Построение планов параллельного выполнения программ для процессоров со сверхдлинным машинным словом (Валерий Баканов, OSSDEVCONF-2024) — различия между версиями
Материал из 0x1.tv
StasFomin (обсуждение | вклад) (Новая страница: «;{{SpeakerInfo}}: {{Speaker|Валерий Баканов}} <blockquote> </blockquote> {{VideoSection}} {{vimeoembed||800|450}} {{youtubelink|}} {{SlidesSectio…») |
StasFomin (обсуждение | вклад) ('вывод из драфта') |
||
| (не показано 5 промежуточных версий этого же участника) | |||
;{{SpeakerInfo}}: {{Speaker|Валерий Баканов}}
<blockquote>
Обсуждается метод получения планов (расписаний) параллельного выполнения программ для процессоров со сверхдлинным
машинным словом, основанный на информационном анализе конкретных алгоритмов. Используется естественный для данной
архитектуры метод получения Ярусно-Параллельных Форм (ЯПФ) для Информационного Графа Алгоритма (ИГА) с последующими
целенаправленными эквивалентными (не изменяющими информационных связей) преобразованиями к заданным параметрам
вычислительной системы.
Преобразования выполняются с использованием эвристических методов, которые описываются на
встроенном скриптовом языке (применена виртуальная Lua-машина); это обусловливается требованием большой гибкости при
поиске рациональных (близких к оптимальным) параметров процедур собственно преобразований.
Основными целевыми критериями являлись получение максимальной плотности кода (усреднённый процент использования слотов сверхдлинного
слова) и вычислительная трудоёмкость получения данного плана (расписания) параллельного выполнения. Дополнительно
анализировались размер и время существования внутренних (локальных) данных и оценивались операторы-претенденты для
помещения в кэш процессора.
В ходе исследований найдено интересное явление, заключающее в выгодности (в смысле
минимизации вычислительной трудоёмкости преобразований) использования ЯПФ в начальной т. н. «нижней» форме (когда все
операторы находятся на наиболее приближённых к концу выполнения программы ярусах ЯПФ).
</blockquote>
{{VideoSection}}
{{vimeoembed|1022635187|800|450}}
{{youtubelink|}}
|E0osMXWhv3Y}}
{{SlidesSection}}
[[File:Построение планов параллельного выполнения программ для процессоров со сверхдлинным машинным словом (Валерий Баканов, OSSDEVCONF-2024).pdf|left|page=-|300px]]
{{----}}
== Thesis ==
Процессоры архитектуры сверхдлинного машинного слова (VLIW — ''Very Long Instruction Word'') относятся к
специфическим классам архитектур, изначально нацеленным на использование внутреннего параллелизма в алгоритмах
(программах), причём параллелизм этот анализируется и планируется к рациональному использованию программными методами
(идеологема EPIC — ''Explicitly Parallel Instruction Computing'', явный параллелизм уровня машинных команд). При
этом собственно аппаратная часть процессора освобождается от процедур распараллеливания (и поэтому потенциально
должна стать проще и экономичнее применяющих внутреннее распараллеливание), а степень реализации потенциала
параллелизма благодаря использованию (более изобильных) программных ресурсов должна повыситься.
Несмотря на выпуклое преимущество (программным путём дешевле реализовать сложные процедуры параллелизации), работа
VLIW-процессоров сопряжена с известными проблемами. Так как аппаратно во VLIW-архитектуре уже заложена линейка
отдельных вычислительных ядер соответственно каждому слоту сверхдлинного слова, важным требованием является задача
максимальной загрузки вычислительной аппаратуры (этих ядер). Есть данные, что одной из серьёзных проблем Itanium’а
явилась как раз неприемлемо малая загрузка аппаратуры на некоторых типах алгоритмов.
В данной работе главенствующим принято направления
изучения свойств алгоритмов<ref name="algowiki">AlgoWiki. Открытая энциклопедия свойств алгоритмов. Под ред.: Воеводин В., Донгарра Дж. [http://algowiki-project.org]</ref> и исследуются пределы использования
свойства внутреннего (скрытого) их параллелизма, которые реально получить в ходе разработки планов параллельного
выполнения алгоритмов (программ) согласно предлагаемой методике.
Исследования развивают подход акад. Вал. Воеводина и Г. Поспелова, предполагающий получение «квинтэссэции»
(''экстракта'') программы в форме её ''алгоритма'' для анализа информационных (фактически причинно-следственных)
связей; отстранение от несущественных характеристик позволяет получать быстрый ответ на вопросы о важнейших
количественных показателях программы и производить целенаправленные эквивалентные (не изменяющие информационных связей
между действиями) преобразования в направлении согласования с параметрами архитектуры конкретных вычислительных систем
(напр., количеством вычислителей в параллельном вычислительном поле)<ref name="bakanov-1"><i>Баканов В. М</i>. Практический анализ алгоритмов и эффективность параллельных вычислений. — М.: Пробел-2000, 2023. — 198 с. URL: [https://www.litres.ru/book/v-m-bakanov/prakticheskiy-analiz-algoritmov-i-effektivnost-parallelnyh-vyc-70184365/]</ref>.
Исследовательским инструментом являлась программная система Практикум DF-SPF<ref name="bakanov-2"><i>V. M. Bakanov</i>. Software complex for modeling and optimization of program implementation on parallel calculation
systems. Open Computer Science, 2018, 8, Issue 1, Pages 228—234, DOI: [https://www.degruyter.com/document/doi/10.1515/comp-2018-0019/html] </ref>, специально созданная для данных
целей. Программные модули разработаны с использованием языка C/C++ в стиле GUI для модели Win’32, являются полностью
OpenSource<ref name="bakanov-repo">Исходные коды проекта Практикум DF-SPF. URL: [https://github.com/Valery-Bakanov/data-flow], [https://github.com/Valery-Bakanov/spf-home]</ref> и могут быть выгружены для свободного использования (формат инсталляционных файлов)<ref>
[http://vbakanov.ru/dataflow/content/install_df.exe], [http://vbakanov.ru/spf@home/content/install_spf.exe]</ref>. Вычислительные эксперименты проводились над набором оформленных в виде библиотеки программ (алгоритмов), реализующих наиболее часто применяющиеся (напр., линейной
алгебры); библиотека может неограниченно расширяться усилиями участников исследований. Условность выполнения операторов
реализуется ''предикатным'' методом (что позволяет избежать мультивариантности ЯПФ), программные циклы перед
выполнением разворачивались («<i>unrolling</i»>) с использованием макросов.
Естественным является метод представления каждого слота сверхдлинного командного слова соответствующим сечением ИГА с
выполнением последовательно по ярусам с начала до конца программы. Для получения рациональных (разумных, стремящихся к
оптимальным вследствие ''NP''-полноты задачи<ref name="gary-dj"><i>М. Гэри, Д. Джонсон</i>. Вычислительные машины и труднорешаемые задачи. — М.: Мир, 1982. — 416 с.</ref>) являются целенаправленные эквивалентные преобразования ЯПФ,
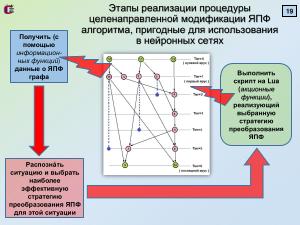
описываемые с использованием скриптового языка Lua<ref name="luaprog"><i>Иерузалимски Роберту</i>. Программирование на языке Lua. — М.: ДМК Пресс, 2014. — 382 c.</ref>. Основой создания этих сценариев является эвристический подход
совместно с итерационным методом движения в сторону повышения качества разрабатываемых планов параллельного выполнения
программ.
Усреднённая степень использования параллельных вычислительных ресурсов оценивалась ''пространственной''
''плотностью кода''. Для практического применения введена характеристика ''плотность кода'' (один из близких
аналогов — ''коэффициент полезного действия''), которую удобно оценивать <i>коэффициентом использования
параллельных вычислителей</i> (считая общее число таких вычислителей равным ширине ЯПФ).
''Основными'' характеристиками эффективности полученных планов считались следующие:
* ''пространственная плотность кода'' (уровень загрузки вычислительных ядер VLIW-процессора) — ''коэффициент использования параллельных вычислителей'',
* ''вычислительная сложность'' целенаправленного преобразования ЯПФ — число элементарных шагов преобразования (в качестве меры выбрано ''число перемещений операторов'' с яруса на ярус ЯПФ).
Дополнительно анализировалась полученная в результате преобразования высота ЯПФ (<i>параллельная вычислительная
сложность</i>) — оценка времени выполнения алгоритма (программы).
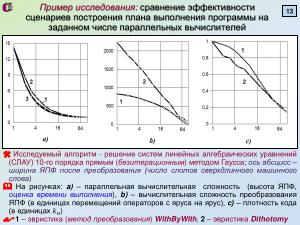
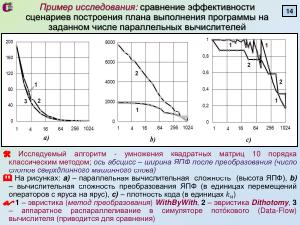
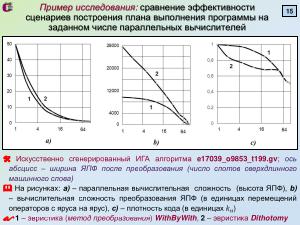
В ходе исследований были предложены две эвристики преобразования ЯПФ (''WithByWith'' и ''Dichotomy''), сильно
различающиеся по указанным характеристикам. Показано, что для VLIW-процессоров с размером слота сверхдлинного слова в
<m>4\div16</m> команд плотность кода изменяется в широком диапазоне (может доходить до <m>0,6\div1,0</m> с продолжающимся падением при
дальнейшим росте слота) и повышается с увеличением размеров обрабатываемых данных.
В целом стартующие от 0,8 значения плотности кода нельзя признать полностью удовлетворительным (вследствие малости).
„Светом в конце тоннеля“ может являться:
* факт улучшения качества получаемых планов параллельного выполнения программ с возрастанием ''размеров обрабатываемых данных'' (с ростом порядка матриц резко возрастает число степеней свободы в расположении операторов по ярусам ЯПФ),
* улучшение качества эвристик (автор ни в коей степени не считает, что достигнут оптимум при движении в этом направлении).
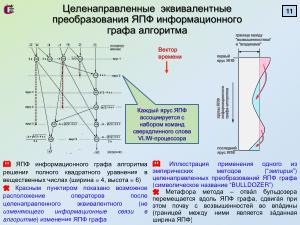
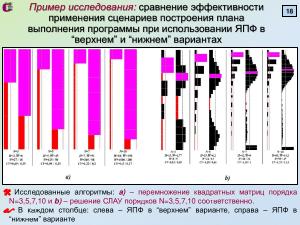
Обладающее перспективой является замеченное явление разницы между „верхним“ и „нижним“ ЯПФ. Оба варианта получения ЯПФ
(в первом случае все операторы максимально „прижаты“ к началу программы, во втором — к
концу оной; назовём их ЯПФ(в) и ЯПФ(н) соответственно) требуют одинаковой вычислительной сложности при получении, но
параметры их сильно отличаются. Характер диаграмм интенсивности вычислений для ЯПФ(в) сохраняется; в случае
использования ЯПФ(н) имеется явная тенденция к смещению максимума диаграмм ЯПФ к конечной части диаграммы (и
собственно неравномерности распределения). А раз вычислительная трудоёмкость получения ЯПФ(в) и ЯПФ(н) одинакова, есть
резон начинать процесс целенаправленной модификации с состояния именно ЯПФ(н), при этом основным направлением переноса
операторов будет «снизу вверх».
Программная система Практикум DF-SPF показала себя действенным исследовательским инструментом и разработчик заинтересован в
всемерном дальнейшем её распространении.
* http://vbakanov.ru/dataflow/
* http://vbakanov.ru/spf@home/
{{----}}
[[File:{{#setmainimage:Построение планов параллельного выполнения программ для процессоров со сверхдлинным машинным словом (Валерий Баканов, OSSDEVCONF-2024)!.jpg}}|center|640px]]
{{LinksSection}}
<!-- <blockquote>[©]</blockquote> -->
<references/>
[[Категория:OSSDEVCONF-2024]]
[[Категория:-source projects]]
[[Категория:Draft]]Параллельное программирование]] | |||
Текущая версия на 12:43, 3 марта 2026
- Докладчик
- Валерий Баканов
Обсуждается метод получения планов (расписаний) параллельного выполнения программ для процессоров со сверхдлинным машинным словом, основанный на информационном анализе конкретных алгоритмов. Используется естественный для данной архитектуры метод получения Ярусно-Параллельных Форм (ЯПФ) для Информационного Графа Алгоритма (ИГА) с последующими целенаправленными эквивалентными (не изменяющими информационных связей) преобразованиями к заданным параметрам вычислительной системы.
Преобразования выполняются с использованием эвристических методов, которые описываются на встроенном скриптовом языке (применена виртуальная Lua-машина); это обусловливается требованием большой гибкости при поиске рациональных (близких к оптимальным) параметров процедур собственно преобразований.
Основными целевыми критериями являлись получение максимальной плотности кода (усреднённый процент использования слотов сверхдлинного слова) и вычислительная трудоёмкость получения данного плана (расписания) параллельного выполнения. Дополнительно анализировались размер и время существования внутренних (локальных) данных и оценивались операторы-претенденты для помещения в кэш процессора.
В ходе исследований найдено интересное явление, заключающее в выгодности (в смысле минимизации вычислительной трудоёмкости преобразований) использования ЯПФ в начальной т. н. «нижней» форме (когда все операторы находятся на наиболее приближённых к концу выполнения программы ярусах ЯПФ).
Содержание
Видео
Презентация









Thesis
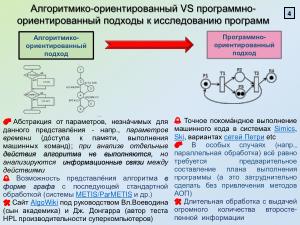
Процессоры архитектуры сверхдлинного машинного слова (VLIW — Very Long Instruction Word) относятся к специфическим классам архитектур, изначально нацеленным на использование внутреннего параллелизма в алгоритмах (программах), причём параллелизм этот анализируется и планируется к рациональному использованию программными методами (идеологема EPIC — Explicitly Parallel Instruction Computing, явный параллелизм уровня машинных команд). При этом собственно аппаратная часть процессора освобождается от процедур распараллеливания (и поэтому потенциально должна стать проще и экономичнее применяющих внутреннее распараллеливание), а степень реализации потенциала параллелизма благодаря использованию (более изобильных) программных ресурсов должна повыситься.
Несмотря на выпуклое преимущество (программным путём дешевле реализовать сложные процедуры параллелизации), работа VLIW-процессоров сопряжена с известными проблемами. Так как аппаратно во VLIW-архитектуре уже заложена линейка отдельных вычислительных ядер соответственно каждому слоту сверхдлинного слова, важным требованием является задача максимальной загрузки вычислительной аппаратуры (этих ядер). Есть данные, что одной из серьёзных проблем Itanium’а явилась как раз неприемлемо малая загрузка аппаратуры на некоторых типах алгоритмов.
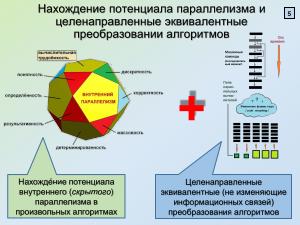
В данной работе главенствующим принято направления изучения свойств алгоритмов[1] и исследуются пределы использования свойства внутреннего (скрытого) их параллелизма, которые реально получить в ходе разработки планов параллельного выполнения алгоритмов (программ) согласно предлагаемой методике.
Исследования развивают подход акад. Вал. Воеводина и Г. Поспелова, предполагающий получение «квинтэссэции» (экстракта) программы в форме её алгоритма для анализа информационных (фактически причинно-следственных) связей; отстранение от несущественных характеристик позволяет получать быстрый ответ на вопросы о важнейших количественных показателях программы и производить целенаправленные эквивалентные (не изменяющие информационных связей между действиями) преобразования в направлении согласования с параметрами архитектуры конкретных вычислительных систем (напр., количеством вычислителей в параллельном вычислительном поле)[2].
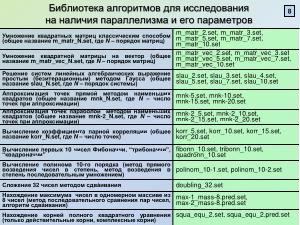
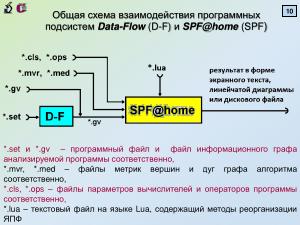
Исследовательским инструментом являлась программная система Практикум DF-SPF[3], специально созданная для данных целей. Программные модули разработаны с использованием языка C/C++ в стиле GUI для модели Win’32, являются полностью OpenSource[4] и могут быть выгружены для свободного использования (формат инсталляционных файлов)[5]. Вычислительные эксперименты проводились над набором оформленных в виде библиотеки программ (алгоритмов), реализующих наиболее часто применяющиеся (напр., линейной алгебры); библиотека может неограниченно расширяться усилиями участников исследований. Условность выполнения операторов реализуется предикатным методом (что позволяет избежать мультивариантности ЯПФ), программные циклы перед выполнением разворачивались («unrolling</i»>) с использованием макросов.
Естественным является метод представления каждого слота сверхдлинного командного слова соответствующим сечением ИГА с выполнением последовательно по ярусам с начала до конца программы. Для получения рациональных (разумных, стремящихся к оптимальным вследствие NP-полноты задачи[6]) являются целенаправленные эквивалентные преобразования ЯПФ, описываемые с использованием скриптового языка Lua[7]. Основой создания этих сценариев является эвристический подход совместно с итерационным методом движения в сторону повышения качества разрабатываемых планов параллельного выполнения программ.
Усреднённая степень использования параллельных вычислительных ресурсов оценивалась пространственной плотностью кода. Для практического применения введена характеристика плотность кода (один из близких аналогов — коэффициент полезного действия), которую удобно оценивать <i>коэффициентом использования параллельных вычислителей (считая общее число таких вычислителей равным ширине ЯПФ).
Основными характеристиками эффективности полученных планов считались следующие:
- пространственная плотность кода (уровень загрузки вычислительных ядер VLIW-процессора) — коэффициент использования параллельных вычислителей,
- вычислительная сложность целенаправленного преобразования ЯПФ — число элементарных шагов преобразования (в качестве меры выбрано число перемещений операторов с яруса на ярус ЯПФ).
Дополнительно анализировалась полученная в результате преобразования высота ЯПФ (параллельная вычислительная
сложность) — оценка времени выполнения алгоритма (программы).
В ходе исследований были предложены две эвристики преобразования ЯПФ (WithByWith и Dichotomy), сильно различающиеся по указанным характеристикам. Показано, что для VLIW-процессоров с размером слота сверхдлинного слова в команд плотность кода изменяется в широком диапазоне (может доходить до с продолжающимся падением при дальнейшим росте слота) и повышается с увеличением размеров обрабатываемых данных.
В целом стартующие от 0,8 значения плотности кода нельзя признать полностью удовлетворительным (вследствие малости). „Светом в конце тоннеля“ может являться:
- факт улучшения качества получаемых планов параллельного выполнения программ с возрастанием размеров обрабатываемых данных (с ростом порядка матриц резко возрастает число степеней свободы в расположении операторов по ярусам ЯПФ),
- улучшение качества эвристик (автор ни в коей степени не считает, что достигнут оптимум при движении в этом направлении).
Обладающее перспективой является замеченное явление разницы между „верхним“ и „нижним“ ЯПФ. Оба варианта получения ЯПФ (в первом случае все операторы максимально „прижаты“ к началу программы, во втором — к концу оной; назовём их ЯПФ(в) и ЯПФ(н) соответственно) требуют одинаковой вычислительной сложности при получении, но параметры их сильно отличаются. Характер диаграмм интенсивности вычислений для ЯПФ(в) сохраняется; в случае использования ЯПФ(н) имеется явная тенденция к смещению максимума диаграмм ЯПФ к конечной части диаграммы (и собственно неравномерности распределения). А раз вычислительная трудоёмкость получения ЯПФ(в) и ЯПФ(н) одинакова, есть резон начинать процесс целенаправленной модификации с состояния именно ЯПФ(н), при этом основным направлением переноса операторов будет «снизу вверх».
Программная система Практикум DF-SPF показала себя действенным исследовательским инструментом и разработчик заинтересован в всемерном дальнейшем её распространении.
!.jpg)
Примечания и ссылки
- ↑ AlgoWiki. Открытая энциклопедия свойств алгоритмов. Под ред.: Воеводин В., Донгарра Дж. [1]
- ↑ Баканов В. М. Практический анализ алгоритмов и эффективность параллельных вычислений. — М.: Пробел-2000, 2023. — 198 с. URL: [2]
- ↑ V. M. Bakanov. Software complex for modeling and optimization of program implementation on parallel calculation systems. Open Computer Science, 2018, 8, Issue 1, Pages 228—234, DOI: [3]
- ↑ Исходные коды проекта Практикум DF-SPF. URL: [4], [5]
- ↑ [6], [7]
- ↑ М. Гэри, Д. Джонсон. Вычислительные машины и труднорешаемые задачи. — М.: Мир, 1982. — 416 с.
- ↑ Иерузалимски Роберту. Программирование на языке Lua. — М.: ДМК Пресс, 2014. — 382 c.