Использование системы выделенных признаков для задач поиска по исходному тесту (Алексей Пустыгин, OSEDUCONF-2017) — различия между версиями
Материал из 0x1.tv
StasFomin (обсуждение | вклад) |
StasFomin (обсуждение | вклад) |
||
| (не показаны 52 промежуточные версии этого же участника) | |||
== Аннотация ==
;Докладчик: {{Speaker|Алексей Пустыгин}}
<blockquote>
В данном исследовании используются инструменты извлечения данных из открытого программного кода в целях поиска по
условиям, формирование и формализация которых слишком сложны или невозможны иным способом. С этой целью строится
эквивалентное представление исходного текста, являющееся набором неделимых блоков исходного текста. Использование
системы выделенных признаков для блоков исходного текста показывает возможность контекстного поиска по синтаксическим
признакам.
</blockquote>
== Видео ==
{{vimeoembed|None201654679|800|450}}
<!-- {{youtubelink|}} -->
|Qx2truKkwdk}}
== Слайды ==
[[File:Использование системы выделенных признаков для задач поиска по исходному тесту (Алексей Пустыгин, OSEDUCONF-2017).pdf|left|page=-|256px]]
== Тезисы ==
<latex>
Задача статического анализа программных систем является одной из традиционных способов улучшения программ
[<ref name="cite-1]" />.
В предшествующих разработках [<ref name="cite-2]" /> было предложено и реализовано универсальное промежуточное представление
(УПП) открытого исходного текста, предназначенное для последующего преобразования, анализа и извлечения информации из
исходного кода программ [<ref name="cite-8]" />.
На основе этого набора данных был построен прототип генератора эквивалентного
представления, предназначенныхй для решения некоторой совокупности задач над исходным текстом.
Алгоритм получения набора данных состоит из двух этапов преобразований.
Сначала из УПП путеём атрибутирования метками
потока данных (операции над данными) и потока управления (вызовы, передача управления) получается эквивалентное
представление UIRDCF[<ref name="cite-7]" />.
На втором этапе последовательно просматривается глоссарий, и для каждой его записи выполняется
модификация каждого кванта UIRDCF, если он соответствует шаблону признака из глоссария.
Полученное эквивалентное
представление назовеём UDCFM.
Для тестирования использовались проекты с открытым исходным кодом pugixml [<ref name="cite-3]" />, jsoncpp [<ref name="cite-4]" />, lz4 [<ref name="cite-5]" /> и zlib [<ref name="cite-6]" />.
Была предложена тестовая система признаков (глоссарий), сформированная из эвристических соображений, соответствующих
алгоритмическому смыслу описываемого кванта.
Глоссарий признаков описывается в текстовом файле в формате XML -документа и разделеён на две категории квантов: метод и
класс.
Каждая категория содержит набор шаблонов, соответствующих искомым признакам квантов, в виде блока условий:
\begin{verbatim}
<pre style="font-size:80%">
<type name="<<имя признака>>" title="<<описание признака>>"
[параметры признака] >
<>
<node name="<<имя тега>>" [параметры условия] >
<>
<attr name="<<имя атрибута>>" [параметры атрибута] />
…
</node>
…
</type>
\end{verbatim}
>
…
</node>
…
</type>
</pre>
Каждый узел условия конкретизирует свойства искомого признака кванта.
Например, например в категории «метод» для признака
«получатель поля» (getter) заданы следующие условия шаблона:
\begin{verbatim}
<pre style="font-size:80%">
<node name="MethodDecl">
<>
<attr name="const" vb="true" />
<>
<attr name="argc" vi="0"/>
<>
</node>
<>
<node name="FieldRef" tags="return" parent="this" />
</pre>
\end{verbatim}
Что соответствует:
\begin{itemize}
\item* метод является константным,
\item;
* метод не имеет аргументов,
\item;
* поле объекта this напрямую возвращается оператором return.
\end{itemize}
Атрибут <tt>tags</tt> второго условия определяет набор меток из эквивалентного представления UDCFM, которым должен обладать узел
УПП.
Формат шаблонов позволяет записывать условия, требующие семантического анализа, который дополнительно выполняется
утилитой на первом этапе обработки запроса.
Результат этого анализа записывается в метаданные узлов дерева разбора, к
которым относится: принадлежность типу, принадлежность классу определения, узел дерева точки объявления.
К метаданным
добавляется информация UDCFM, которая включает в себя итеративно дополняемый список уже вычисленных признаков квантов
на базе анализа предыдущих шаблонов.
Предложенная система признаков разбивает достаточно крупный проект на некоторое количество уникальных групп квантов, т.
е.то есть групп методов или классов.
Например, для проекта pugixml с 621 методом количество групп методов составляет 200, а
для проекта jsoncpp с 532 методами количество групп методов— 101.
{\bfseries
==== Примеры выделенных признаков квантов исходного текста} ====
Для шаблона признака «функция-конвертер» (func-converter) в тестовом проекте pugixml утилита показывает методы, имеющий
имеющие в названии составляющую «convert» (sic!) или характерный предлог «to» (Таблица см, таблицу ниже), что является симптоматичным
совпадением, т.к.так как имена шаблонов не привязаны к именам идентификаторов.
Признак «функция-конвертер» полностью
соответствует 39 методам проекта и входит в 16 групп строгих дайджестов.
\begin{table}
\begin{center}
\caption{{| class="wikitable" style="font-size:90%; text-align:center;"
|+ Примеры методов признака «функция-конвертер» (файл pugixml.cpp)}
\begin{tabular}
! Стр. !! Имя метода
|-
| c|c|}\hline
Стр. & Имя метода\\\hline
6273 & convert\_number\_to\_boolean\\\hline
|| convert_number_to_boolean
|-
| 6026 & tolower\_ascii\\\hline
|| tolower_ascii
|-
| 6332 & convert\_number\_to\_string\\\hline
|| convert_number_to_string
|-
| 1386 & convert\_buffer\\\hline
\end{tabular}
\end{center}
\end{table}|| convert_buffer
|}
При поиске шаблона признака «проверяющая функция» (func{}-checker) в тестовом проекте pugixml находится функция\\
«check\_string\_to\_number\_ formatcheck_string_to_number_format» (строка 6395, файл pugixml.cpp) с ключевым словом «check» в имени.
При поиске шаблона признака «проверяющий метод» (checker) в тестовом проекте jsoncpp находятся соответствующие методы, в
названиях которых присутствует глагол «is» (Таблица .
{| class="wikitable" style="font-size:90%; text-align:center;"
|+ )
\begin{table}
\begin{center}
\caption{Примеры методов с признаком «проверяющий метод» (файл json\_value.cpp)}
\begin{tabular}{|c|c|}\hline
Стр. &
! Стр. !! Имя метода\\\hline
|-
| 248 &|| Value::CZString::isStaticString() const\\\hline
|-
| 1255 &|| Value::isNull() const\\\hline
|-
| 1262 &|| Value::isBool() const\\\hline
|-
| 1269 &|| Value::isInt() const\\\hline
|-
| 1276 &|| Value::isUInt() const\\\hline
|-
| 1292 &|| Value::isDouble() const\\\hline
|-
| 1306 &|| Value::isString() const\\\hline
\end{tabular}
\end{center}
\end{table}
|}
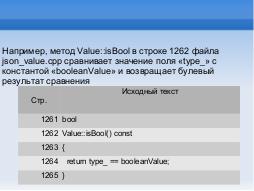
Например, метод <tt>Value::isBool</tt> в строке 1262 файла json\_value<tt>json_value.cpp</tt> сравнивает значение поля «type\_»<tt>type_</tt> с константой
« <tt>booleanValue»</tt> и возвращает булевый результат сравнения (Таблица .
{| class="wikitable" style="font-size:90%; text-align:left;"
|+ ).
\begin{table}
\begin{center}
\caption{Исходный код метода признака «проверяющий метод»}
\begin{tabular}{|c|l|}\hline
Стр. &
! Стр. !! Исходный текст\\\hline
|-
| 1261 &|| bool \\\hline
|-
| 1262 &|| Value::isBool() const\\\hline
|-
| 1263 & \|| { \\\hline
|-
| 1264 &|| return type\_ == booleanValue;\\\hline
|-
| 1265 & \}\\\hline
\end{tabular}
\end{center}
\end{table}|| }
|}
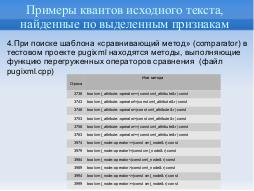
При поиске шаблона «сравнивающий метод» (comparator) в тестовом проекте pugixml находятся методы, выполняющие функцию
перегруженных операторов сравнения (Таблица 4).
\begin{table}
\begin{center}
\small
\caption{.
{| class="wikitable" style="font-size:90%; text-align:center;"
|+ Примеры методов с признаком «сравнивающий метод» (файл pugixml.cpp)}
\begin{tabular}{|c|c|}\hline
Стр. &
! Стр. !! Имя метода\\\hline
|-
| 3738 &|| bool xml\_attribute::operator==(const xml\_attribute\xml_attribute& r) const\\\hline
|-
| 3743 &|| bool xml\_attribute::operator!=(const xml\_attribute\xml_attribute& r) const\\\hline
|-
| 3748 &|| bool xml\_attribute::operator{\textless}<(const xml\_attribute\xml_attribute& r) const\\\hline
|-
| 3753 &|| bool xml\_attribute::operator{\textgreater}>(const xml\_attribute\xml_attribute& r) const\\\hline
|-
| 3758 &|| bool xml\_attribute::operator{\textless}<=(const xml\_attribute\xml_attribute& r) const\\\hline
|-
| 3763 &|| bool xml\_attribute::operator{\textgreater}>=(const xml\_attribute\xml_attribute& r) const\\\hline
|-
| 3974 &|| bool xml\_node::operator==(const xml\_node\xml_node& r) const\\\hline
|-
| 3979 &|| bool xml\_node::operator!=(const xml\_node\xml_node& r) const\\\hline
|-
| 3984 &|| bool xml\_node::operator{\textless}<(const xml\_node\xml_node& r) const\\\hline
|-
| 3989 &|| bool xml\_node::operator{\textgreater}>(const xml\_node\xml_node& r) const\\\hline
|-
| 3994 &|| bool xml\_node::operator{\textless}<=(const xml\_node\xml_node& r) const\\\hline
|-
| 3999 &|| bool xml\_node::operator{\textgreater}>=(const xml\_node\xml_node& r) const\\\hline
\end{tabular}
\end{center}
\end{table}
|}
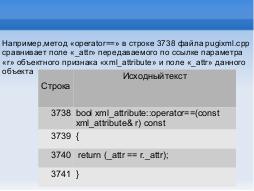
Например, метод «<tt>operator==»</tt> в строке 3738 файла <tt>pugixml.cpp</tt> сравнивает поле «\<tt>_attr»</tt> передаваемого по ссылке параметра
« <tt>r»</tt> объектного признака «xml\_attribute»<tt>xml_attribute</tt> и поле «\<tt>_attr»</tt> данного объекта (Таблица .
{| class="wikitable" style="font-size:90%; text-align:left;"
|+ ).
\begin{table}
\begin{center}
\small
\caption{Исходный код метода с признаком «сравнивающий метод»}
\begin{tabular}{|c|l|}\hline
Стр. &
! Стр. !! Исходный текст\\\hline
|-
| 3738 &|| bool xml\_attribute::operator==(const xml\_attribute\xml_attribute& r) const\\\hhline{-~}
|-
| 3739 & \{\\\hhline{-~}
|| {
|-
| 3740 &|| return (\_attr == r.\_attr);\\\hhline{-~}
|-
| 3741 & \}\\\hline
\end{tabular}
\end{center}
\end{table}
\Emph{|| }
|}
==== Выводы} ====
На основе УПП [<ref name="cite-2]" /> и дополненного эквивалентного представления UIRDCF [<ref name="cite-7]" /> была введена тестовая система признаков и
разработан прототип утилиты, которая выделяет признаки квантов исходного текста согласно применению набора шаблонов
(глоссария) над эквивалентным представлением UDCFM, группирует кванты, строит разбиения по заданным параметрам, тем
самым выделяя нетривиальные множества признаков, а также позволяет выполнять поиск квантов по заданным признакам.
Предложенный подход выделения признаков показал свою применимость для задач поиска квантов исходного текста по сложным
или плохо формулируемым условиям. Целью такого поиска может быть поиск недокументированных возможностей и потенциально
ошибочных участков кода, при введении соответствующих признаков и категорий для искомых частей исходного текста
(классов, методов, блоков).
\begin{thebibliography}{9}
\bibitem{pus1} \emph{Зубов\,М.\,В.}== Литература ==
<ref name="cite-1">'''Зубов М. В.''' Статический анализ ПО с помощью его промежуточных представлений и технологий с открытым исходным
кодом / М.\, В.\, Зубов, А.\, Н.\, Пустыгин, Е.\, В.\, Старцев//Матер. // Материалы 2-й Междунар. конф. «FOSS. Lviv-2012», Львов. --- Львiв— Львів: Сорока, 2012. ---— С. 165--–168.
\bibitem{pus2} \emph{Ошнуров\,Н.\,А.} </ref> <ref name="cite-2">'''Ошнуров Н. А.''' Построение универсального промежуточного представления исходных текстов на языках C++ и C\# / Н.\, А.\, Ошнуров, А.\, Н.\, Пустыгин, А.\, А.\, Ковалевский // Доклады Томского государственного университета систем управления и радиоэлектроники. "---— 2014. "---— Т. 33, № 3. "---— С. 135--–139.
\bibitem{pus3} </ref> <ref name="cite-3">Pugixml v1.2 "---— Light-weight, simple and fast XML parser for C++ with XPath support [Электронный ресурс]. URL: \url{[http://pugixml.org/2012/05/01/pugixml-1.2-release.html}] (дата обращения: 12.01.2017).
\bibitem{pus4} </ref> <ref name="cite-4">Jsoncpp v0.5.0 C++ JSON parser [Электронный ресурс]. URL:
\url{ [http://sourceforge.net/projects/jsoncpp/files/jsoncpp/0.5.0/}] (дата обращения: 12.01.2017).
\bibitem{pus5} </ref> <ref name="cite-5">LZ4 r131 "---— Extremely fast compression [Электронный ресурс]. URL: \url{[https://github.com/Cyan4973/lz4}] (дата обращения: 12.01.2017).
\bibitem{pus6} </ref> <ref name="cite-6">Zlib 1.2.8 "---— A Massively Spiffy Yet Delicately Unobtrusive Compression Library [Электронный ресурс]. URL:
\url{ [http://www.zlib.net/}] (дата обращения: 12.01.2017).
\bibitem{pus7} \emph{</ref> <ref name="cite-7">'''Ковалевский\,А.\,А.} А. А.''' Построение эквивалентного представления исходных текстов программ в форме, пригодной для выполнения анализов потока данных в потоке управления / Ковалевский\,А.\,А., Пустыгин\,А.\,Н., Ошнуров\,А. А. Ковалевский, А. Н.\,А. Пустыгин, Н. А. Ошнуров // Известия
Юго-Западного государственного университета. Серия: управление, вычислительная техника, информатика., медицинское
приборостроение. "---— 2015, №1 (14). "--- C— С. 28--–34.
\bibitem{pus8} \emph{</ref> <ref name="cite-8">'''Пустыгин\, А.\, Н.}''' Построение эквивалентного представления зависимостей классов, полей, методов, функций и их
перекрестного использования в исходных текстах программ. / А.\, Н.\, Пустыгин, А.\, А.\, Ковалевский, И.\, С.\, Белоусов // Одиннадцатая
конференция <<«Свободное программное обеспечение в высшей школе>> :». Материалы
конференции/. Переславль-Залесский, 30--–31 января 2016 года. — --- 120 с.: илл. Тезисы доклада С. 40--–44.
\end{thebibliography}
</latexref>
{{----}}
== Примечания и отзывы ==
<!-- <blockquote>[©]</blockquote> -->
{{fblink|1845644302355249}}
{{vklink|426}}
<references/>
[[File:{{#setmainimage:Использование системы выделенных признаков для задач поиска по исходному тесту (Алексей Пустыгин, OSEDUCONF-2017)!.jpg}}|center|640px]]
<!-- topub -->
{{stats|disqus_comments=0|refresh_time=2021-08-31T17:10:04.795526|vimeo_comments=0|vimeo_plays=4|youtube_comments=0|youtube_plays=26}}
[[Категория:OSEDUCONF-2017]]
[[Категория:ОбразованиеСтатический анализ кода]]
[[Категория:Open-source]] projects]] | |||
Текущая версия на 06:53, 20 октября 2025
Содержание
Аннотация
- Докладчик
- Алексей Пустыгин


В данном исследовании используются инструменты извлечения данных из открытого программного кода в целях поиска по условиям, формирование и формализация которых слишком сложны или невозможны иным способом. С этой целью строится эквивалентное представление исходного текста, являющееся набором неделимых блоков исходного текста. Использование системы выделенных признаков для блоков исходного текста показывает возможность контекстного поиска по синтаксическим признакам.
Видео
Слайды















Тезисы
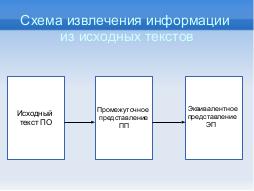
Задача статического анализа программных систем является одной из традиционных способов улучшения программ[1]. В предшествующих разработках[2] было предложено и реализовано универсальное промежуточное представление (УПП) открытого исходного текста, предназначенное для последующего преобразования, анализа и извлечения информации из исходного кода программ[3]. На основе этого набора данных был построен прототип генератора эквивалентного представления, предназначенный для решения некоторой совокупности задач над исходным текстом.
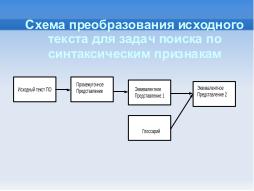
Алгоритм получения набора данных состоит из двух этапов преобразований. Сначала из УПП путём атрибутирования метками потока данных (операции над данными) и потока управления (вызовы, передача управления) получается эквивалентное представление UIRDCF[4]. На втором этапе последовательно просматривается глоссарий, и для каждой его записи выполняется модификация каждого кванта UIRDCF, если он соответствует шаблону признака из глоссария. Полученное эквивалентное представление назовём UDCFM.
Для тестирования использовались проекты с открытым исходным кодом pugixml[5], jsoncpp[6], lz4[7] и zlib[8].
Была предложена тестовая система признаков (глоссарий), сформированная из эвристических соображений, соответствующих алгоритмическому смыслу описываемого кванта.
Глоссарий признаков описывается в текстовом файле в формате XML-документа и разделён на две категории квантов: метод и класс. Каждая категория содержит набор шаблонов, соответствующих искомым признакам квантов, в виде блока условий:
<type name="<имя признака>" title="<описание признака>" [параметры признака]>
<node name="<имя тега>" [параметры условия]>
<attr name="<имя атрибута>" [параметры атрибута] />
…
</node>
…
</type>
Каждый узел условия конкретизирует свойства искомого признака кванта. Например, в категории «метод» для признака «получатель поля» (getter) заданы следующие условия шаблона:
<node name="MethodDecl">
<attr name="const" vb="true" />
<attr name="argc" vi="0"/>
</node>
<node name="FieldRef" tags="return" parent="this" />
Что соответствует:
- метод является константным;
- метод не имеет аргументов;
- поле объекта this напрямую возвращается оператором return.
Атрибут tags второго условия определяет набор меток из эквивалентного представления UDCFM, которым должен обладать узел УПП.
Формат шаблонов позволяет записывать условия, требующие семантического анализа, который дополнительно выполняется утилитой на первом этапе обработки запроса. Результат этого анализа записывается в метаданные узлов дерева разбора, к которым относится: принадлежность типу, принадлежность классу определения, узел дерева точки объявления. К метаданным добавляется информация UDCFM, которая включает в себя итеративно дополняемый список уже вычисленных признаков квантов на базе анализа предыдущих шаблонов.
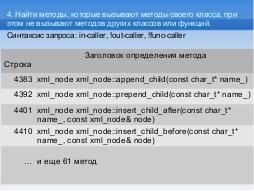
Предложенная система признаков разбивает достаточно крупный проект на некоторое количество уникальных групп квантов, то есть групп методов или классов. Например, для проекта pugixml с 621 методом количество групп методов составляет 200, а для проекта jsoncpp с 532 методами — 101.
Примеры выделенных признаков квантов исходного текста
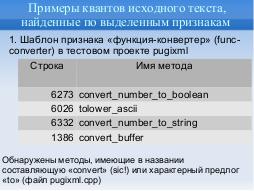
Для шаблона признака «функция-конвертер» (func-converter) в тестовом проекте pugixml утилита показывает методы, имеющие в названии составляющую «convert» (sic!) или характерный предлог «to» (см, таблицу ниже), что является симптоматичным совпадением, так как имена шаблонов не привязаны к именам идентификаторов. Признак «функция-конвертер» полностью соответствует 39 методам проекта и входит в 16 групп строгих дайджестов.
| Стр. | Имя метода |
|---|---|
| 6273 | convert_number_to_boolean |
| 6026 | tolower_ascii |
| 6332 | convert_number_to_string |
| 1386 | convert_buffer |
При поиске шаблона признака «проверяющая функция» (func-checker) в тестовом проекте pugixml находится функция
«check_string_to_number_format» (строка 6395, файл pugixml.cpp) с ключевым словом «check» в имени.
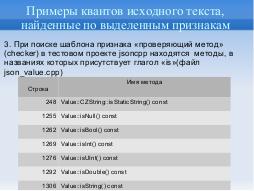
При поиске шаблона признака «проверяющий метод» (checker) в тестовом проекте jsoncpp находятся соответствующие методы, в названиях которых присутствует глагол «is».
| Стр. | Имя метода |
|---|---|
| 248 | Value::CZString::isStaticString() const |
| 1255 | Value::isNull() const |
| 1262 | Value::isBool() const |
| 1269 | Value::isInt() const |
| 1276 | Value::isUInt() const |
| 1292 | Value::isDouble() const |
| 1306 | Value::isString() const |
Например, метод Value::isBool в строке 1262 файла json_value.cpp сравнивает значение поля type_ с константой booleanValue и возвращает булевый результат сравнения.
| Стр. | Исходный текст |
|---|---|
| 1261 | bool |
| 1262 | Value::isBool() const |
| 1263 | { |
| 1264 | return type_ == booleanValue; |
| 1265 | } |
При поиске шаблона «сравнивающий метод» (comparator) в тестовом проекте pugixml находятся методы, выполняющие функцию перегруженных операторов сравнения.
| Стр. | Имя метода |
|---|---|
| 3738 | bool xml_attribute::operator==(const xml_attribute& r) const |
| 3743 | bool xml_attribute::operator!=(const xml_attribute& r) const |
| 3748 | bool xml_attribute::operator<(const xml_attribute& r) const |
| 3753 | bool xml_attribute::operator>(const xml_attribute& r) const |
| 3758 | bool xml_attribute::operator<=(const xml_attribute& r) const |
| 3763 | bool xml_attribute::operator>=(const xml_attribute& r) const |
| 3974 | bool xml_node::operator==(const xml_node& r) const |
| 3979 | bool xml_node::operator!=(const xml_node& r) const |
| 3984 | bool xml_node::operator<(const xml_node& r) const |
| 3989 | bool xml_node::operator>(const xml_node& r) const |
| 3994 | bool xml_node::operator<=(const xml_node& r) const |
| 3999 | bool xml_node::operator>=(const xml_node& r) const |
Например, метод operator== в строке 3738 файла pugixml.cpp сравнивает поле _attr передаваемого по ссылке параметра r объектного признака xml_attribute и поле _attr данного объекта.
| Стр. | Исходный текст |
|---|---|
| 3738 | bool xml_attribute::operator==(const xml_attribute& r) const |
| 3739 | { |
| 3740 | return (_attr == r._attr); |
| 3741 | } |
Выводы
На основе УПП [2] и дополненного эквивалентного представления UIRDCF [4] была введена тестовая система признаков и разработан прототип утилиты, которая выделяет признаки квантов исходного текста согласно применению набора шаблонов (глоссария) над эквивалентным представлением UDCFM, группирует кванты, строит разбиения по заданным параметрам, тем самым выделяя нетривиальные множества признаков, а также позволяет выполнять поиск квантов по заданным признакам.
Предложенный подход выделения признаков показал свою применимость для задач поиска квантов исходного текста по сложным или плохо формулируемым условиям. Целью такого поиска может быть поиск недокументированных возможностей и потенциально ошибочных участков кода, при введении соответствующих признаков и категорий для искомых частей исходного текста (классов, методов, блоков).
Литература
[1] [2] [5] [6] [7] [8] [4] [3]
Примечания и отзывы
- ↑ 1,0 1,1 Зубов М. В. Статический анализ ПО с помощью его промежуточных представлений и технологий с открытым исходным кодом / М. В. Зубов, А. Н. Пустыгин, Е. В. Старцев // Материалы 2-й Междунар. конф. «FOSS. Lviv-2012», Львов. — Львів: Сорока, 2012. — С. 165–168.
- ↑ 2,0 2,1 2,2 Ошнуров Н. А. Построение универсального промежуточного представления исходных текстов на языках C++ и C# / Н. А. Ошнуров, А. Н. Пустыгин, А. А. Ковалевский // Доклады Томского государственного университета систем управления и радиоэлектроники. — 2014. — Т. 33, № 3. — С. 135–139.
- ↑ 3,0 3,1 Пустыгин А. Н. Построение эквивалентного представления зависимостей классов, полей, методов, функций и их перекрестного использования в исходных текстах программ / А. Н. Пустыгин, А. А. Ковалевский, И. С. Белоусов // Одиннадцатая конференция «Свободное программное обеспечение в высшей школе». Материалы конференции. Переславль-Залесский, 30–31 января 2016 года. — С. 40–44.
- ↑ 4,0 4,1 4,2 Ковалевский А. А. Построение эквивалентного представления исходных текстов программ в форме, пригодной для выполнения анализов потока данных в потоке управления / А. А. Ковалевский, А. Н. Пустыгин, Н. А. Ошнуров // Известия Юго-Западного государственного университета. Серия: управление, вычислительная техника, информатика, медицинское приборостроение. — 2015, №1 (14). — С. 28–34.
- ↑ 5,0 5,1 Pugixml v1.2 — Light-weight, simple and fast XML parser for C++ with XPath support [Электронный ресурс]. URL: [1] (дата обращения: 12.01.2017).
- ↑ 6,0 6,1 Jsoncpp v0.5.0 C++ JSON parser [Электронный ресурс]. URL: [2] (дата обращения: 12.01.2017).
- ↑ 7,0 7,1 LZ4 r131 — Extremely fast compression [Электронный ресурс]. URL: [3] (дата обращения: 12.01.2017).
- ↑ 8,0 8,1 Zlib 1.2.8 — A Massively Spiffy Yet Delicately Unobtrusive Compression Library [Электронный ресурс]. URL: [4] (дата обращения: 12.01.2017).
!.jpg)
Plays:30
Comments:0