Использование системы выделенных признаков для задач поиска по исходному тесту (Алексей Пустыгин, OSEDUCONF-2017) — различия между версиями
Материал из 0x1.tv
StasFomin (обсуждение | вклад) |
StasFomin (обсуждение | вклад) (Batch edit: replace PCRE (\n\n)+(\n) with \2) |
||
== Аннотация ==
;Докладчик: {{Speaker|Алексей Пустыгин}}
<blockquote>
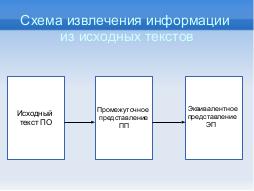
В данном исследовании используются инструменты извлечения данных из открытого программного кода в целях поиска по
условиям, формирование и формализация которых слишком сложны или невозможны иным способом. С этой целью строится
эквивалентное представление исходного текста, являющееся набором неделимых блоков исходного текста. Использование
системы выделенных признаков для блоков исходного текста показывает возможность контекстного поиска по синтаксическим
признакам.
</blockquote>
== Видео ==3974 & bool xml\_node::operator==(const xml\_node\& r) const\\\hline
3979 & bool xml\_node::operator!=(const xml\_node\& r) const\\\hline
3984 & bool xml\_node::operator{\textless}(const xml\_node\& r) const\\\hline
3989 & bool xml\_node::operator{\textgreater}(const xml\_node\& r) const\\\hline
3994 & bool xml\_node::operator{\textless}=(const xml\_node\& r) const\\\hline
3999 & bool xml\_node::operator{\textgreater}=(const xml\_node\& r) const\\\hline
\end{tabular}
\end{center}
\end{table}
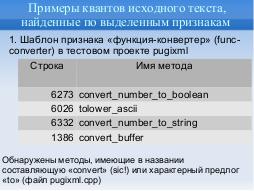
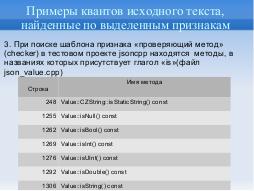
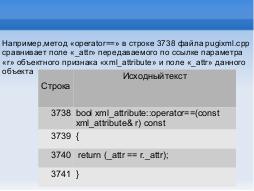
Например, метод «operator==» в строке 3738 файла pugixml.cpp сравнивает поле «\_attr» передаваемого по ссылке параметра
«r» объектного признака «xml\_attribute» и поле «\_attr» данного объекта (Таблица 5).
\begin{table}
\begin{center}
\small
\caption{Исходный код метода с признаком «сравнивающий метод»}
\begin{tabular}{|c|l|}\hline
Стр. & Исходный текст\\\hline
3738 & bool xml\_attribute::operator==(const xml\_attribute\& r) const\\\hhline{-~}
3739 & \{\\\hhline{-~}
3740 & return (\_attr == r.\_attr);\\\hhline{-~}
3741 & \}\\\hline
\end{tabular}
\end{center}
\end{table}
\Emph{Выводы}
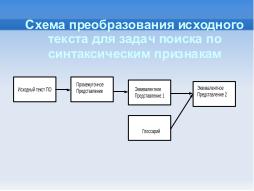
На основе УПП [2] и дополненного эквивалентного представления UIRDCF [7] была введена тестовая система признаков и
разработан прототип утилиты, которая выделяет признаки квантов исходного текста согласно применению набора шаблонов
(глоссария) над эквивалентным представлением UDCFM, группирует кванты, строит разбиения по заданным параметрам, тем
самым выделяя нетривиальные множества признаков, а также позволяет выполнять поиск квантов по заданным признакам.
Предложенный подход выделения признаков показал свою применимость для задач поиска квантов исходного текста по сложным== Примечания и отзывы ==
<!-- <blockquote>[©]</blockquote> -->
{{fblink|1845644302355249}}
{{vklink|426}}
<references/>
[[File:{{#setmainimage:Использование системы выделенных признаков для задач поиска по исходному тесту (Алексей Пустыгин, OSEDUCONF-2017)!.jpg}}|center|640px]]
<!-- topub -->
[[Категория:OSEDUCONF-2017]]
[[Категория:Образование]]
[[Категория:Open-source]]
{{stats|disqus_comments=0|refresh_time=2021-08-31T17:10:04.795526|vimeo_comments=0|vimeo_plays=4|youtube_comments=0|youtube_plays=26}} | |||
Версия 12:21, 4 сентября 2021
Содержание
Аннотация
- Докладчик
- Алексей Пустыгин


В данном исследовании используются инструменты извлечения данных из открытого программного кода в целях поиска по условиям, формирование и формализация которых слишком сложны или невозможны иным способом. С этой целью строится эквивалентное представление исходного текста, являющееся набором неделимых блоков исходного текста. Использование системы выделенных признаков для блоков исходного текста показывает возможность контекстного поиска по синтаксическим признакам.
Видео
Посмотрели доклад? Понравился? Напишите комментарий! Не согласны? Тем более напишите.
Слайды















Тезисы
Примечания и отзывы
!.jpg)
Plays:30 Comments:0