Аналитика на 100млн. данных. Краткий ликбез для системных интеграторов (Татьяна Бунто, SECR-2018) — различия между версиями
Материал из 0x1.tv
StasFomin (обсуждение | вклад) |
StasFomin (обсуждение | вклад) |
||
<!-- <blockquote>[©]</blockquote> -->
{{vklink|1280}}
{{fblink|2232466620339680}}
<references/>
<!-- topub -->
[[Категория:SECR-2018]]
[[Категория:Data Analysis]]
[[Категория:Бизнес-анализ]]
{{stats|disqus_comments=3|refresh_time=2020-01-22T19:13:2528T11:33:41.718128163657|vimeo_plays=61|youtube_comments=0|youtube_plays=15}} | |||
Версия 08:33, 28 января 2020
- Докладчик
- Татьяна Бунто


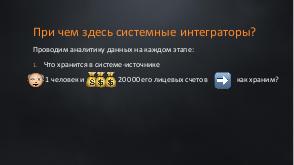
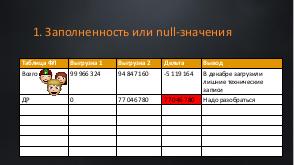
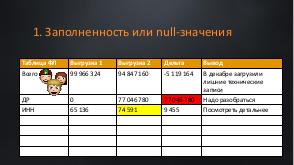
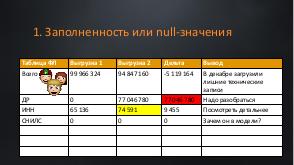
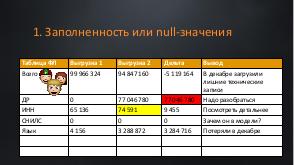
В энтерпрайз-системах данные накапливаются годами. И вроде простая задача — настроить интеграцию из баз-источников в базу данных вашей системы. Казалось бы, какие могут быть проблемы? Согласуй модель системы, сделай мэппинг. Подвох в том, что все врут! Идеальных данных не бывает! И наша задача отсечь все ненужное и не потерять ценное. А для этого нужно проводить аналитику.
Вишенкой на торте становятся объемы. Перегрузить 100млн данных не равно перегрузке 10млн. Для 100 млн нужно особенно тщательно учитывать специфику модели, дальнейшее предназначение системы и сценарии ее использования,
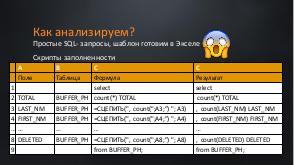
На каких этапах интеграции систем нужно анализировать данные? Как проверять, зачем? И самое главное — что делать с результатами?
Поделюсь опытом, интересными кейсами и примерами. Дам советы по анализу данных при проектировании интеграции систем.
Доклад будет интересен всем, кто интересуется качеством данных при интеграции систем, хочет привести в порядок БД своей системы, а также тем, кто составляет планы проектов и не понимает, зачем тратить время на такие исследования.
Видео
Посмотрели доклад? Понравился? Напишите комментарий! Не согласны? Тем более напишите.
Презентация

































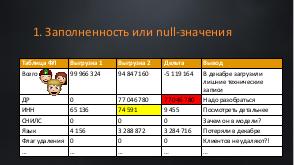
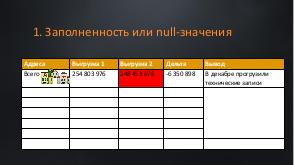
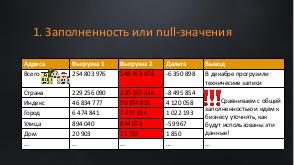

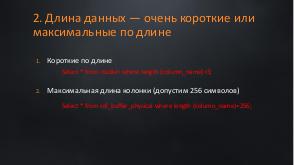






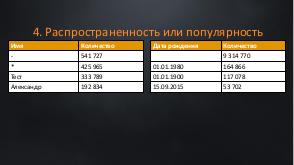
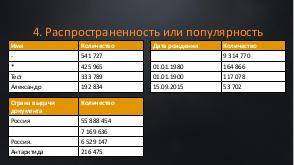
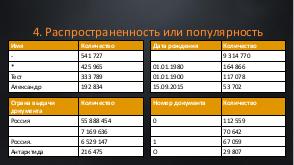
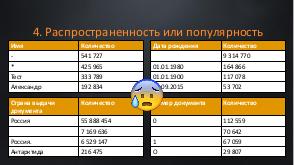






















!.jpg)
Примечания и ссылки
Plays:76 Comments:3