Автоматический выбор оптимального набора журналов для отчетов об ошибках (Денис Силаков, SECR-2019) — различия между версиями
Материал из 0x1.tv
StasFomin (обсуждение | вклад) |
StasFomin (обсуждение | вклад) (Batch edit: replace PCRE (\n\n)+(\n) with \2) |
||
| (не показано 13 промежуточных версий этого же участника) | |||
;{{SpeakerInfo}}: {{Speaker|Денис Силаков}}
<blockquote>
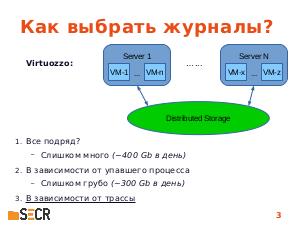
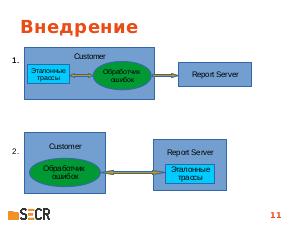
В данной работе рассматривается использование машинного обучения в целях оптимизации отчетов об ошибках и включения в них только тех журналов и файлов, которые реально понадобятся для анализа конкретной ошибки. Выбор файлов осуществляется на основе анализа схожести последовательности функций, приведших к падению, с эталонным набором. Предложенный метод прошел успешную апробацию в продуктах нашей компании и может быть полезен всем разработчикам, сталкивающимся с проблемой чрезмерного количества информации, которую хочется поместить в отчет для ошибки «на всякий случай». Доклад будет интересен как исследователям в области машинного обучения, так и инженерам, занимающихся анализом падений программ и сталкивающихся как с задачей сравнения различных падений, так и с отбором лог-файлов для их анализа.
</blockquote>
{{VideoSection}}
{{vimeoembed|366000289|800|450}}
{{youtubelink|}}|Bp5vyNqRueg}}
{{letscomment}}
{{SlidesSection}}
[[File:Автоматический выбор оптимального набора журналов для отчетов об ошибках (Денис Силаков, SECR-2019).pdf|left|page=-|300px]]
{{----}}
[[File:{{#setmainimage:Автоматический выбор оптимального набора журналов для отчетов об ошибках (Денис Силаков, SECR-2019)!.jpg}}|center|640px]]
{{LinksSection}}
* [https://2019.secrus.org/program/submitted-presentations/automated-method-for-collecting-optimal-set-of-log-files-for-crash-reports/ Talks page on SECR site]
<!-- <blockquote>[©]</blockquote> -->
{{fblink|2457284357857904}}
{{vklink|1500}}
<references/>
<!-- topub -->
[[Категория:SECR-2019]]
[[Категория:Мониторинг]]
[[Категория:Machine Learning]]
{{stats|disqus_comments=0|refresh_time=2021-08-31T16:46:10.573621|vimeo_plays=14|youtube_comments=0|youtube_plays=13}} | |||
Текущая версия на 12:20, 4 сентября 2021
- Докладчик
- Денис Силаков


В данной работе рассматривается использование машинного обучения в целях оптимизации отчетов об ошибках и включения в них только тех журналов и файлов, которые реально понадобятся для анализа конкретной ошибки. Выбор файлов осуществляется на основе анализа схожести последовательности функций, приведших к падению, с эталонным набором. Предложенный метод прошел успешную апробацию в продуктах нашей компании и может быть полезен всем разработчикам, сталкивающимся с проблемой чрезмерного количества информации, которую хочется поместить в отчет для ошибки «на всякий случай». Доклад будет интересен как исследователям в области машинного обучения, так и инженерам, занимающихся анализом падений программ и сталкивающихся как с задачей сравнения различных падений, так и с отбором лог-файлов для их анализа.
Видео
Посмотрели доклад? Понравился? Напишите комментарий! Не согласны? Тем более напишите.
Презентация










!.jpg)
Примечания и ссылки
Plays:27 Comments:0