Об актуальных потребностях обработки больших данных в биоинформатике (Иван Короткий, SECR-2018) — различия между версиями
Материал из 0x1.tv
StasFomin (обсуждение | вклад) |
StasFomin (обсуждение | вклад) |
||
* [https://2018.secrus.org/program/submitted-presentations/using-databases-for-processing-genomes/ Talks page on SECR site]
<!-- <blockquote>[©]</blockquote> -->
{{fblink|2196950270557982}}
{{vklink|1343}}
<references/>
<!-- topub -->
[[Категория:SECR-2018]]
[[Категория:BigData]]
{{stats|disqus_comments=0|refresh_time=2020-07-06T20:09:5607T22:58:57.399109023433|vimeo_plays=132|youtube_comments=0|youtube_plays=22}} | |||
Версия 19:58, 7 июля 2020
- Докладчик
- Иван Короткий


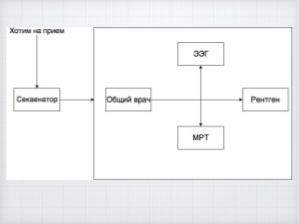
Биоинформатика находится в лидерах по масштабу используемых данных, среди её методов можно выделить секвенирование, которое широко используется в науке и медицине, а значит там существуют проблемы которые связаны с обработкой данных, которые в данный момент по классификации переходят в объём big data. Мы предлагаем использовать базы данных, в обработке биоинформатических данных из-за того, что никто не пытался их тут применить, а отрасль как раз переходит в то состояние где требуются подходы нового поколения.
В выступлении будет раскрыта ситуация в долгосрочной перспективе. Доклад не требует начальных знаний для посещения.
Видео
Посмотрели доклад? Понравился? Напишите комментарий! Не согласны? Тем более напишите.
Презентация









!.jpg)
Примечания и ссылки
Plays:154 Comments:0