следующие облачные технологии:
- распределенную файловую системы Apache Hadoop HDFS;
- NoSQL базу данных Apache HBase;
- репозиторий Lily;
- индексатор Solr.
Использование данных технологий позволяет организовать облачное распределенное хранение и обработку анализируемых текстов и онтологических данных на кластере серверов Apache Hadoop. Для оперативной (Online) работы с онтологиями используется как прямой доступ к записям HBase по автоматически генерируемому ключу так и по ключу (списку ключей), получаемому в ответ на запрос к индексатору Solr.
Для аналитической работы по созданию и автоматическому ведению онтологий будут использованы алгоритмы распределенной обработки информации:
- Apache Hadoop MapReduce — создание и пополнение онтологий из внешних источников (Википедия, Викисловарь, …)
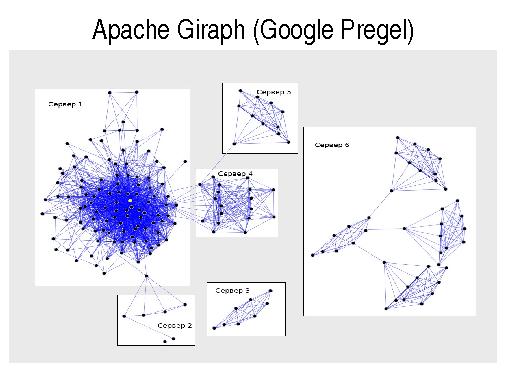
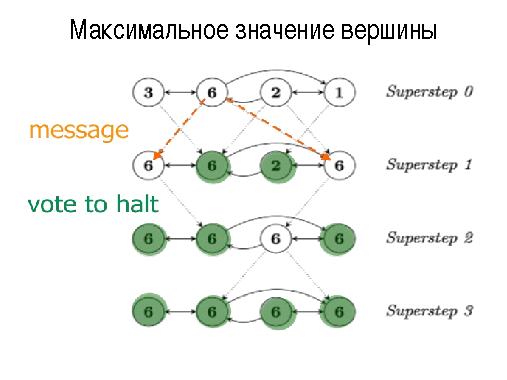
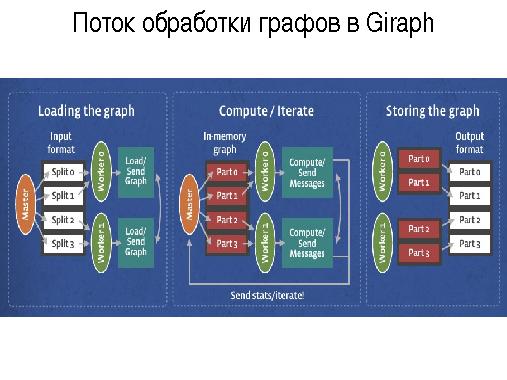
- Apache Giraph (Google Pregel) — обработка распределенных графов для подсчета метрик семантической близости, получения новых знаний и т. п.
Применение данных подходов для хранения и обработки онтологий обеспечивает:
- оптимальное высоконадежное хранение онтологических (графовых) данных в распределенной облачной среде;
- неограниченность объема онтологий и анализируемых текстов (до сотен петабайт);
- автоматическое горизонтальное масштабирование базы;
- распределенная обработка данных с использованием всех мощностей кластера;
- возможность хранения в одной базе (таблице) онтологий для неограниченного числа различных тематических областей с их оптимизацией и получения новых данных.
Разрабатываемую программную платформу предполагается использовать для создания следующего класса программных продуктов:
- C2R Archivarius — хранение, обработка и поиск текстовых данных;
- C2R Mailing — мониторинг Интернет- и других Online-ресурсов для обнаружения информации релевантной запросам пользова-
телей.
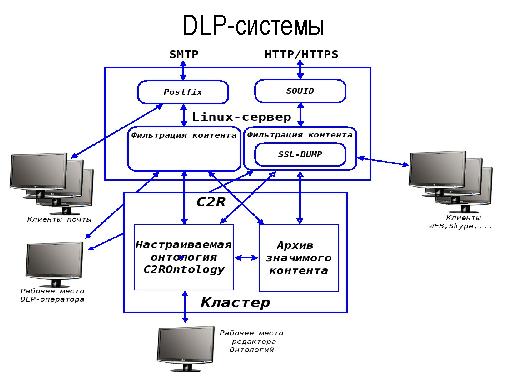
- C2R DLP — создание систем уровня DLP (Data Loss/Leak Prevention) для контроля трафика и предотвращения утечек.
Создание данных систем планируется производить в два этапа: 1. Создание прототипа с поддержкой Online-режима для хранения и анализа текстов без использования онтологий (2-3 квартал 2014 года);
2. Создание на основе прототипа полнофункционального решения с использованием онтологий (3-4 квартал 2014).
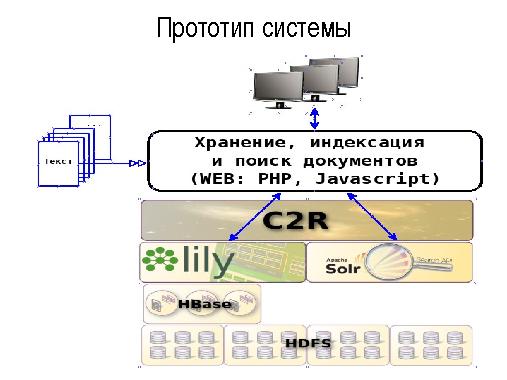
Прототип
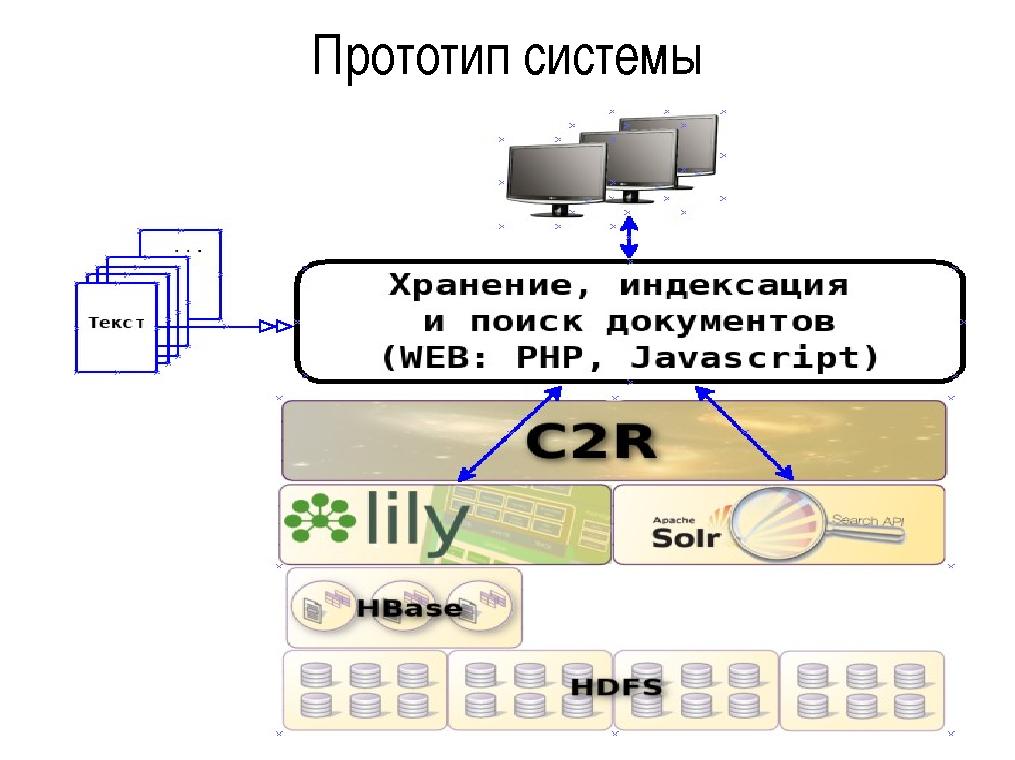
На данном этапе обеспечивается хранение, индексация и поиск документов с использованием стандартных опробован-
ных средств:
- создание и хранение документов — репозиторий Lily;
- индексация и поиск документов — индексатор Solr.
Репозиторий Lily обеспечивает запись, чтение, модификацию, удаление входных документов (CRUD-операции) в нереляционной (NoSQL) базе данных Apache HBase и передачу документов для инкрементальной или полной индексации в поисковую систему Solr. Поисковая система Solr, функционирующая в облачном (Cloud) режиме производит индексацию документов репозитория и обеспечивает быстрый поиск записей по их содержимому.
На основе данных сервисов создаются прототипы описанных выше программных продуктов: C2R Archivarius, C2R Mailing, C2R DLP.
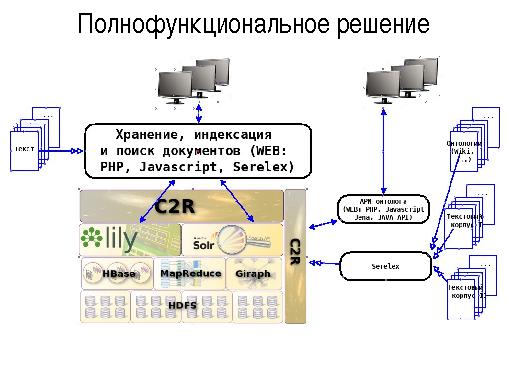
Полнофункциональное решение
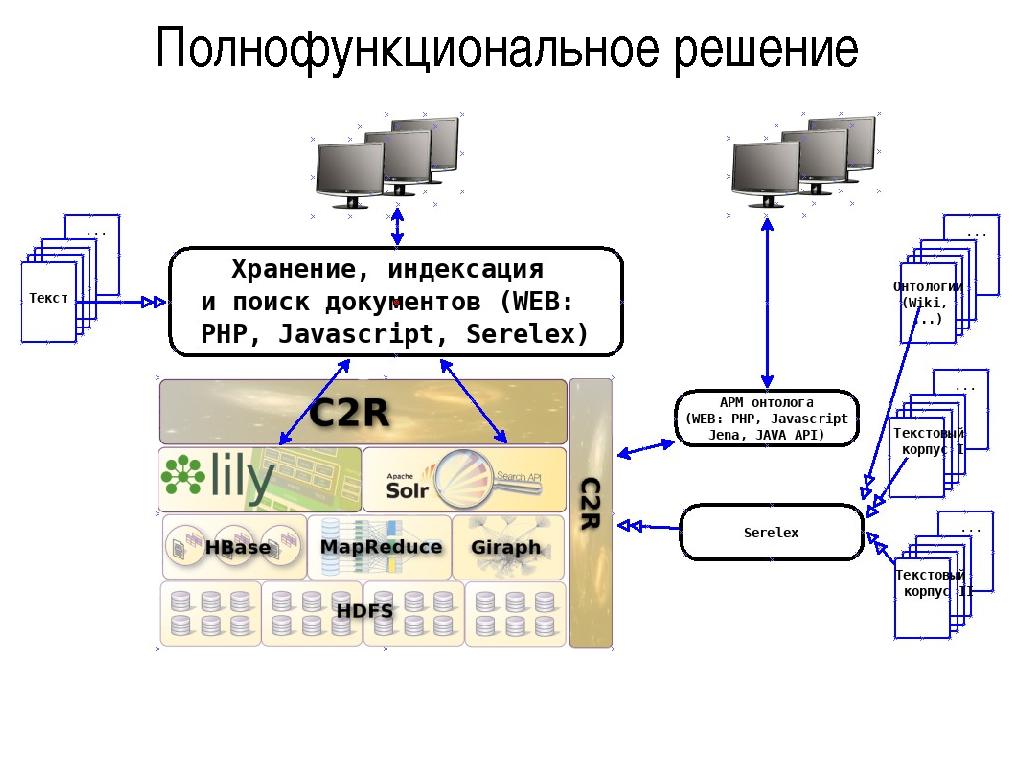
В полнофункциональном режиме репозиторий C2R обеспечивает кроме хранения и обработки входных анализируемых документов, хранение, пополнение и обогащения онтологических данных, используемых для улучшения качества поиска и более тонкой настройки систем на предметные области клиентов. Для создания, обновления онтологий планируется использовать существующие онтологии (Википедия, Wordnet, …), тематические текстовые корпуса. АРМ онтолога обеспечивает тонкую настройку онтологий на предметные области клиентов и формирование новых знаний по хранимым онтологиям с использованием WEB интерфейса, Java-framework Jena и других инструментариев.
Для вычисления семантических расстояний между терминами (source) онтологий и вычислений метрик соответствия анализируемых входных текстов планируется использовать алгоритмы инструментария Serelex, реализованные в среде распределенных вычислений по технологиям Apache MapReduce и Apache Giraph.
- Литература
- [1] Костарев А.Ф., Полещук А.Н, Контент-репозиорий C2R. Свидетельство о государственной регистрации программы для ЭВМ №2011617248/, 2011
- [2] Чуприна С.И., Трансформация традиционных информационных систем административного типа в интеллектуальные информационные системы на базе онтологий/, 2011
- [3] Костарев А.Ф., Полещук А.Н., Разработка свободно распространяемого контент-репозитория для развёртывания информационных систем на принципах «облачных» вычислений, 2012
- [4] Панченко A., Романов П., Романов А., Филиппович А., Филиппович Ю., Серелекс: поиск и визуализация семантически связанных слов., 2013
- [5] Alexander Panchenko, Similarity Measures for Semantic Relation Extraction, 2013