Повышение качества разработки программного обеспечения с помощью интеллектуального анализа отчетов об ошибках (Анна Громова, SECR-2019) — различия между версиями
Материал из 0x1.tv
StasFomin (обсуждение | вклад) |
StasFomin (обсуждение | вклад) |
||
{{----}}
[[File:{{#setmainimage:Повышение качества разработки программного обеспечения с помощью интеллектуального анализа отчетов об ошибках!.jpg}}|center|640px]]
{{LinksSection}}
* [https://2019.secrus.org/program/submitted-presentations/raising-quality-of-software-development-by-data-mining-of-defect-reports/ Talks page on SECR site]
<!-- <blockquote>[©]</blockquote> -->
<references/>
* https://github.com/exactpro/nostradamus
<!-- topub -->
{{stats|disqus_comments=0|refresh_time=2020-01-22T18:30:4328T10:51:08.506579308892|vimeo_plays=2|youtube_plays=0}}
[[Категория:SECR-2019]]
[[Категория:Machine Learning]]
[[Категория:Мониторинг]]
[[Категория:Управление техподдержкой]] | |||
Версия 07:51, 28 января 2020
- Докладчик
- Анна Громова


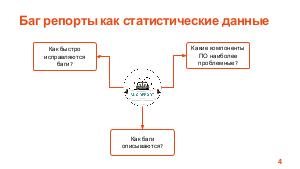
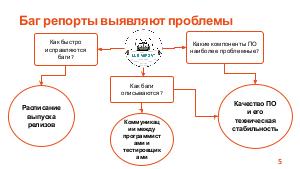
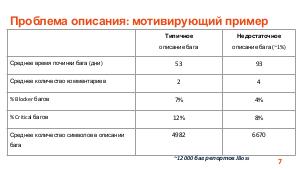
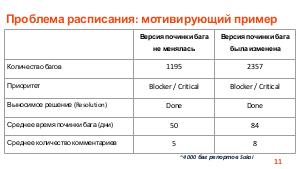
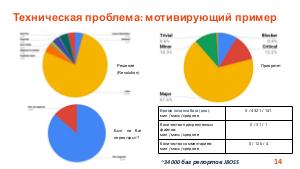
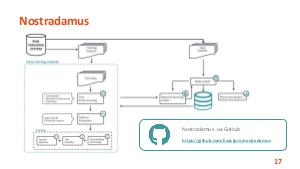
Проект, в рамках которого ведется разработка программного обеспечения, может содержать тысячи отчетов об ошибках (баг репортов). Отчеты об ошибках могут быть рассмотрены как статистические данные. В этих данных существуют скрытые зависимости, выявление которых может быть полезно для инженеров по тестированию, разработчиков, руководителей проектов и других специалистов в области информационных технологий.
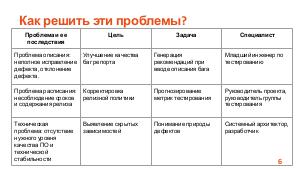
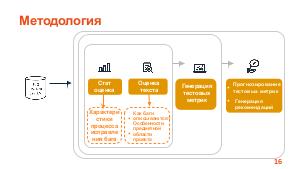
Доклад посвящен тому, как технологии машинного обучения могут помочь не только выявить скрытые зависимости в отчетах об ошибках, но и улучшить стратегии тестирования и разработки.
Видео
Посмотрели доклад? Понравился? Напишите комментарий! Не согласны? Тем более напишите.
Презентация











Примечания и ссылки
Plays:2 Comments:0