Разработка кроссплатформенной библиотеки морфологического анализа текстов на русском языке для использования в промышленных системах (Екатерина Полицына, SECR-2018) — различия между версиями
Материал из 0x1.tv
StasFomin (обсуждение | вклад) |
StasFomin (обсуждение | вклад) |
||
* [https://2018.secrus.org/program/submitted-presentations/development-of-the-cross-platform-library-of-morphological-analysis/ Talks page on SECR site]
* http://textanalysis.ru/
* https://github.com/jalexpr/JMorfSdk
<!-- <blockquote>[©]</blockquote> -->
{{fblink|2191759061077103}}
{{vklink|1298}}
<references/>
<!-- topub -->
{{stats|disqus_comments=1|refresh_time=2021-08-25T03:40:2431T18:13:04.658686599532|vimeo_plays=33|youtube_comments=0|youtube_plays=22}}
[[Категория:SECR-2018]]
[[Категория:Natural Language Processing]] | |||
Версия 15:13, 31 августа 2021
- Докладчик
- Екатерина Полицына


Потребность в автоматизации обработки больших объемов текстовых данных приводит к необходимости использования инструментов компьютерной лингвистики в прикладных промышленных системах разной направленности (системах документооборота, электронной коммерции и др.), что накладывает дополнительные требования к средствам автоматического анализа текста.
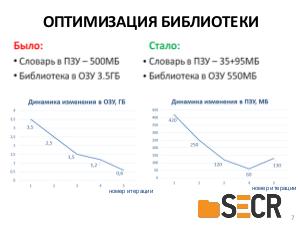
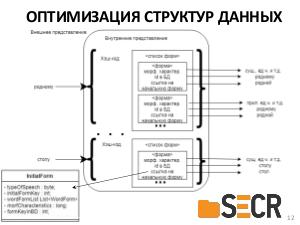
В отличие более мягких требований к исследовательским инструментам, для использования в промышленных системах необходимы библиотеки, отвечающие требованиям производительности, надежности, совместимости с современными современными языками программирования, сборки проектов и т.д.
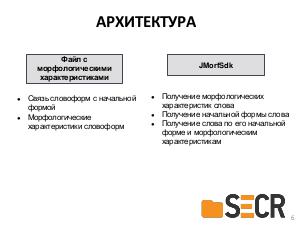
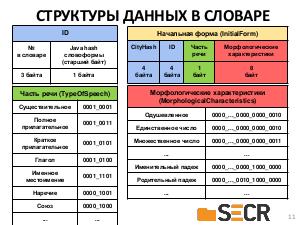
В докладе предлагается новая кроссплатформенная библиотека морфологического анализа текстов на русском языке с открытым исходным кодом, которая может быть полезна разработчикам информационных систем и исследователям в области компьютерной лингвистики для получения начальных форм слова или генерации нужной формы по заданным морфологическим характеристикам.
Видео
Посмотрели доклад? Понравился? Напишите комментарий! Не согласны? Тем более напишите.
Презентация









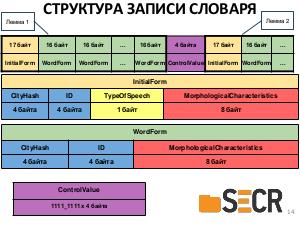

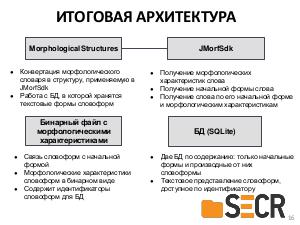








Примечания и ссылки
Plays:55 Comments:1