Экспериментальное изучение количественных закономерностей при анализе open-source кода по эквивалентным представлениям — различия между версиями
Материал из 0x1.tv
StasFomin (обсуждение | вклад) (Batch edit: replace PCRE \{\{youtubelink\|([^\}]*)\}\} with {{youtubelink|\1}}{{letscomment}}) |
StasFomin (обсуждение | вклад) |
||
| (не показано 17 промежуточных версий этого же участника) | |||
== Видео ==
{{vimeoembed|116172017|800|450}}
{{youtubelink|ktLVLt_zcTE}}{{letscomment}}
{{oseduconf-2015-draft}}
<!-- pollholder -->
== Слайды ==
[[File:Экспериментальное изучение количественных закономерностей при анализе open-source кода по эквивалентным представлениям.pdf|left|page=-|256px]]
== Тезисы ==
[[File:Экспериментальное изучение количественных закономерностей при анализе исходных текстов ПО с открытым кодом-тезисы.svg|800px]]
{{----}}
== Примечания и отзывы ==
<!-- <blockquote>[©]</blockquote> -->
<references/>
[[Category
Category:Наука]]
[[Category:Open-source projects]]
<!-- topub -->
{{stats|disqus_comments=0|refresh_time=2018-10-11T00:32:522021-08-31T18:43:25.746739325883|vimeo_comments=0|vimeo_plays=123|youtube_comments=0|youtube_plays=18}}23}}
[[Категория:OSEDUCONF-2015]]
[[Категория:Статический анализ кода]] | |||
Текущая версия на 08:58, 20 октября 2025
Содержание
Аннотация
- «Экспериментальное изучение количественных закономерностей при анализе исходных текстов ПО с открытым кодом по эквивалентным представлениям»
- Докладчик
- Алексей Пустыгин


Использование эквивалентных представлений исходных текстов программ для извлечения знаний разработчика дает широкие возможности для анализа. Обычно результаты такого анализа представлены в текстовой или графической форме. Применение эквивалентных представлений позволяет получать также и количественные оценки, которые характеризуют исходный код ПО. Рассматриваются результаты исследований количественных закономерностей, извлеченных из эквивалентного представления.
Видео
Слайды

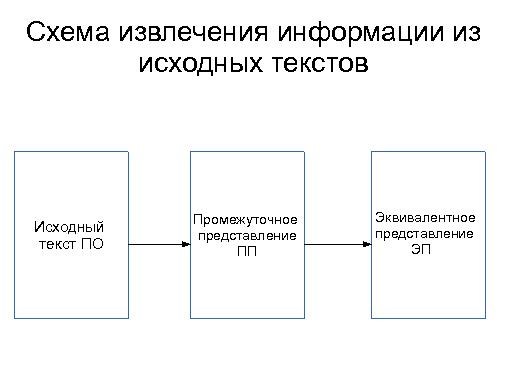




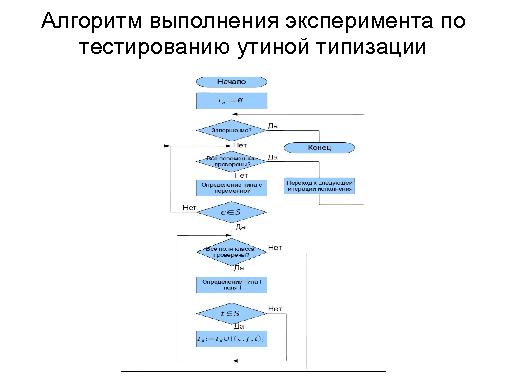

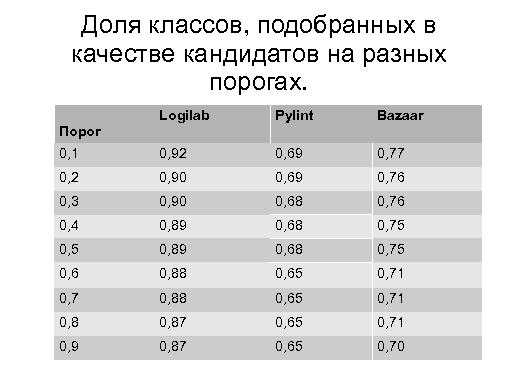
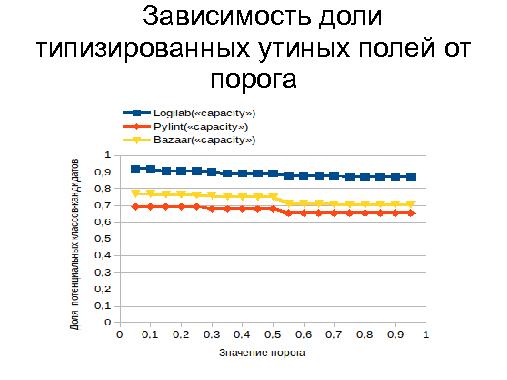


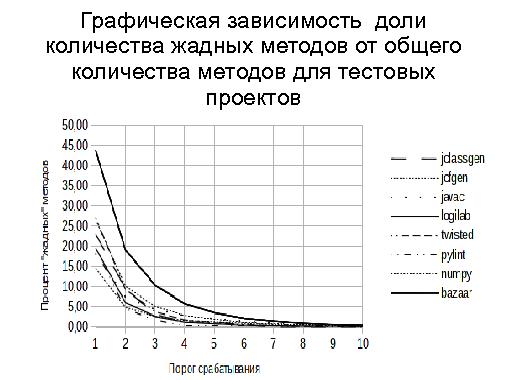
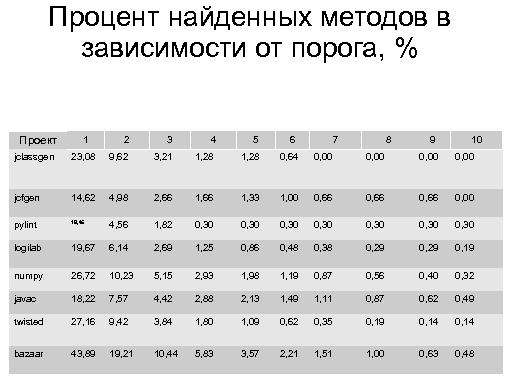


Тезисы

Примечания и отзывы
Plays:36
Comments:0