Оптимизация СПО для платформы Эльбрус (OSSDEVCONF-2021) — различия между версиями
Материал из 0x1.tv
StasFomin (обсуждение | вклад) (Новая страница: «;{{SpeakerInfo}}: * {{Speaker|Михаил Шигорин}} * {{Speaker|Андрей Савченко}} <blockquote> </blockquote> {{VideoSection}} {{vimeoembe…») |
StasFomin (обсуждение | вклад) |
||
| (не показано 11 промежуточных версий этого же участника) | |||
;{{SpeakerInfo}}:;{{SpeakerInfo}}: * {{Speaker|Михаил Шигорин}} * {{Speaker|Андрей Савченко}} <blockquote> Рассмотрены различные методы оптимизации ПО для архитектуры Эльбрус. Представлены результаты оптимизации СПО проектов и даются практические рекомендации по подобной работе. </blockquote> {{VideoSection}} {{vimeoembed|64297725|800|450}} {{youtubelink|}} |KmEyOXX5Or4}} {{SlidesSection}} [[File:Оптимизация СПО для платформы Эльбрус (OSSDEVCONF-2021).pdf|left|page=-|300px]] {{----}} == Thesis == === Введение === Эльбрус (e2000, e2k), в отличие от большинства других архитектур, использует набор инструкций с широким командным словом (VLIW) и позволяет выполнять десятки команд общего назначения за такт (до 25 для 4-го поколения, до 50 для 5-го). Это свойства приводят к гораздо более сильной зависимости производительности кода от степени его оптимизации как компилятором, так и программистом, c учётом особенностей архитектуры. Рассмотрим способы оптимизации кода от простого к сложному. === Новые версии компилятора === Внутренний параллелизм и оптимальное заполнение VLIW — сложная задача, поэтому даже без изменения кода можно получить его существенное ускорение, используя последнее поколение компилятора. Например, прирост производительности между lcc-1.10 и lcc-1.25 составляет <tt>2.05</tt> раз для целочисленных вычислений и <tt>3.58</tt> раз для плавающей запятой<ref>Прирост производительности за счёт оптимизации компилятора <tt>https://www.altlinux.org/lcc#/media/File:Lcc-performance.jpg</tt></ref>. === Оптимизация для целевого процессора === lcc позволяет компилировать как приложения, работающие на любой архитектуре, начиная с заданной (<code>-march</code>), так и для конкретной модели процессора (<code>-mtune</code>). Во втором случае код получается быстрее, но он не будет работать на других моделях процессоров. Эксперименты с ядром показали прирост от <tt>0.5%</tt> (мало, но статистически достоверно), до <tt>8%</tt> в случае с 1С+. === Профилирование === Профилирование по семантике аналогично gcc (<code>-fprofile-generate</code>, <code>-fprofile-use</code>), но сложнее в практической эксплуатации. Для xz получен прирост <math display="inline">\sim 13 %</math>. Код доступен в Сизифе<ref>xz: поддержка профилирования на e2k http://git.altlinux.org/gears/x/xz.git?p=xz.git;a=commit;h=7ed55a11d0643c5b53234c700163b72a41a7af30</ref>, где можно посмотреть пример практического применения и обхода проблем. === Использование SIMD === Для SIMD оптимизаций предпочтительно использовать интринсики (встроенные фукнции компилятора), а не писать всё на непосредственно на ассмеблере. Основные особенности: == Векторные команды x86 == SIMD команды Эльбруса копируют векторные команды x86, но есть различия: * Нет варианта некоторых команд, например <code>_mm_dp_ps()</code>, она эмулируется компилятором, поэтому будет работать медленно. * Операция Shuffle на Эльбрусе может использовать таблицу в 2 регистра, поэтому можно написать более эффективный код. == Векторные интринсики x86 == lcc понимает интринсики от MMX до AVX2, используя эквивалентные команды для Эльбруса. Если эквивалента не будет, то будет использована медленная эмуляция. == Особенности архитектур == '''v3,v4''': 64-х разрядные регистры и поддержку почти всех SSE4.1 команд, одна векторная инструкция вычисляет только 64-бит результата. Медленно читает невыровненные данные, в том числе если данные выровнены, но компилятор об этом не знает. '''v5''': регистры 128-разрядные, появились эквиваленты векторных команд, которые обрабатывают 128-бит. Быстрее читает невыровненные данные. '''v6''': предполагается ускорение работы с невыровненными данными. == Выбор интринсиков == Удобнее использовать интринсики x86, чем Эльбруса: * Их можно скомпилировать как для v3 так и для v5, для эмуляции SSE интринсика компилятор сгенерирует одну команду для v5 и две команды для v3. На v3 будет использовано в два раза больше регистров. Но регистров у Эльбруса много (256). Зато не нужно писать отдельные версии кода для v3 и v5, что сокращает разработку. * Оптимизацию можно разрабатывать и отлаживать на x86, лишь в финале проверяя на Эльбрусе. Небольшая часть вещей специфичных для Эльбруса выносится в макросы (которые эмулируют то же самое на x86). * AVX команды эмулируются тем же образом, как SSE на v3. Использовать не рекомендуется из-за большого перерасхода регистров. == Зависимости между данными == Компилятор для Эльруса должен заранее знать об отсутствии зависимости между данными чтобы сгенерировать быстрый код. Например, для кода: <pre>for (i = 0; i < n; i++) dst[i] = src[i] + x;</pre> компилятор не знает, существует ли зависимость между данными (например, что <code>dst</code> будет указывать на <code>src + 1</code>). Поэтому вставит ожидание между записью dst и чтением src из следующей итерации. Чтобы этого не происходило, нужно указывать <code>#pragma ivdep</code> перед циклом. == Выравнивание данных == В lcc-1.25 не работают<code>__attribute__((aligned(N)))</code> или <code>__builtin_assume_aligned(ptr, N)</code>, но есть два способа этого добиться: # Опция lcc <code>-faligned</code>, но тогда любые указатели будет считаться выровненными, что неудобно и опасно в больших проектах. # Прямой сброс младших бит указателя: <code>ptr = (T*)((intptr_t)ptr & -8);</code> тогда LCC понимает что память выровнена. Но если придёт невыровненный указатель то не будет ошибки, но будут неправильные вычисления, или придётся добавить assert (что лишний код, замедлит при использовании в цикле). Также это лишняя операция AND, что критично в части кода (например циклы или макросы). === Оптимизированное СПО === На Эльбрус портированы или оптимизированы д14 популярных СПО проектов<ref>Патчи оптимизации для e2k разного СПО https://github.com/ilyakurdyukov/e2k-ports</ref>, включая ffmpeg, x264, libjpeg-turbo — всего 33 тыс. строк, 1.3 МБ исходного кода. Они уже доступны в Сизифе, ведётся взаимодействие с апстримами. {|class=wikitable ! Аудио !align="right"| mp3 !align="right"| aac !align="right"| ogg !align="right"| opus |- | base |align="right"| 1.17 |align="right"| 1.26 |align="right"| 1.57 |align="right"| 2.62 |- | mcst |align="right"| 1.30 |align="right"| 1.40 |align="right"| 1.76 |align="right"| 2.84 |- | open |align="right"| 0.98 |align="right"| 0.94 |align="right"| 1.23 |align="right"| 2.23 |} {|class=wikitable ! Видео !align="right"| mpeg2 !align="right"| mpeg4 !align="right"| xvid !align="right"| avc !align="right"| vp9 !align="right"| hevc |- | base |align="right"| 51.55 |align="right"| 53.17 |align="right"| 57.07 |align="right"| 88.58 |align="right"| 121.81 |align="right"| 144.38 |- | mcst |align="right"| 40.20 |align="right"| 41.16 |align="right"| 45.33 |align="right"| 61.53 |align="right"| 123.61 |align="right"| 143.45 |- | open |align="right"| 28.78 |align="right"| 28.14 |align="right"| 30.62 |align="right"| 52.46 |align="right"| 57.34 |align="right"| 72.40 |} Результаты для основных кодеков в сёк (меньше — лучше) в режиме декодирования. Тестировалось на 720p, 201 сёк. base — исходный код, mcst — бинарные файлы МЦСТ, open — опубликованное открытое решение. {{----}} [[File:{{#setmainimage:Оптимизация СПО для платформы Эльбрус (OSSDEVCONF-2021)!.jpg}}|center|640px]] {{LinksSection}} <!-- <blockquote>[©]</blockquote> --> {{fblink|2965540557032279}} {{vklink|1873}} <references/> * Эльбрус upstream https://www.altlinux.org/Эльбрус/upstream {{stats|disqus_comments=0|refresh_time=2021-08-31T17:40:56.261954|vimeo_plays=0|youtube_plays=0}} [[Категория:OSSDEVCONF-2021]] [[Категория:Open-source projects]]ALTLinux на Эльбрусе]] [[Категория:Эльбрус]] | |||
Текущая версия на 00:44, 20 мая 2022
- Докладчик


Рассмотрены различные методы оптимизации ПО для архитектуры Эльбрус. Представлены результаты оптимизации СПО проектов и даются практические рекомендации по подобной работе.
Содержание
Видео
Презентация














Thesis
Введение
Эльбрус (e2000, e2k), в отличие от большинства других архитектур, использует набор инструкций с широким командным словом (VLIW) и позволяет выполнять десятки команд общего назначения за такт (до 25 для 4-го поколения, до 50 для 5-го). Это свойства приводят к гораздо более сильной зависимости производительности кода от степени его оптимизации как компилятором, так и программистом, c учётом особенностей архитектуры.
Рассмотрим способы оптимизации кода от простого к сложному.
Новые версии компилятора
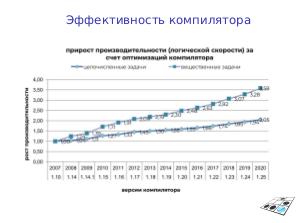
Внутренний параллелизм и оптимальное заполнение VLIW — сложная задача, поэтому даже без изменения кода можно получить его существенное ускорение, используя последнее поколение компилятора. Например, прирост производительности между lcc-1.10 и lcc-1.25 составляет 2.05 раз для целочисленных вычислений и 3.58 раз для плавающей запятой[1].
Оптимизация для целевого процессора
lcc позволяет компилировать как приложения, работающие на любой архитектуре, начиная с заданной (-march), так и для конкретной модели процессора (-mtune). Во втором случае код получается быстрее, но он не будет работать на других моделях процессоров. Эксперименты с ядром показали прирост от 0.5% (мало, но статистически достоверно), до 8% в случае с 1С+.
Профилирование
Профилирование по семантике аналогично gcc (-fprofile-generate, -fprofile-use), но сложнее в практической эксплуатации. Для xz получен прирост . Код доступен в Сизифе[2], где можно посмотреть пример практического применения и обхода проблем.
Использование SIMD
Для SIMD оптимизаций предпочтительно использовать интринсики (встроенные фукнции компилятора), а не писать всё на непосредственно на ассмеблере. Основные особенности:
Векторные команды x86
SIMD команды Эльбруса копируют векторные команды x86, но есть различия:
- Нет варианта некоторых команд, например
_mm_dp_ps(), она эмулируется компилятором, поэтому будет работать медленно. - Операция Shuffle на Эльбрусе может использовать таблицу в 2 регистра, поэтому можно написать более эффективный код.
Векторные интринсики x86
lcc понимает интринсики от MMX до AVX2, используя эквивалентные команды для Эльбруса. Если эквивалента не будет, то будет использована медленная эмуляция.
Особенности архитектур
v3,v4: 64-х разрядные регистры и поддержку почти всех SSE4.1 команд, одна векторная инструкция вычисляет только 64-бит результата. Медленно читает невыровненные данные, в том числе если данные выровнены, но компилятор об этом не знает.
v5: регистры 128-разрядные, появились эквиваленты векторных команд, которые обрабатывают 128-бит. Быстрее читает невыровненные данные.
v6: предполагается ускорение работы с невыровненными данными.
Выбор интринсиков
Удобнее использовать интринсики x86, чем Эльбруса:
- Их можно скомпилировать как для v3 так и для v5, для эмуляции SSE интринсика компилятор сгенерирует одну команду для v5 и две команды для v3. На v3 будет использовано в два раза больше регистров. Но регистров у Эльбруса много (256). Зато не нужно писать отдельные версии кода для v3 и v5, что сокращает разработку.
- Оптимизацию можно разрабатывать и отлаживать на x86, лишь в финале проверяя на Эльбрусе. Небольшая часть вещей специфичных для Эльбруса выносится в макросы (которые эмулируют то же самое на x86).
- AVX команды эмулируются тем же образом, как SSE на v3. Использовать не рекомендуется из-за большого перерасхода регистров.
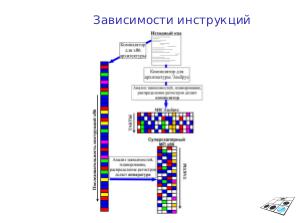
Зависимости между данными
Компилятор для Эльруса должен заранее знать об отсутствии зависимости между данными чтобы сгенерировать быстрый код. Например, для кода:
for (i = 0; i < n; i++) dst[i] = src[i] + x;
компилятор не знает, существует ли зависимость между данными (например, что dst будет указывать на src + 1). Поэтому вставит ожидание между записью dst и чтением src из следующей итерации. Чтобы этого не происходило, нужно указывать #pragma ivdep перед циклом.
Выравнивание данных
В lcc-1.25 не работают__attribute__((aligned(N))) или __builtin_assume_aligned(ptr, N), но есть два способа этого добиться:
- Опция lcc
-faligned, но тогда любые указатели будет считаться выровненными, что неудобно и опасно в больших проектах. - Прямой сброс младших бит указателя:
ptr = (T*)((intptr_t)ptr & -8);тогда LCC понимает что память выровнена. Но если придёт невыровненный указатель то не будет ошибки, но будут неправильные вычисления, или придётся добавить assert (что лишний код, замедлит при использовании в цикле). Также это лишняя операция AND, что критично в части кода (например циклы или макросы).
Оптимизированное СПО
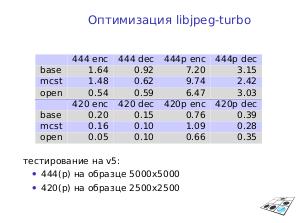
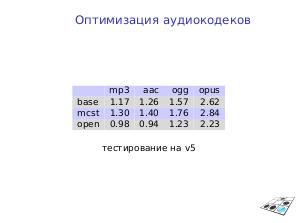
На Эльбрус портированы или оптимизированы д14 популярных СПО проектов[3], включая ffmpeg, x264, libjpeg-turbo — всего 33 тыс. строк, 1.3 МБ исходного кода. Они уже доступны в Сизифе, ведётся взаимодействие с апстримами.
| Аудио | mp3 | aac | ogg | opus |
|---|---|---|---|---|
| base | 1.17 | 1.26 | 1.57 | 2.62 |
| mcst | 1.30 | 1.40 | 1.76 | 2.84 |
| open | 0.98 | 0.94 | 1.23 | 2.23 |
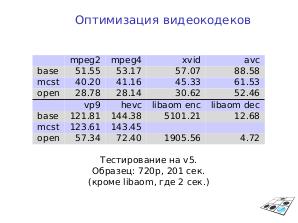
| Видео | mpeg2 | mpeg4 | xvid | avc | vp9 | hevc |
|---|---|---|---|---|---|---|
| base | 51.55 | 53.17 | 57.07 | 88.58 | 121.81 | 144.38 |
| mcst | 40.20 | 41.16 | 45.33 | 61.53 | 123.61 | 143.45 |
| open | 28.78 | 28.14 | 30.62 | 52.46 | 57.34 | 72.40 |
Результаты для основных кодеков в сёк (меньше — лучше) в режиме декодирования. Тестировалось на 720p, 201 сёк. base — исходный код, mcst — бинарные файлы МЦСТ, open — опубликованное открытое решение.
!.jpg)
Примечания и ссылки
- ↑ Прирост производительности за счёт оптимизации компилятора https://www.altlinux.org/lcc#/media/File:Lcc-performance.jpg
- ↑ xz: поддержка профилирования на e2k http://git.altlinux.org/gears/x/xz.git?p=xz.git;a=commit;h=7ed55a11d0643c5b53234c700163b72a41a7af30
- ↑ Патчи оптимизации для e2k разного СПО https://github.com/ilyakurdyukov/e2k-ports
{kind=link}
- Эльбрус upstream https://www.altlinux.org/Эльбрус/upstream
Plays:0 Comments:0