Adept — исследовательская и образовательная платформа машинного обучения (Кирилл Колодяжный, OSSDEVCONF-2025) — различия между версиями
Материал из 0x1.tv
StasFomin (обсуждение | вклад) (Новая страница: «;{{SpeakerInfo}}: {{Speaker|Кирилл Колодяжный}} <blockquote> </blockquote> Adept — исследовательская и образовател…») |
StasFomin (обсуждение | вклад) |
||
;{{SpeakerInfo}}: {{Speaker|Кирилл Колодяжный}}
<blockquote>
Adept (Automatic Differentiation Engine for Tensor Processing) — исследовательский и образовательный проект по разработке платформы для обучения моделей машинного обучения.
Проект используется для демонстрации архитектуры и основных элементов платформ машинного обучения, методик интеграции вычислительных ядер, построения вычислительных графов и т. д., а также служит основой для разработки экспериментальных конвейеров обучения с использованием кроссплатформенных API Vulkan и OpenCL.
</blockquote>
Adept — исследовательская и образовательная платформа машинного обучения (Кирилл Колодяжный, OSSDEVCONF-2025)
{{VideoSection}}
{{vimeoembed||800|450}}
{{youtubelink|}}
{{SlidesSection}}
[[File:Adept — исследовательская и образовательная платформа машинного обучения (Кирилл Колодяжный, OSSDEVCONF-2025).pdf|left|page=-|300px]]
{{----}}
== Thesis ==
Ключевые слова: машинное обучение, искусственный интеллект, нейронные сети, образование, C++, Python, GPU, Vulkan.
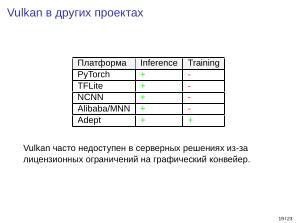
В отечественном сегменте инструментов для работы с машинным обучением на данный момент отсутствуют решения общего назначения, аналогичные PyTorch или TensorFlow. Это частично связано с дефицитом специалистов широкого профиля, разбирающихся как в разработке высоконагруженных вычислительных систем, так и в теории и практике машинного обучения.
Проект предполагает создание экспериментальной платформы машинного обучения для наработки опыта создания систем такого рода и включает исследовательское и образовательное направления.
=== Общая информация ===
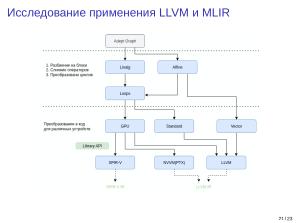
В проекте на текущий момент реализована базовая архитектура платформы машинного обучения. Реализованы вычислительные ядра для большинства CPU-архитектур (x86_64, Arm, RISC-V) с использованием SIMD-расширений, а также конвейер выполнения и вычислительные ядра для API Vulkan, что обеспечивает поддержку GPU различных производителей. На данном этапе вычислительные ядра реализованы субоптимально.
Поддерживается базовый набор модулей для обучения многослойных свёрточных нейронных сетей, работа с несколькими GPU, параллельная загрузка и предобработка данных. Программный интерфейс проекта включает реализации на языках Python и C++.
Технические сведения о проекте приведены ниже.
{| class="wikitable"
|-
! Параметр !! Значение
|-
| Пользовательский API || Python; C++
|-
| Установка || GitVerse PyPI; исходный код
|-
| Система сборки || CMake; gcc 12; Python 3.10; Vulkan SDK
|-
| Языки реализации || Python; C++; GLSL
|}
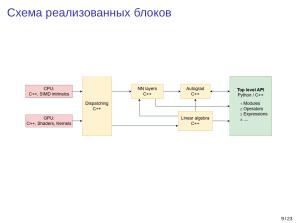
В проекте реализована поддержка интеграции различных вычислительных ядер и платформ в виде модуля диспетчеризации с интерфейсом регистрации вызовов. Построение вычислительного графа основано на жадном (Eager) императивном подходе, используется динамический вычислительный граф.
Реализованная на данный момент функциональность для построения и обучения моделей машинного обучения приведена ниже.
{| class="wikitable"
|-
! Функции активации !! Оптимизаторы !! Функции потерь !! Слои
|-
| Sigmoid; SiLU; LeakyReLU; ReLU || SGD; Adam || MSE; CrossEntropy || Linear; Conv2d; AvgPool2d; MaxPool2d; BatchNorm2d
|}
Для многопоточной загрузки и обработки данных реализован механизм передачи тензоров через разделяемую память. Это позволяет реализовать распределённое обучение моделей в рамках нескольких процессов ОС, работающих с несколькими вычислительными устройствами.
=== Образовательное направление ===
Как образовательная платформа проект может использоваться для обучения студентов архитектуре платформ машинного обучения, включая следующие аспекты:
* основные архитектурные блоки платформ машинного обучения;
* уровни абстракции;
* взаимодействие разных языков программирования;
* реализация математических абстракций;
* методы автоматического дифференцирования;
* работа и оптимизация вычислительного графа;
* разработка вычислительных ядер;
* кроссплатформенная разработка ПО;
* работа со специализированным оборудованием;
* реализация распространённых модулей для моделей машинного обучения.
Код проекта может использоваться как наглядная демонстрационная база, основа для студенческих проектов, а также для примеров в образовательных статьях, докладах и лекциях.
=== Исследовательское направление ===
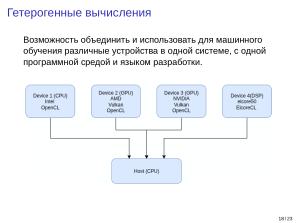
Исследовательское направление включает разработку оптимизированных вычислительных ядер с использованием API Vulkan и OpenCL (CUDA, HIP и др.) для поддержки специализированных аппаратных ускорителей и GPU различных производителей — от серверных до встраиваемых решений, а также исследование и тестирование современных алгоритмов машинного обучения.
=== Результаты ===
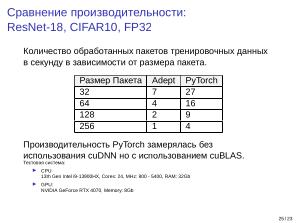
В рамках реализованной функциональности воспроизведены свёрточные нейронные сети архитектуры ResNet с числом слоёв 18, 50, 101 и 152. Выполнена тренировка с подтверждением значений метрики точности для задачи классификации на наборе данных CIFAR-10.
Код проекта используется как демонстрационный материал при разработке курса «Архитектура платформ машинного обучения», запуск которого планируется в одном из вузов в сентябре 2025 г.
Наработки проекта также использовались при подготовке статей и докладов.
=== Планы развития ===
В дальнейшие планы развития проекта входят следующие задачи:
* реализация вычислительных ядер с использованием OpenCL для поддержки более широкого круга устройств, включая ASIC;
* поддержка различных типов данных для вычислительных ядер, включая пониженную разрядность;
* реализация вычислительных ядер для других типов нейронных сетей и больших языковых моделей;
* разработка подходов к распределённому обучению с использованием нескольких устройств, включая конвейерный параллелизм и шардирование тензоров;
* исследование архитектур вычислительного графа для динамической и статической оптимизации или компиляции;
* реализация поддержки квантования при обучении и выводе моделей;
* поддержка формата описания моделей ONNX для интеграции с другими системами.
{{----}}
[[File:{{#setmainimage:Adept — исследовательская и образовательная платформа машинного обучения (Кирилл Колодяжный, OSSDEVCONF-2025)!.jpg}}|center|640px]]
{{LinksSection}}
<!-- <blockquote>[©]</blockquote> -->
<references/>
* https://gitverse.ru/kolkir/adept
* K. He, X. Zhang, S. Ren, J. Sun. Deep Residual Learning for Image Recognition, 2015. https://arxiv.org/abs/1512.03385
* A. Krizhevsky. Learning Multiple Layers of Features from Tiny Images, 2009. https://www.cs.toronto.edu/~kriz/cifar.html
* Колодяжный К. Н. Учимся разрабатывать для GPU на примере операции GEMM, 2025. https://habr.com/ru/companies/yadro/articles/934878/
* Колодяжный К. Н. Реализация динамического полиморфизма для свободных функций, 2025. https://rutube.ru/video/b0a2547f75b905a073a847795a6a2869/
* Колодяжный К. Н. Роль C++ в архитектуре современных платформ машинного обучения, 2025. https://cppconf.ru/talks/f9fbddbd85aa409dad5310b64528fceb/
[[Категория:OSSDEVCONF-2025]]
[[Категория:Open-source projects]]
[[Категория:Draft]] | |||
Версия 13:04, 23 января 2026
- Докладчик
- Кирилл Колодяжный


Adept (Automatic Differentiation Engine for Tensor Processing) — исследовательский и образовательный проект по разработке платформы для обучения моделей машинного обучения.
Проект используется для демонстрации архитектуры и основных элементов платформ машинного обучения, методик интеграции вычислительных ядер, построения вычислительных графов и т. д., а также служит основой для разработки экспериментальных конвейеров обучения с использованием кроссплатформенных API Vulkan и OpenCL.
Adept — исследовательская и образовательная платформа машинного обучения (Кирилл Колодяжный, OSSDEVCONF-2025)
Содержание
Видео
Презентация












































Thesis
Ключевые слова: машинное обучение, искусственный интеллект, нейронные сети, образование, C++, Python, GPU, Vulkan.
В отечественном сегменте инструментов для работы с машинным обучением на данный момент отсутствуют решения общего назначения, аналогичные PyTorch или TensorFlow. Это частично связано с дефицитом специалистов широкого профиля, разбирающихся как в разработке высоконагруженных вычислительных систем, так и в теории и практике машинного обучения.
Проект предполагает создание экспериментальной платформы машинного обучения для наработки опыта создания систем такого рода и включает исследовательское и образовательное направления.
Общая информация
В проекте на текущий момент реализована базовая архитектура платформы машинного обучения. Реализованы вычислительные ядра для большинства CPU-архитектур (x86_64, Arm, RISC-V) с использованием SIMD-расширений, а также конвейер выполнения и вычислительные ядра для API Vulkan, что обеспечивает поддержку GPU различных производителей. На данном этапе вычислительные ядра реализованы субоптимально.
Поддерживается базовый набор модулей для обучения многослойных свёрточных нейронных сетей, работа с несколькими GPU, параллельная загрузка и предобработка данных. Программный интерфейс проекта включает реализации на языках Python и C++.
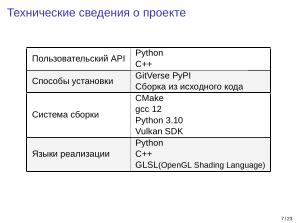
Технические сведения о проекте приведены ниже.
| Параметр | Значение |
|---|---|
| Пользовательский API | Python; C++ |
| Установка | GitVerse PyPI; исходный код |
| Система сборки | CMake; gcc 12; Python 3.10; Vulkan SDK |
| Языки реализации | Python; C++; GLSL |
В проекте реализована поддержка интеграции различных вычислительных ядер и платформ в виде модуля диспетчеризации с интерфейсом регистрации вызовов. Построение вычислительного графа основано на жадном (Eager) императивном подходе, используется динамический вычислительный граф.
Реализованная на данный момент функциональность для построения и обучения моделей машинного обучения приведена ниже.
| Функции активации | Оптимизаторы | Функции потерь | Слои |
|---|---|---|---|
| Sigmoid; SiLU; LeakyReLU; ReLU | SGD; Adam | MSE; CrossEntropy | Linear; Conv2d; AvgPool2d; MaxPool2d; BatchNorm2d |
Для многопоточной загрузки и обработки данных реализован механизм передачи тензоров через разделяемую память. Это позволяет реализовать распределённое обучение моделей в рамках нескольких процессов ОС, работающих с несколькими вычислительными устройствами.
Образовательное направление
Как образовательная платформа проект может использоваться для обучения студентов архитектуре платформ машинного обучения, включая следующие аспекты:
- основные архитектурные блоки платформ машинного обучения;
- уровни абстракции;
- взаимодействие разных языков программирования;
- реализация математических абстракций;
- методы автоматического дифференцирования;
- работа и оптимизация вычислительного графа;
- разработка вычислительных ядер;
- кроссплатформенная разработка ПО;
- работа со специализированным оборудованием;
- реализация распространённых модулей для моделей машинного обучения.
Код проекта может использоваться как наглядная демонстрационная база, основа для студенческих проектов, а также для примеров в образовательных статьях, докладах и лекциях.
Исследовательское направление
Исследовательское направление включает разработку оптимизированных вычислительных ядер с использованием API Vulkan и OpenCL (CUDA, HIP и др.) для поддержки специализированных аппаратных ускорителей и GPU различных производителей — от серверных до встраиваемых решений, а также исследование и тестирование современных алгоритмов машинного обучения.
Результаты
В рамках реализованной функциональности воспроизведены свёрточные нейронные сети архитектуры ResNet с числом слоёв 18, 50, 101 и 152. Выполнена тренировка с подтверждением значений метрики точности для задачи классификации на наборе данных CIFAR-10.
Код проекта используется как демонстрационный материал при разработке курса «Архитектура платформ машинного обучения», запуск которого планируется в одном из вузов в сентябре 2025 г.
Наработки проекта также использовались при подготовке статей и докладов.
Планы развития
В дальнейшие планы развития проекта входят следующие задачи:
- реализация вычислительных ядер с использованием OpenCL для поддержки более широкого круга устройств, включая ASIC;
- поддержка различных типов данных для вычислительных ядер, включая пониженную разрядность;
- реализация вычислительных ядер для других типов нейронных сетей и больших языковых моделей;
- разработка подходов к распределённому обучению с использованием нескольких устройств, включая конвейерный параллелизм и шардирование тензоров;
- исследование архитектур вычислительного графа для динамической и статической оптимизации или компиляции;
- реализация поддержки квантования при обучении и выводе моделей;
- поддержка формата описания моделей ONNX для интеграции с другими системами.
!.jpg)
Примечания и ссылки
- https://gitverse.ru/kolkir/adept
- K. He, X. Zhang, S. Ren, J. Sun. Deep Residual Learning for Image Recognition, 2015. https://arxiv.org/abs/1512.03385
- A. Krizhevsky. Learning Multiple Layers of Features from Tiny Images, 2009. https://www.cs.toronto.edu/~kriz/cifar.html
- Колодяжный К. Н. Учимся разрабатывать для GPU на примере операции GEMM, 2025. https://habr.com/ru/companies/yadro/articles/934878/
- Колодяжный К. Н. Реализация динамического полиморфизма для свободных функций, 2025. https://rutube.ru/video/b0a2547f75b905a073a847795a6a2869/
- Колодяжный К. Н. Роль C++ в архитектуре современных платформ машинного обучения, 2025. https://cppconf.ru/talks/f9fbddbd85aa409dad5310b64528fceb/