Повышение качества поиска в больших объёмах текстовых документов с использованием генетического алгоритма (Ирина Плешкова) — различия между версиями
Материал из 0x1.tv
StasFomin (обсуждение | вклад) |
StasFomin (обсуждение | вклад) |
||
== Примечания и отзывы ==
<!-- <blockquote>[©]</blockquote> -->
<references/>
[[Category:OSEDUCONF-2015]]
[[Category:Natural Language Processing]]
[[Category:Open-source projects]]
<!-- topub -->
{{stats|vimeo_comments=0|youtube_plays=235|refresh_time=2017-0711-06T14:37:0711T00:11:59.488000953980|youtube_comments=1|vimeo_plays=57}} | |||
Версия 21:11, 10 ноября 2017
Содержание
Аннотация
- «Повышение качества поиска в больших объёмах текстовых документов с использованием генетического алгоритма как способ поддержки научных исследований»
- Докладчик
- Ирина Плешкова
В докладе рассматривается проблема работы с большими объёмами текстовых документов. Существующие подходы к синтаксическому поиску имеют недостаточно высокое качество, а семантические неприменимы к большим объёмам данных.
В докладе описывается новый подход к эффективной реализации семантического поиска, применимый к большим объёмам документов, с использованием генетического алгоритма. Предлагаются эвристики, учитывающие традиционную структуру научной публикации и таким образом позволяющие улучшить качество поисковых результатов.
Видео
Слайды













Тезисы
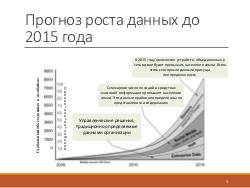
В мире, согласно исследованию IBM, каждый день уже в 2012 году появлялось 2.5 экзабайта данных. Считается, что закон Мура применим не только к вычислительным мощностям, но и к объёмам данных, т.е. можно ожидать, по крайней мере, удвоение объёмов данных каждые 2 года.
Согласно статистике IDC, 90% данных хранятся в неструктурированном, в том числе в текстовом виде. Когда данных много, в них сложно что-то найти.
А если человек не знает, какие конкретно слова используются в нужных ему документах, а знает только предметную область, то ему не подойдёт традиционный поиск по подстроке.
В частности, у некоторых компаний за время работы накапливается много документов в текстовом виде.
Это могут быть нормативные акты, контракты, инструкции, технические задания, заказы и т.д., которые не хранятся в информационной системе, даже если она внедрена.
В организациях, занимающихся научно-исследовательской деятельностью, например, НИИ, может быть своя электронная библиотека, состоящая как из публикаций, написанных работниками, так и научных материалов, которые были куплены для проведения исследований.
Интеллектуальный поиск по ним поможет сэкономить как время работников, поскольку в выдаче будут присутствовать только релевантные документы, так и средства в случае, если необходимая информация уже была в библиотеке.
Говоря о библиотеках вообще, можно заметить тенденцию к цифровому формату книг и журналов. Интеллектуальный поиск позволит реализовать нечто вроде рекомендаций по тематике, а не по конкретным словам, использующимся в тексте. Тот же интеллектуальный подход можно применить к новостным сайтам.
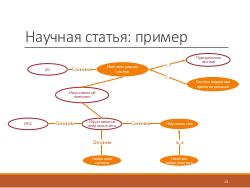
Все эти примеры сводятся к тому, что зачастую бывает полезен поиск по смыслу, а не по используемым в тексте словам. Предлагается новый подход к семантическому поиску по текстовым данным, и, конкретно, новый способ семантической индексации документов с помощью генетического алгоритма и онтологий.
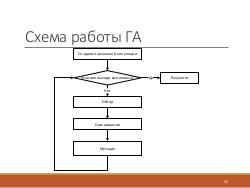
Генетические алгоритмы быстры и достаточно точны при правильной настройке параметров, а также при использовании совместно с онтологиями они позволяют индексировать понятия, которых нет в тексте в явном виде.
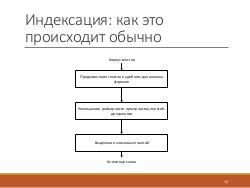
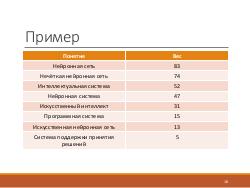
На основе общей модели генетического алгоритма была построена модель индексации текстовых документов. В ней каждому понятию приписывается вес, вычисляемый на основе множества критериев. Правила вычисления веса задаются декларативно и определяются в процессе исследования. В частности, было выяснено, что для научных публикаций при вычислении веса понятий, помимо стандартных статистических характеристик, таких как, например, частота встречаемости слов, можно использовать данные о структуре текста, ввиду стандартизованности этой структуры.
Например, предлагается повышать вес понятий, встречающихся в аннотации либо в списке ключевых слов.
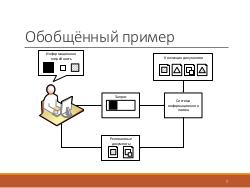
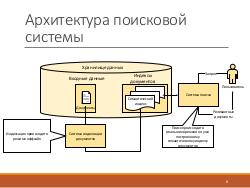
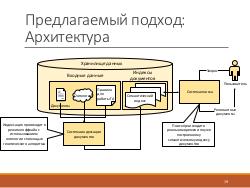
Разрабатываемая система семантического поиска работает с хранилищем данных, где содержатся документы и онтологии.
Индексация происходит в режиме оффлайн с помощью генетического алгоритма. Система поиска получает на вход запрос пользователя, производит поиск в реальном времени по уже построенному семантическому индексу и возвращает релевантные документы. Заметим, что эти документы могут не содержать ни одного слова из запроса, но, тем не менее, удовлетворять информационные потребности пользователя.
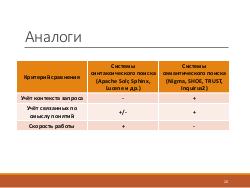
Основные критерии качества поисковой системы — скорость и качество поиска. Традиционные поисковые системы выполняют поиск быстро, но результаты могут быть неточны из-за того, что они не учитывать семантически связанные понятия и контекст. Системы семантического поиска обычно предоставляют более полные и точные результаты, но работают медленнее из-за того, что семантика учитывается в процессе поиска, а не индексации. В предлагаемом подходе с одной стороны, учитываются и связанные по смыслу понятия и контекст запроса за счёт использования онтологий и индексации с помощью генетического алгоритма, а с другой стороны, скорость поиска будет высокой, поскольку на этапе поиска будет лишь обращение к семантическому индексу, который построен в оффлайн режиме.
Работа выполнена при поддержке гранта фонда содействия развитию малых форм предприятий в научно-технической сфере «УМНИК».
- Литература
- Плешкова И.Ю. Разработка системы семантического поиска по текстовым документам // Материалы X Студенческого регионального конкурса научных проектов по программе УМНИК 27-28 ноября 2014 г. Пермь. 2014. pp. 35-38.
Примечания и отзывы
Plays:82
Comments:1