Проектирование и реализация решений интеллектуального анализа BigData с использованием Apache Spark и методов онтологического инжиниринга — различия между версиями
Материал из 0x1.tv
StasFomin (обсуждение | вклад) |
StasFomin (обсуждение | вклад) (Batch edit: replace PCRE (\n\n)+(\n) with \2) |
||
== Видео ==
{{vimeoembed|118003790|800|450}}
{{youtubelink|DY3zh_bzi3Y}}{{letscomment}}
{{oseduconf-2015-draft}}
<!-- pollholder -->
== Слайды ==;Литература:
* Русаков C. В., Хеннер Е. К., Чуприна С. И. Интеграция базовой университетской подготовки специалистов по информатике и информационным технологиям // Университетское управление: практика и анализ, № 3, 2014. С. 119–125.
* Костарев А. Ф., Полещук А. Н., Разработка свободно распространяемого контент-репозитория для развёртывания информационных систем на принципах облачных вычислений, 2012
* Spark: Cluster Computing with Working Sets. Matei Zaharia, Mosharaf Chowdhury, Michael J. Franklin, Scott Shenker, Ion Stoica. HotCloud 2010.
* Официальный сайт Apache Spark. https://spark.apache.org/
* Spark News Spark wins Daytona Gray Sort 100TB Benchmark. https://spark.apache.org/news/spark-wins-daytona-gray-sort-100tb-benchmark.html
* Paco Nathan How Apache Spark fits in the Big Data landscape. http://www.slideshare.net/pacoid/how-spark-fits-into-the-big-data-landscape
* M. Тим Джонс Spark, альтернатива для быстрого анализа данных. http://www.ibm.com/developerworks/ru/library/os-spark/
{{----}}
== Примечания и отзывы ==
<!-- <blockquote>[©]</blockquote> -->
<references/>
[[Category:OSEDUCONF-2015]]
[[Category:Образование]]
[[Category:Open-source projects]]
<!-- topub -->
{{stats|disqus_comments=0|refresh_time=2021-08-31T18:06:31.722894|vimeo_comments=0|vimeo_plays=99|youtube_comments=0|youtube_plays=76}} | |||
Версия 12:22, 4 сентября 2021
Содержание
Аннотация
- «Проектирование и реализация решений интеллектуального анализа BigData с использованием стека технологий Apache Spark и методов онтологического инжиниринга»
- Докладчик
- Игорь Постаногов
Представлен краткий отчёт о преподавании курса по обработке больших объемов данных на 2 курсе магистратуры специальности «математическое и программное обеспечение вычислительных систем» для решения задач онтологического инжиниринга. Для демонстрации современного уровня возможностей по обработке BigData предложено использовать платформу Apache Spark. Рассмотрены основные компоненты платформы, их преимущества и простота совместного использования. Преподавание курса также позволило восполнить пробел магистрантов в знаниях в части функционального программирования. Рассмотрен компонент Apache Spark GraphX как средство поддержки разрабатываемой системы, основанной на методах онтологического инжиниринга.
Видео
Посмотрели доклад? Понравился? Напишите комментарий! Не согласны? Тем более напишите.
Слайды

























Тезисы
Согласно «циклу зрелости технологий» компании Gartner от июля 2014 года, концепция BigData перешагнула «пик чрезмерных ожиданий», а область Data Science крайне близка к его вершине. В ближайшие годы ожидается усиление уже сформировавшийся нехватки кадров, разбирающихся в задачах анализа больших данных.
Для того чтобы студенты магистратуры были более востребованы по её окончании и овладели навыками, необходимыми работодателям, с 2013 года в рамках учебной дисциплины «Современные Internet-технологии» введено изучение парадигм анализа больших данных, а также практическое использование существующих их реализаций.
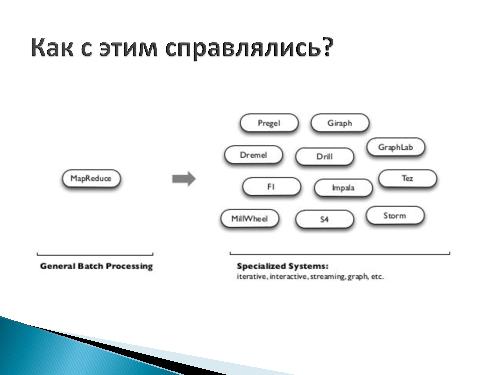
Стоит отметить, что год таких изменений выбран достаточно удачно, поскольку в 2013 году вышла версия Apache Hadoop 2.0, в которой впервые представлен модуль YARN, отвечающий за управление ресурсами кластеров и планирование заданий. Новый планировщик ресурсов — значительный скачок в части расширения множества приложений, которые можно исполнять в рамках указанной платформы. YARN поддерживает множество моделей обработки вдобавок к MapReduce — парадигме, успешно применяемой в большом классе задач, однако имеющей известные проблемы при решении итеративных и интерактивных задач. Для снятия ограничений и сложностей парадигмы, для конкретных типов задач создавались свои фреймворки — Pregel для обработки графов, Twister для итеративных задач и Storm для задач, в которых входные данные поступают в режиме реального времени.
Среди недостатков обходных решений выделяют:
- Необходимость затрат на обучение, поскольку для новой задачи может потребоваться принципиально новый фреймворк.
- Ограничение типов задач, решаемых отдельным фреймворком (например, Dryad и MR Merge не поддерживают циклический поток данных). В то же время, возникают сложности в интеграции при решении задач на стыке возможностей нескольких фреймворков.
- Неадекватность среде вычислений (Twister не отказоустойчив).
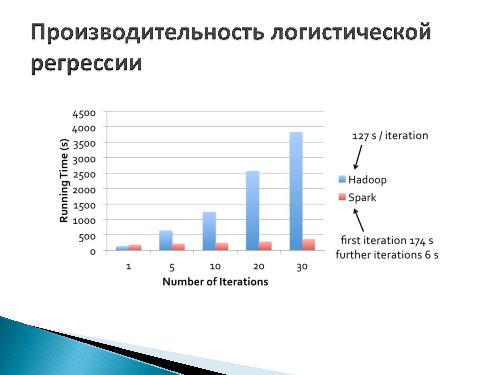
Актуальность задач обработки BigData не обошла стороной и академические круги. AMPLab в UC Berkeley уже в 2009 году начали разрабатывать Spark — новую парадигму вычислений. Её реализация имела десятикратный прирост в скорости в сравнении с MapReduce для задач итеративного машинного обучения (согласно статье 2010 года). Говоря о современных успехах реализации стоит отметить, что осенью 2014 года Spark поставил новый рекорд в Daytona Gray Sort 100TB Benchmark, побив предыдущий рекорд, установленный Hadoop MapReduce, закончив свою работу в 3 раза быстрее и использовав при этом 10 раз меньше вычислительных узлов.
На момент написания статьи, Spark является проектом верхнего уровня Apache и распространяющимся под соответствующей лицензией. Есть сведения об использовании Apache Spark такими компаниями как IBM, SAP, Oracle, DataStax и другими, для решения таких задач как
- In-memory аналитика и поиск аномалий (Conviva)
- Интерактивные запросы к потокам данных (Quatifind)
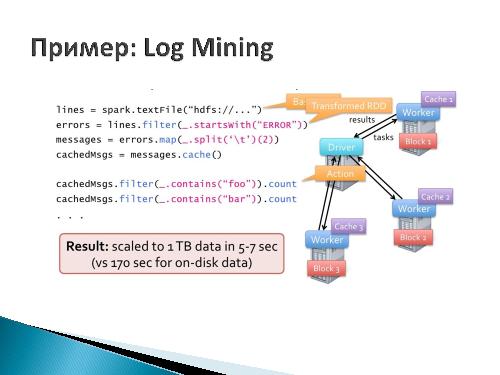
- Анализ логов (Foursquare)
- Оценка загруженности дорог по информации с мобильных GPS (Mobile Millennium)
- Классификация спама в Twitter (Monarch)
Такая популярность Spark’а объясняется отсутствием основного ограничения парадигмы MapReduce — необходимости разбиения задачи на этапы Map и Reduce. Spark решил задачу обеспечения параллелизма и отказоустойчивости, введя концепцию Resilient Distributed Dataset (RDD) — устойчивого распространенного набора данных, являющегося абстракцией распределённой памяти. Отказоустойчивость реализуется сохранением «родословной» для каждого экземпляра RDD, что позволяет восстановить утерянные (например, вследствие отказа одного из вычислительных узлов) его элементы. RDD, по сути, это неизменяемая коллекция элементов, которую можно трансформировать.
В качестве операторов трансформации выступают традиционные для функциональных языков программирования операции map, filter, union, reduce, cartesian и проч.
Возможность их распределённого выполнения гарантируется способностью к сериализации функций под оператором трансформации в существующей реализации Apache Spark на Java-совместимом языке программирования Scala.
Spark предоставляет API для языков программирования Scala, Java & Python, однако именно на Scala его использование выглядит наиболее естественно. Реализация подсчёта слов на Scala с использованием Apache Spark требует лишь кода
spark.textFile("hdfs://...").flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b).
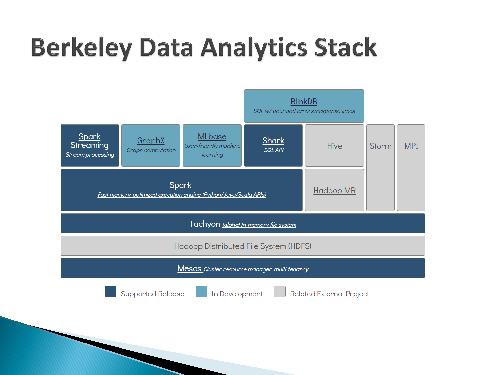
Apache Spark содержит встроенные библиотеки, позволяющие решать различные типы задач:
- Spark SQL, предоставляющий унифицированный доступ к структурированным данным.
- Spark Streaming, содержащий абстракции, позволяющие реализовывать отказоустойчивые приложения обработки данных, поступающих в режиме реального времени.
- MLlib, реализующий алгоритмы машинного обучения.
- GraphX, предоставляющий возможности обработки графов, а также являющийся Pregel-совместимым.
Заданием по описываемой учебной дисциплине «Современные Internet-технологии» стала модификация одного из задания дисциплины «Добыча знаний: теоретические основы и инструментальные средства Data mining», изучаемой в том же семестре. По «Data mining» в том числе требовалось реализовать поиск по словам и метаданным вебстраниц (своего рода поисковая система), однако не было никаких требований к средствам реализации.
В задании по «Современным Internet-технологиям» были выделены две части.
Непроверяемая часть задания:
- Выбрать web-сайт и скачать его содержимое (частично).
- Извлечь текстовую информацию из каждой страницы.
- Извлечь метаинформацию из каждой страницы.
Проверяемая часть задания:
- Построить индекс типа RDD[(A, B)], в котором ключом является слово, а значением — список ссылок, на страницах которых встречается это слово.
- Построить временную Spark SQL таблицу, в которой есть 2 столбца: (значение метаданного; ссылка на страницу, имеющую это значение метаданного).
- Реализовать поиск по словам на странице.
- Реализовать поиск по метаданным страниц.
- Реализовать запись/чтение индекса. Индекс не должен строится каждый раз при запуске программы.
- «Слова» и «Значения метаданных» должны передаваться как HTTP GET параметры результирующего приложения. В ответ необходимо возвращать список ссылок на ресурсы, удовлетворяющие запросу.
Второе задание для магистрантов было групповым (группы по 2 человека). Первой группе было необходимо «написать программу MapReduce сканирования и переименование записей Lily». Задание было направлено на обучение работы с традиционным MapReduce подходом. Второй группе предлагалось переходное MapReduce-Spark задание, предполагающее «реализацию умножения матриц в парадигме MapReduce и Spark для сравнения их эффективности и простоты написания».
Третьей группе было дано задание на «реализацию в GraphX поиска кратчайшего пути в графе сформированном на основе Википедии для разрабатываемой системы, основанной на методах онтологического инжиниринга», выбранное с учётом темы магистерской диссертации.
В рамках учебной дисциплины также были рассмотрены технологии HDFS, Giraph, YARN, HBase, Lily, Solr, Cascading и прочие, однако описание опыта их преподавания выходит за рамки доклада.
- Литература
- Русаков C. В., Хеннер Е. К., Чуприна С. И. Интеграция базовой университетской подготовки специалистов по информатике и информационным технологиям // Университетское управление: практика и анализ, № 3, 2014. С. 119–125.
- Костарев А. Ф., Полещук А. Н., Разработка свободно распространяемого контент-репозитория для развёртывания информационных систем на принципах облачных вычислений, 2012
- Spark: Cluster Computing with Working Sets. Matei Zaharia, Mosharaf Chowdhury, Michael J. Franklin, Scott Shenker, Ion Stoica. HotCloud 2010.
- Официальный сайт Apache Spark. https://spark.apache.org/
- Spark News Spark wins Daytona Gray Sort 100TB Benchmark. https://spark.apache.org/news/spark-wins-daytona-gray-sort-100tb-benchmark.html
- Paco Nathan How Apache Spark fits in the Big Data landscape. http://www.slideshare.net/pacoid/how-spark-fits-into-the-big-data-landscape
- M. Тим Джонс Spark, альтернатива для быстрого анализа данных. http://www.ibm.com/developerworks/ru/library/os-spark/
Примечания и отзывы
Plays:175
Comments:0