Высокопроизводительные гибкие аллокаторы динамической памяти для сложных проектов (Илья Труб, ISPRASOPEN-2019) — различия между версиями
Материал из 0x1.tv
StasFomin (обсуждение | вклад) |
StasFomin (обсуждение | вклад) |
||
| (не показано 10 промежуточных версий этого же участника) | |||
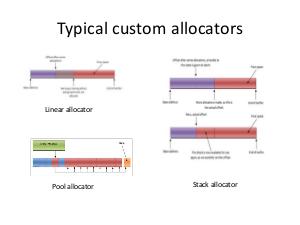
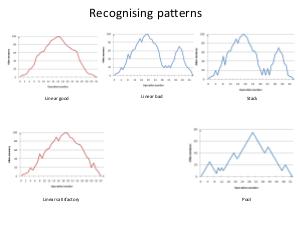
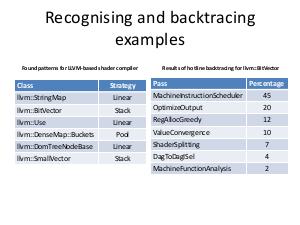
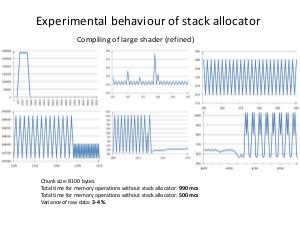
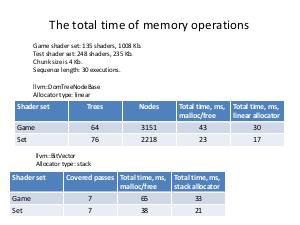
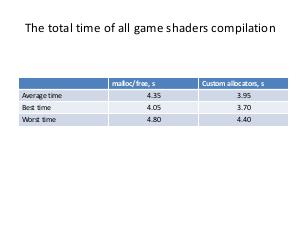
The appropriate custom allocator is more effective than malloc, in particular, linear allocator for StringMap and DomTreeNodeBase, stack allocator for BitVector and linked list allocator for Buckets. Aggregate performance improvement reaches around 10%. Practical results of work are implemented in shaders' compiler, but this methodology can be used in any project, which uses LLVM or, generally, performs memory requests more or less intensively.
</blockquote>
{{VideoSection}}
{{vimeoembed|378880554|800|450}}
{{youtubelink|}}{{letscomment}}|i7ofsQz6CjI}}
{{SlidesSection}}
[[File:Высокопроизводительные гибкие аллокаторы динамической памяти для сложных проектов (Илья Труб, ISPRASOPEN-2019).pdf|left|page=-|300px]]
{{----}}
[[File:{{#setmainimage:Высокопроизводительные гибкие аллокаторы динамической памяти для сложных проектов (Илья Труб, ISPRASOPEN-2019)!.jpg}}|center|640px]]
{{LinksSection}}
<!-- * [ Talks page on site] -->
<!-- <blockquote>[©]</blockquote> -->
{{fblink|2464875710432102}}
{{vklink|1663}}
<references/>
<!-- topub -->
[[Категория:ISPRASOPEN-2019]]
[[Категория:Разработка операционных систем]]
[[Категория:C++]]
{{stats|disqus_comments=0|refresh_time=2020-01-09T16:04:022021-08-31T16:56:13.375027352932|vimeo_plays=14|youtube_comments=5|youtube_plays=0}}54}} | |||
Текущая версия на 06:35, 20 октября 2025
- Докладчик
- Илья Труб


Proposes the methodology of data analysis and code design solutions that improve flexibility of custom allocator assignment for simple data types and instances of data type classes. The methodology is based on special wrappers of memory functions, collecting data by execution of source code, and analyzing allocation/release traces with subsequent patterns extraction. Then the corresponding custom allocator is chosen for each found pattern and implemented in some module of source code as a container for user data, replacing malloc/free. The article describes the usage of the proposed approach for LLVM (Low Level Virtual Machine), that is well known tool for building compilers. It is shown that the choice of appropriate allocator provides the improvement of LLVM-based compiler's performance.
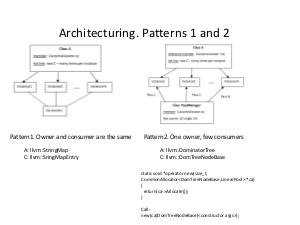
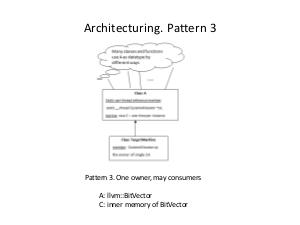
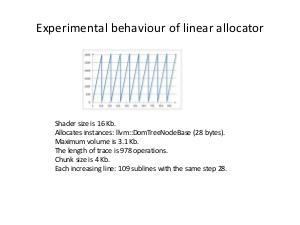
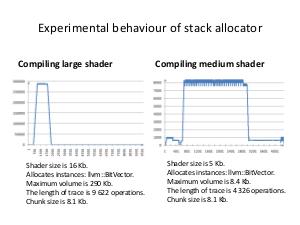
The appropriate custom allocator is more effective than malloc, in particular, linear allocator for StringMap and DomTreeNodeBase, stack allocator for BitVector and linked list allocator for Buckets. Aggregate performance improvement reaches around 10%. Practical results of work are implemented in shaders' compiler, but this methodology can be used in any project, which uses LLVM or, generally, performs memory requests more or less intensively.
Видео
Презентация











!.jpg)
Примечания и ссылки
Plays:68 Comments:5