Сравнение Big Data решений для аналитической обработки больших объемов биомедицинской информации (Игорь Сухоруков, SECR-2018) — различия между версиями
Материал из 0x1.tv
StasFomin (обсуждение | вклад) |
StasFomin (обсуждение | вклад) |
||
* [https://2018.secrus.org/program/submitted-presentations/sequence-diagram-generated-from-bdd-test/ Talks page on SECR site]
<!-- <blockquote>[©]</blockquote> -->
{{fblink|2183901471862862}}
{{vklink|1311}}
<references/>
<!-- topub -->
[[Категория:SECR-2018]]
[[Категория:BigData]]
{{stats|disqus_comments=0|refresh_time=2020-017-28T13:44:3006T21:37:41.733097897472|vimeo_plays=6377|youtube_comments=0|youtube_plays=73}}94}} | |||
Версия 18:37, 6 июля 2020
- Докладчик
- Игорь Сухоруков


Все больше компаний в тренде и готовы анализировать все доступные источники информации, отвечать на насущные вопросы бизнеса, находить закономерности и планировать изменения продукта. Теперь это касается не только корпораций, но и малые/средние предприятия которые не могут позволить себе длительный time to market и большой штат разработчиков bigdata решений.
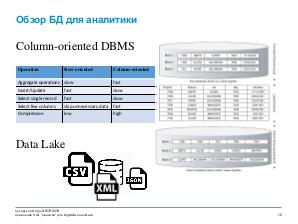
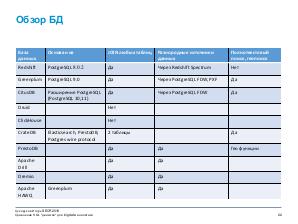
Поэтому на помощь в обработке больших данных бизнесу приходит старый добрый язык запросов SQL. В докладе рассмотрим существующие SaaS и open source решения AWS Redshift, Greenplum, CitusDB, Druid, ClickHouse, CrateDB, PrestoDB, Apache Drill, Dremio, Apache HAWQ. Рассмотрим их слабые и сильные стороны и сравним их области применимости. А также расскажу как наш отдел трансформирует и обрабатывает большие объемы данных об ортодонтическом лечении используя инфраструктуру Amazon Web Service.
Видео
Посмотрели доклад? Понравился? Напишите комментарий! Не согласны? Тем более напишите.
Презентация






















!.jpg)
Примечания и ссылки
Plays:171 Comments:0