Data Science for Network Security (Дмитрий Орехов, LVEE-2015) — различия между версиями
Материал из 0x1.tv
StasFomin (обсуждение | вклад) (Новая страница: «== Аннотация == ;Докладчик: {{Speaker|Дмитрий Орехов}} <blockquote> </blockquote> == Видео == {{vimeoembed|130298919|800|450…») |
StasFomin (обсуждение | вклад) |
||
== Аннотация ==
;Докладчик: {{Speaker|Дмитрий Орехов}}
<blockquote>
Today network traffic is absolutely out of human control, this is something that human mind cannot manage. On the other hand, network security becomes more and more important, since more and more of human activities are moving to the Network. The solution could be a software, which is able to learn from past Data incoming, and then to make assumptions about new Data and predictions about the future. Though algorithms for this domain are well-known, there is a problem to implement them, because they are often very resource-consuming. Fortunately, cloud technologies now afford building cheap and productive clusters, and Open Source solutions like Spark provide a powerful tool to build advanced analytics software on top of them.
</blockquote>
== Видео ==
{{vimeoembed|130298919|800|450}}
{{LVEE-2015-draft}}
== Слайды ==
[[File:Data Science for Network Security (Дмитрий Орехов, LVEE-2015).pdf|left|page=-|256px]]
{{----}}
== Тезисы ==
=== Data collecting ===
The first important task for Network Analytics building is a data collection facility. The main idea is to place sensors, which collect statistics data and send it to be collect and analyze.
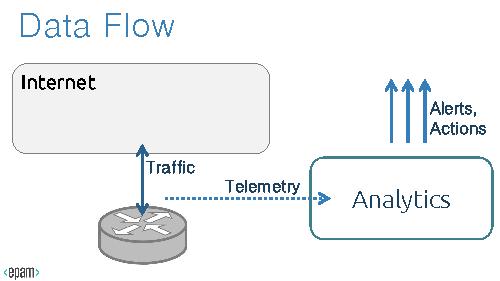
;Statistics collection: the big picture:
[[File:datascience4netsecurity-lvee2015-015-06-14_235902.jpg]]
==== Sensors ====
Sensors are classified by Vantage and Domain.
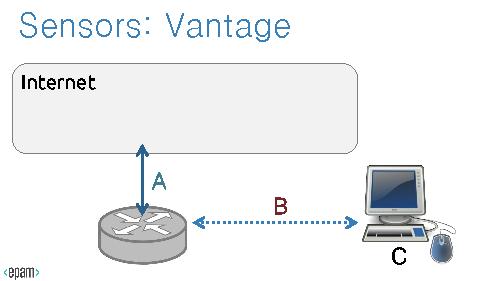
'''Vantage''' is a placement of sensors within a network. Sensors with different vantages would see different parts of the same events.
;Vantages:
[[File:datascience4netsecurity-lvee2015-015-06-15_083937.jpg]]
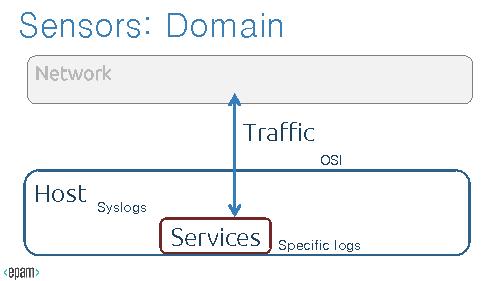
'''Domain''' defines, which part of thraffic statistics and metrics to collect. In the other words, it’s the information the sensor provides, whether that’s at the host, a service on the host, or the network. Sensors with the same vantage but different domains provide complementary data about the same event. For some events, you might only get information from one domain.
[[File:datascience4netsecurity-lvee2015-015-06-15_084059.jpg]]
'''Domains'''
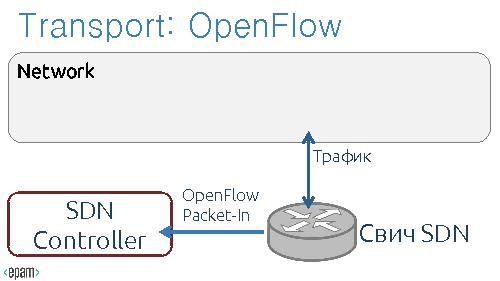
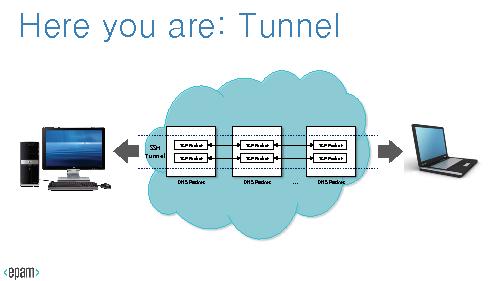
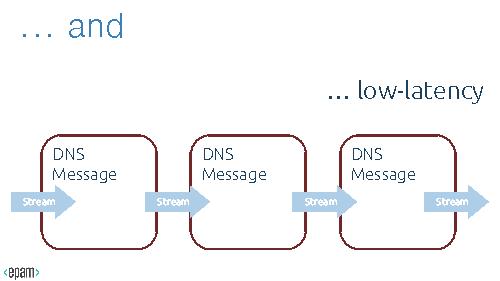
=== Use Case: DNS Tunneling ===
Tunneling – a mechaninsm to encapsulate low-lewel protocols into high-level protocol.
[[File:datascience4netsecurity-lvee2015-015-06-15_100127.jpg]]
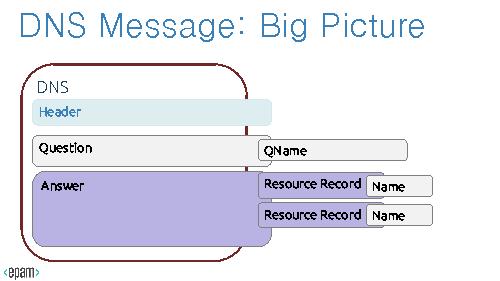
'''DNS message, a Big Picture'''
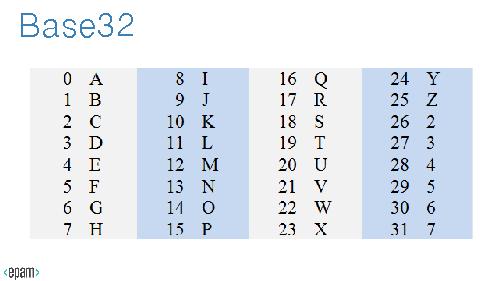
In case of DNS tunneling, DNS Resource Records so as Questions may contain Canonical Names; these Names can be easily encoded/decoded with Base32 or Base64 methods and can be used to transport unauthorized traffic or botnet protocol commands.
[[File:datascience4netsecurity-lvee2015-015-06-15_101055.jpg]]
'''Base32 encoding'''
==== Methods to discover ====
'''Payload analysis'''
* Size of request and response
* Entropy of hostnames
* Statistical Analysis
* Uncommon Record Types
'''Traffic analysis'''
* Volume of DNS traffic per IP address
* Volume of DNS traffic per domain
* Number of hostnames per domain
* Geographic location of DNS server
* Domain history
* Orphan DNS requests
The problem is that the most effective methods to discover DNS traffic demands deep packet inspection. Also, in case of models based on long-term history, we have to store much statistical data and re-compile the intrusion detection model in a batch job, to be up-to-date.
==== Algorithms ====
All algorithms, which could be used for DNS discovering, realate to Machine Learning area; the domain of it is building system, which can be learnt from Data sets and then make predictions about future trends. Today this is very important part of Data Science.
===== Online algorithms =====
It start with an initial state and analyze each piece of data serially one at a time
* Generally require a chain of Map Reduce jobs
* Good fit for Apache Spark, Storm
* Primarily batch, good for Lambda architectures
'''Example 1: Outlier detection'''
* Median Absolute Deviation: Telemetry is anomalous if the deviation of its latest datapoint
with respect to the median is X times larger than the median of deviations
* Standard Deviation from Average: Telemetry is anomalous if the absolute value of the average of the latest three datapoint minus the moving average is greater than three standard deviations of the average.
* Standard Deviation from Moving Average: Telemetry is anomalous if the absolute value of the average of the latest three datapoints minus the moving average is greater than three standard deviations of the moving average.
* Mean Subtraction Cumulation: Telemetry is anomalous if the value of the next datapoint in the series is farther than three standard deviations out in cumulative terms after subtracting the mean from each data point
* Least Squares: Telemetry is anomalous if the average of the last three datapoints on a projected least squares model is greater than three sigma
* Histogram Bins: Telemetry is anomalous if the average of the last three datapoints falls into a histogram bin with less than x
'''Example 2: Stream Classification'''
* Hoeffding Tree (VFDT)
incremental, anytime decision tree induction algorithm that is capable of learning from massive data streams, assuming that the distribution generating examples does not change over time
* Half-Space Trees
ensemble model that randomly spits data into half spaces. They are created online and detect anomalies by their deviations in placement within the forest relative to other data from the same window
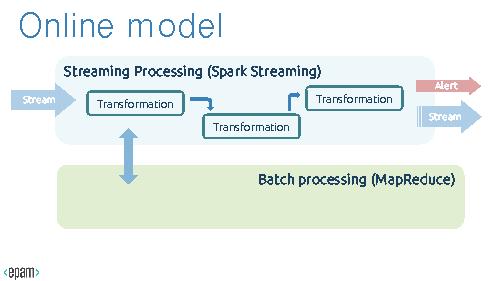
The possible topology Big Picture could be like this
[[File:datascience4netsecurity-lvee2015-015-06-15_093321.jpg]]
'''Online algorithms, Topology'''
===== Offline algorithms =====
It analyzes entire data set at once
* Generally a good fit for Apache Hadoop/Map Reduce
* Model compiled via batch, scored via stream processor
'''Example: Hypothesis Tests'''
* Chi2 Test (Goodness of Fit): A feature is anomalous if the data for the latest micro batch (for the last 10 minutes) comes
from a different distribution than the historical distribution for that feature
* Grubbs Test: telemetry is anomalous if Z score is greater than the Grubb’s score.
* Kolmogorov-Smirnov Test: check if data distribution for last 10 minutes is different from last hour
* Simple Outliers test: telemetry is anomalous if the number of outliers for the last 10 minutes is statistically different then the
historical number of outliers for that time frame
Also, some other types of algorithms can be used
* Decision Trees/Random Forests
* Association Rules (Apriori)
* Auto Regressive (AR) Moving Average (MA)
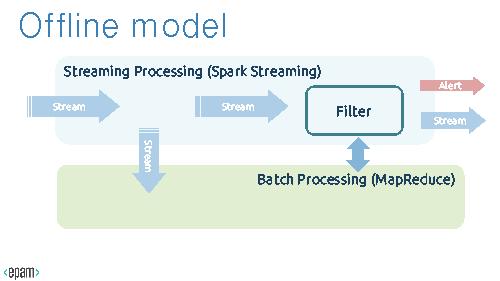
In fact, at using Offlimne algorithms, all analysis is performed as batch tasks, the Streaming part just applies rules compiled by the Batch part. A possible topology Big Picture could be like this
[[File:datascience4netsecurity-lvee2015-015-06-15_093452.jpg]]
'''Offline algorithms, Topology'''
==== Technology stack: all is Free ====
It’s very important, that all software to build Analytics based on Machine Learning so as for Data storage is Free/Libre one. All solutions which we are using are publiched under Apache 2.0, MIT and so on.
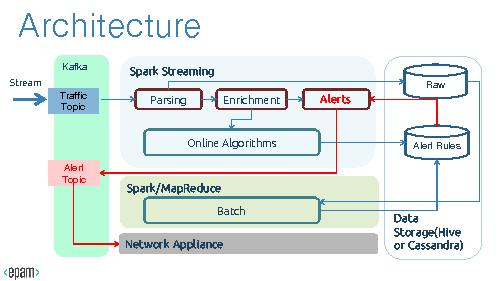
For Streaming part it was used Spark Streaming and Spark for Batch jobs as well. Message Queues which we are using are Kafka and RabbitMQ
</div>
== Примечания и отзывы ==
<!-- <blockquote>[©]</blockquote> -->
* [https://lvee.org/ru/abstracts/164 Страница доклада на сайте конференции]
<references/>
[[Category:LVEE-2015]]
[[Category:Open-source]]
[[Category:Linux]]
[[Category:ToPublish]]
<!-- topub --> | |||
Версия 15:51, 31 июля 2015
Содержание
Аннотация
- Докладчик
- Дмитрий Орехов


Today network traffic is absolutely out of human control, this is something that human mind cannot manage. On the other hand, network security becomes more and more important, since more and more of human activities are moving to the Network. The solution could be a software, which is able to learn from past Data incoming, and then to make assumptions about new Data and predictions about the future. Though algorithms for this domain are well-known, there is a problem to implement them, because they are often very resource-consuming. Fortunately, cloud technologies now afford building cheap and productive clusters, and Open Source solutions like Spark provide a powerful tool to build advanced analytics software on top of them.
Видео
Это бета-версия видео, пока еще можно что-то исправить. Пишите DISQUS-комментарий, если что-то не ОК — на видео в левом верхнем углу красные временные маркеры «истинного времени», указывайте их при багрепорте. Ну или пишите мне.
+ Пишите комментарии по теме, фидбек важен авторам, программному комитету и другим зрителям.
Слайды













Тезисы
Data collecting
The first important task for Network Analytics building is a data collection facility. The main idea is to place sensors, which collect statistics data and send it to be collect and analyze.
- Statistics collection
- the big picture:

Sensors
Sensors are classified by Vantage and Domain.
Vantage is a placement of sensors within a network. Sensors with different vantages would see different parts of the same events.
- Vantages

Domain defines, which part of thraffic statistics and metrics to collect. In the other words, it’s the information the sensor provides, whether that’s at the host, a service on the host, or the network. Sensors with the same vantage but different domains provide complementary data about the same event. For some events, you might only get information from one domain.

Domains
Use Case: DNS Tunneling
Tunneling – a mechaninsm to encapsulate low-lewel protocols into high-level protocol.

DNS message, a Big Picture
In case of DNS tunneling, DNS Resource Records so as Questions may contain Canonical Names; these Names can be easily encoded/decoded with Base32 or Base64 methods and can be used to transport unauthorized traffic or botnet protocol commands.

Base32 encoding
Methods to discover
Payload analysis
- Size of request and response
- Entropy of hostnames
- Statistical Analysis
- Uncommon Record Types
Traffic analysis
- Volume of DNS traffic per IP address
- Volume of DNS traffic per domain
- Number of hostnames per domain
- Geographic location of DNS server
- Domain history
- Orphan DNS requests
The problem is that the most effective methods to discover DNS traffic demands deep packet inspection. Also, in case of models based on long-term history, we have to store much statistical data and re-compile the intrusion detection model in a batch job, to be up-to-date.
Algorithms
All algorithms, which could be used for DNS discovering, realate to Machine Learning area; the domain of it is building system, which can be learnt from Data sets and then make predictions about future trends. Today this is very important part of Data Science.
Online algorithms
It start with an initial state and analyze each piece of data serially one at a time
- Generally require a chain of Map Reduce jobs
- Good fit for Apache Spark, Storm
- Primarily batch, good for Lambda architectures
Example 1: Outlier detection
- Median Absolute Deviation: Telemetry is anomalous if the deviation of its latest datapoint
with respect to the median is X times larger than the median of deviations
- Standard Deviation from Average: Telemetry is anomalous if the absolute value of the average of the latest three datapoint minus the moving average is greater than three standard deviations of the average.
- Standard Deviation from Moving Average: Telemetry is anomalous if the absolute value of the average of the latest three datapoints minus the moving average is greater than three standard deviations of the moving average.
- Mean Subtraction Cumulation: Telemetry is anomalous if the value of the next datapoint in the series is farther than three standard deviations out in cumulative terms after subtracting the mean from each data point
- Least Squares: Telemetry is anomalous if the average of the last three datapoints on a projected least squares model is greater than three sigma
- Histogram Bins: Telemetry is anomalous if the average of the last three datapoints falls into a histogram bin with less than x
Example 2: Stream Classification
- Hoeffding Tree (VFDT)
incremental, anytime decision tree induction algorithm that is capable of learning from massive data streams, assuming that the distribution generating examples does not change over time
- Half-Space Trees
ensemble model that randomly spits data into half spaces. They are created online and detect anomalies by their deviations in placement within the forest relative to other data from the same window
The possible topology Big Picture could be like this

Online algorithms, Topology
Offline algorithms
It analyzes entire data set at once
- Generally a good fit for Apache Hadoop/Map Reduce
- Model compiled via batch, scored via stream processor
Example: Hypothesis Tests
- Chi2 Test (Goodness of Fit): A feature is anomalous if the data for the latest micro batch (for the last 10 minutes) comes
from a different distribution than the historical distribution for that feature
- Grubbs Test: telemetry is anomalous if Z score is greater than the Grubb’s score.
- Kolmogorov-Smirnov Test: check if data distribution for last 10 minutes is different from last hour
- Simple Outliers test: telemetry is anomalous if the number of outliers for the last 10 minutes is statistically different then the
historical number of outliers for that time frame
Also, some other types of algorithms can be used
- Decision Trees/Random Forests
- Association Rules (Apriori)
- Auto Regressive (AR) Moving Average (MA)
In fact, at using Offlimne algorithms, all analysis is performed as batch tasks, the Streaming part just applies rules compiled by the Batch part. A possible topology Big Picture could be like this

Offline algorithms, Topology
Technology stack: all is Free
It’s very important, that all software to build Analytics based on Machine Learning so as for Data storage is Free/Libre one. All solutions which we are using are publiched under Apache 2.0, MIT and so on. For Streaming part it was used Spark Streaming and Spark for Batch jobs as well. Message Queues which we are using are Kafka and RabbitMQ </div>
Примечания и отзывы