Переходя все границы... (Алексей Баранцев, SQADays-11) — различия между версиями
Материал из 0x1.tv
StasFomin (обсуждение | вклад) (Batch edit: replace <!-- {{youtubelink|}} --> with {{youtubelink|}}) |
StasFomin (обсуждение | вклад) (→Видео) |
||
== Видео ==
{{vimeoembed|42284184|800|376}}
{{youtubelink|}}|mfG_NEA0JKs}}
== Слайды ==
[[Файл:Переходя все границы... (Алексей Баранцев, SQADays-11).pdf|left|page=-|256px]]
{{----}}
== Примечания и отзывы ==
<!-- <blockquote>[©]</blockquote> -->
<references/>
[[Категория:Тестирование]]
[[Категория:SQADays-11]] | |||
Версия 11:57, 4 ноября 2015
Содержание
Аннотация
- Докладчик
- Алексей Баранцев [1]


Анализ границ — эту технику каждый тестировщик осваивает, наверное, самой первой. Прочитать спецификацию, отделить «хорошие» данные от «плохих», сделать тесты для тех и для других, а также проверить границы. Выделить классы эквивалетности, взять по одному представителю из каждого, а также проверить границы. Это знакомо каждому тестировщику.
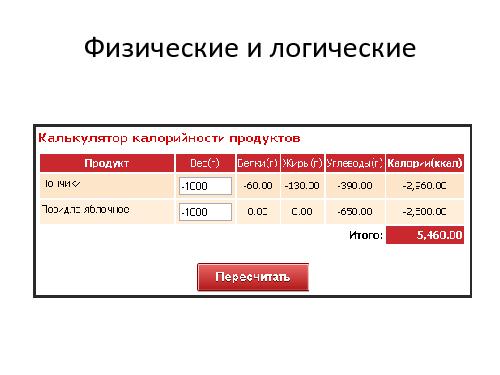
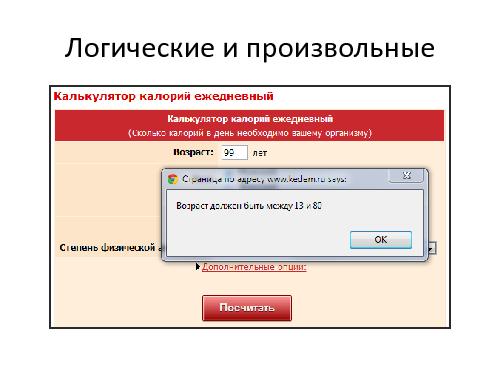
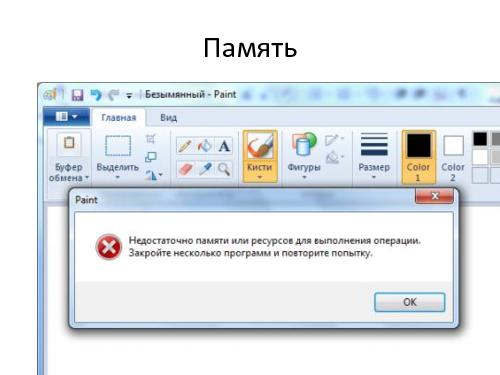
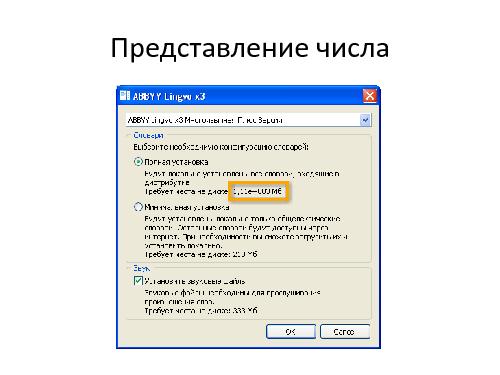
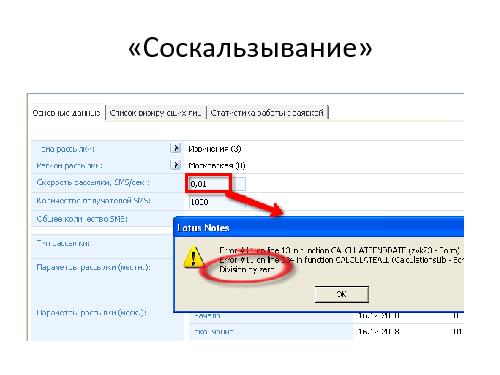
Но в действительности применение этой техники вовсе не так просто, как может показаться на первый взгляд, потому что в реальном мире разных «границ» куда больше, чем описано в любой, даже самой хорошей спецификации. Причина этого в том, что в реальной программе существует множество *технологических* границ, о которых аналитик может даже не подозревать. Это максимальные и минимальные числа в различных представлениях, максимальные допустимые размеры строк или полей в базе данных, максимальная и минимальная представимая дата, точность вычислений и другие ограничения. Иногда они возникают из-за особенностей реализации — алгоритмов или архитектурных решений, которые выбрали ваши разработчики. Иногда они определяются внешними используемыми библиотеками и платформой (программной и/или аппаратной), на которой реализована ваша программа.
Что будет, если пользователь, случайно или намеренно, пересечёт такую *технологическую* границу — введёт слишком большое число или слишком длинную строку? Должен ли тестировщик пытаться это выяснить? Или может быть достаточно предупредить пользователей, чтобы они не вводили «плохие» данные, а кто ввёл — мы ответственности не несём? А если всё таки мы решили, что тестировщику следует пытаться всё это проверить — как искать эти границы, если они нигде не описаны? И можно ли попасть в область, находящуюся «за технологической границей»? А если можно — нет ли там, дальше, ещё каких-нибудь границ? Как далеко это может завести тестировщика?
Я расскажу свою точку зрения на применение этой техники, приведу примеры реальных багов, связанных с нарушением *технологических* границ, подскажу некоторые приемы, которые позволяют их обнаруживать, и дам рекомендации, когда этого можно не делать.
Видео
Слайды