Applications of Finite State Machines (Алексей Чеусов, LVEE-2019) — различия между версиями
Материал из 0x1.tv
StasFomin (обсуждение | вклад) (викификация) |
StasFomin (обсуждение | вклад) (викификация) |
||
== Thesis == <latex> Начать следует с определений и теорем, хорошо знакомых любому выпускнику ВУЗ-а по технической специальности. \textbf{'''Определение:} ''' ''Недетерминированным конечным автоматом \linebreak (НКА)'' называется пятерка \mbox{$пятёрка ''<I,S,Q,F,\deltaδ>$}'', где \begin{itemize} \item $I$ : * ''I'' — конечное непустое множество символов (алфавит); \item $S$ * ''S'' — конечное непустое множество состояний; \item $Q$ * ''Q'' — множество стартовых состояний, $Q \subseteq S$''Q'' ⊆ ''S''; \item $F$ * ''F'' — множество конечных состояний, $F \subseteq S$''F'' ⊆ ''S''; \item $\delta$ * δ — отношение переходов $\delta \subseteq S \times I \times S$ δ ⊆ ''S'' × ''I'' × ''S'' (или, иначе, $\deltaδ: S \times I \rightarrow ''S'' × ''I'' → <math>2^S$). \end{itemize} </latex> <latex> </math>). ''Языком КА'' является множество различных последовательностей символов алфавита, допускаемых конечным автоматом, то есть, цепочек символов вдоль пути от стартового до конечного состояния КА. \textbf{'''Определение:} ''' ''Регулярный язык над алфавитом $\Sigma$алфавитом'' ''Σ'' определяется следующим образом: \begin{itemize} \item* Пустой язык $\emptyset$''∅'' и язык $\{\epsilon\''ε''}$, состоящий из пустой строки, являеются регулярными языкоами; \item $\* {a\''a''}$, где $a \in \Sigma$''a'' ∈ ''Σ'', является регулярным языком; \item* Если $A$''A'' и $B$''B'' — регулярные языки, то $A \cup B$''A'' ∪ ''B'' (объединение), $A \bullet B$''A'' • ''B'' (конкатенация), и $<math>A\ast$^*</math> (звезда Клини) являются регулярными языками; \item* Никакие другие языки над $\Sigma$''Σ'' не являются регулярными. \end{itemize} Этот формализм даеёт нам так называемые «регулярные выражения». \textbf{'''Определение:} ''' ''Детерминированным конечным автоматом \linebreak (ДКА)'' является пятерка $пятёрка ''<I,S,q,F,\deltaδ>$'', где \begin{itemize} \item $I$ : * ''I'' — конечное непустое множество символов (алфавит); \item $S$ * ''S'' — конечное непустое множество состояний; \item $q$ * ''q'' — стартовое состояние, $q \in S$. \item $F$ ''q'' ∈ ''S''; * ''F'' — множество конечных состояний, $F \subseteq S$. \item $\delta$ ''F'' ⊆ ''S''; * δ — функция переходов: $\deltaδ: S \times I \rightarrow S$ \end{itemize} </latex> <latex> \textbf{''S'' × ''I'' → ''S''. '''Теоремы}: \begin{itemize} \item''' * НКА и ДКА — эквивалентные формализмы, то есть, для каждого НКА существует эквивалентный ему ДКА,; обратное верно по определению. \item* В общем случае ДКА может быть экспоненциально больше (по количеству состояний) по сравнению с эквивалентным ему НКА. \item* Для любого ДКА существует только один (с точностью до изоморфизма) минимальный ДКА, эквивалентный ему. \item* Регулярные языки и конечные автоматы — эквивалентные формализмы, то есть, для любого КАконечного автомата существует эквивалентный ему регулярный язык и наоборот. \item* Конечные автоматы замкнуты относительно операций объединения, вычитания, пересечения, дополнения и звезды Клини. \end{itemize} </latex> ----- <latex> \textbf{Алгоритм} '''Алгоритм''' построения ДКА из НКА представлен ниже. \begin{algorithm}[h!] \DontPrintSemicolon \SetKwInOut{Input}{input} \SetKwInOut{Output}{output} \Input{NFA = $ ---- <pre style="font-size:70%"> Вход: NFA = <I,S,Q,F,\delta>$} \Output{DFA = $<I,S^{\prime},q^\prime,F^{\prime},\delta^{\prime}>$} \SetAlgoLined % \SetAlgoNoEnd $\delta^\prime := \emptyset, q^\prime := \δ> Выход: DFA = <I,S′,q′,F′,δ′> δ′ := ∅, q′ := {s | s \in∈ Q\}, S^\prime′ := \{q^\prime\′}$\; $ seen := \{q^\prime\′}, queue := [q^\prime′]$\; \While{$queue \neq \emptyset$}{ $src\_states \leftarrow queue$\; \For{$ пока queue ≠ ∅: src_states ← queue для каждого i \in∈ I$}{ $trg\_states: trg_states := \{s^{trg}{sᵗʳᵍ | (s^{src}sˢʳᶜ,i,s^{trg}sᵗʳᵍ) \in \delta∈ δ, s^{src} \in src\_states\}$\; \If{$trg\_states \neq \emptyset$}{ $\delta^\prime \leftarrowsˢʳᶜ ∈ src_states} если trg_states ≠ ∅: δ′ ← (src\_states, i, trg\_states)$\; $ S^\prime \leftarrow trg\_states$\; \If{$trg\_states \notin′ ← trg_states если trg_states ∉ seen$}{ $: queue \leftarrow trg\_states$\; $← trg_states seen \leftarrow trg\_states$\; } } } } $← trg_states F^\prime′ := \{state\_set \instate_set ∈ S^\prime′ | \exists∃ s \in state\_set∈ state_set, s \in∈ F\}$ \caption{ </pre> ''nfa2dfa algorithm AKA <<algorithm'' (также известен как «Subset construction>>} \end{algorithm} </latex> ---- <latex> Введем») ---- Введём два дополнительных оператора: \begin{itemize} \item R * ''R'' — оператор инвертирования. $''L(R(KA))'' = \{ inverse(w''w'') | w \in ''w'' ∈ ''L(KA)\'' }$ \item D * ''D'' — оператор построения ДКА по НКА. \end{itemize} \textbf{Алгоритм} '''Алгоритм''' Бжозовского построения минимального ДКА по \linebreak НКА:\\ $ <math>MinDFA = (D \circ∘ R \circ∘ D \circ∘ R)\, KA$ \textbf{</math> '''Замечание:} ''' В отличие от большинства других алгоритмов построения минимального ДКА, алгоритм Бжозовского строит минимальный ДКА '''по НКА'''! Алгоритм проверки, входит ли строка в язык ДКА. </latex> <latex> \begin{algorithm}[h!] \DontPrintSemicolon \SetKwInOut{Input}{input} \SetKwInOut{Output}{output} \Input{DFA = $: <pre style="font-size:70%"> Вход: DFA = <I,S,q,F,\delta>, Text=[t_1, t_2 \dots t_n], t_i \in I$} \Output{$true$ \textbf{or} $false$} \SetAlgoLined % \SetAlgoNoEnd $state := q$\; \For{$i$ from $1$ to $n$}{ \uIf{$\delta$ is defined on $(state, t_i)$}{ $state := \delta(state, t_i)$\; }\Else{ \textbf{return} false\; } } \textbf{return} $(state \in F)$\; \caption{δ>, Text = [t₁, t₂ … tₙ], tᵢ ∈ I Выход: true или false state := q для i от 1 до n: если δ определена на (state, tᵢ): state := δ(state, tᵢ) иначе: вернуть false вернуть (state ∈ F) # Сопоставление строки с ДКА. # Сложность алгоритма: $O(n)$} \end{algorithm} </pre> ---- Алгоритм проверки, входит ли строка в язык НКА. \begin{algorithm} \DontPrintSemicolon \SetAlgoLined \SetKwInOut{Input}{input} \SetKwInOut{Output}{output} \Input{ <pre style="font-size:70%"> Вход: NFA = $<I,S,Q,F,\deltaδ>, Text = [t_1t₁, t_2 \dots t_nt₂ … tₙ], t_i \intᵢ ∈ I$} \Output{$ Выход: true$ \textbf{or} $ или false$} $ states := Q$\; \For{$ для i$ from $ от 1$ to $ до n$ \textbf{and} $ и пока states \neq \emptyset$}{ $≠ ∅: states := \{ trg | (src, t_itᵢ, trg) \in \delta∈ δ, src \in∈ states\}$\; } \textbf{return} $ } вернуть (\exists∃ s \in∈ states, s \in∈ F)$\; \caption{ # Сопоставление строки с НКА. # Сложность алгоритма: $O(n * |S|)$} \end{algorithm} \textbf{Определение:} Автомат Мура — это шестерка $<I,O,S,q,\delta, \lambda>$, где \begin{itemize} \item $I$ — входной алфавит, конечное непустое множество входных символов; \item $O$ — выходной алфавит, конечное непустое множество выходных символов; \item $S$ — конечное непустое множество состояний; \item $q$ — стартовое состояние, $q \in S$; \item $\delta$ — функция переходов $\delta: S \times I \rightarrow S$; \item $\lambda$ — функция выходов $\lambda: S \rightarrow O$. \end{itemize} \textbf{Определение:} Автомат Мили — это шестерка $<I,O,S,q,\delta, \lambda>$. \begin{itemize} \item $I$ — входной алфавит, конечное непустое множество входных символов; \item $O$ — выходной алфавит, конечное непустое множество выходных символов; \item $S$ — конечное непустое множество состояний; \item $q$ — стартовое состояние, $q \in S$; \item $\delta$ — функция переходов $\delta: S \times I \rightarrow S$ \item $\lambda$ — функция выходов $\lambda: S \times I \rightarrow O$ \end{itemize} \textbf{Note:} На практике мы часто работаем с \textit{частично определенными} ДКА, НКА, автоматами Мура и Мили, то есть, автоматами с частично определенной функцией переходов. \textbf{Теорема:} Автоматы Мура и Мили — эквивалентные формализмы. \textbf{Определение:} Взвешенный конечный автомат — это шестерка $<I,S,Q,F,\delta, \omega>$. \begin{itemize} \item $I$ — конечное непустое множество символов (алфавит); \item $S$ — конечное непустое множество состояний; \item $Q$ — множество стартовых состояний, $Q \subseteq S$; \item $F$ — множество конечных состояний, $F \subseteq S$; \item $\delta$ — отношение переходов $\delta \subseteq S \times I \times S$ \item $\omega: \delta \rightarrow \mathbb{R}$ — вес перехода. \end{itemize} $\omega$ может быть функцией расстояния, вероятностей, штрафов и т. д., даже не обязательно $\mathbb{R}$. \textbf{Определение:} Конечно-автоматный преобразователь — это шестерка $<I,O,S,Q,F,\delta>$. \begin{itemize} \item $I$ — входной алфавит, конечное непустое множество входных символов; \item $O$ — выходной алфавит, конечное непустое множество выходных символов; \item $S$ — конечное непустое множество состояний; \item $Q$ — множество стартовых состояний, $Q \subseteq S$; \item $F$ — множество конечных состояний, $F \subseteq S$; \item $\delta$ — отношение переходов $\delta \subseteq S \times (I \cup \{\epsilon\}) \times (O \cup \{\epsilon\})\times S$, где $\epsilon$ — это пустая строка. \end{itemize} \textbf{Замечание:} Взвешенный конечно-автоматный преобразователь \linebreak определяется аналогично взвешенному конечному автомату.× |S|) </latex> <latex> \textbf{pre> ---- '''Область применения взвешенных конечно-автоматных преобразователей:} ''' распознавание речи, синтез речи, распознавание символов, машинный перевод, различные задачи обработки естественного языка, включая синтаксический анализ и моделирование языка, распознавание образов и вычислительная биология. '''Задачи, решаемые с помощью конечных автоматов: \begin{itemize} \item''' * Исправление ошибок OCR-распознавания CUSIP (\href{https://en.wikipedia.org/wiki/CUSIP}{https://en. wikipedia.org/wiki/CUSIP})[https://en.wikipedia.org/wiki/CUSIP CUSIP]. Идея алгоритма заключается в построении взвешенного конечно-автоматного преобразователя. В неём состояния соответствуют значению контрольной суммы (по модулю 10), рассчитанной для определеённого символа (8 групп по 10 состояний в каждой), а переходы между группами состояний соответствуют символам CUSIP. Переходы из состояний 8-й группы в конечное состояние соответствуеют символу контрольной суммы. Входным алфавитом является множество наблюдаемых (распознанных) символов. Выходным алфавитом является— множество символов, допустимых в CUSIP. При этом выходной вес на переходе соответствует правильному (исправленному) символу CUSIP. Вес же перехода --— это условная вероятность правильного символа при определенном определённом наблюдаемом. Таким образом, путь с максимальным произведением заданных на переходах условных вероятностей и даеёт нам способ исправления неправильно распознанных символов CUSIP. При этом правильность контрольной суммы CUSIP обеспечивается структурой конечно-автоматного преобразователя. \item* Исправление ошибок OCR-распознавания IBAN. Подход, который можно использовать для этой задачи, ровно тот же, что и в задаче корректирования CUSIP. Разница заключается длишь в том, что КА строится для другой контрольной суммы (mod 97) и с использованием регулярных выражений, задающих форму IBAN для различных стран европы Европы. Такой КА получится достаточно большим. \item* Наиболее простым способом применения КА является проектирование ПО программного обеспечения, в частности проектирование классов при использовании объектно-оринеентированной парадигмы. Жизненный цикл объекта некоего некоторого класса представляется в виде КА, задающего его поведение, при. При этом стартовое состояние КА представляет собой состояние объекта в момент после его создания конструктором по умолчанию. А, а переходы соответствуют вызовам определеённых функнций в моменты, когда объект находится в определеённых состояниях. Этот подход даеёт возможность тестировать поведение объекта (и, в общем случае, ПО) в процессе его жизни. Такого рода тестирование заключается в покрытии таблицы переходов КА. \item* Задача извлечения именованных сущностей из текста также может быть решена с использованием взвешенных конечных автоматов. Идея такого алгоритма заключается в том, что классификация производится пословно на классах B, I, O, E, S (при использовании BIOES -нотации), а затем производится выбор из всех возможных цепочек только тех, которые согласуются с BIOES -нотацией, которую можно задать с помощью КА. При этом переходы КА взвешены вероятностями, полученными классификационным алгоритмом, а значит появляется возможность выбрать наиболее вероятную последовательность меток B, I, E, S и O. Этот подход является впо сущности алгоритмом выбора цепочки меток, которая соответствуетсоответствующей максимальной совместной вероятности набора меток, при этом множество цепочек, из которых производится отбор , полностью соответствует BIOES -нотации. \item* Автоматы Мура можно использовать, например, для задачи сопоставление сопоставления текста с образцами с сохранением информации о том, какой именно набор образцов <<«сработал>>» на заданном тексте. Для решения данной задачи при использовании ДКА необходимо воспользоваться информацией о том, из каких состояний исходного НКА << «сформировано>>» состояние ДКА. Эта информация используется для формирования символа выходного алфавита, соответствующего << «конечному>>» состоянию, которое соответствует любому набору исходных регулярных выражений. Потенциально выходной алфавит может содержать $<math>2^n$</math> элементов, где $n$ --''n'' — количество исходных регулярных выражений. \end{itemize} </latex> {{----}} [[File:{{#setmainimage:Applications of Finite State Machines (Алексей Чеусов, LVEE-2019)!.jpg}}|center|640px]] {{LinksSection}} <!-- > * Прежде всего хочется сказать, что данная статья является дополнением к презентации, доступной по ссылке ~ http://www.mova.org/~cheusov/pub/lvee/2019/fsa_presentation.pdf --> <!-- <blockquote>[©]</blockquote> --> {{fblink|2427332600853080}} {{vklink|1456}} | |||
Текущая версия на 13:58, 24 октября 2025
- Докладчик
- Алексей Чеусов


In this presentation we define the finite state automata (FSA), Moore and Mealy machines, and Finite State Transducers. Weighted and stochastic finite state machines are described. Also, a few well-known and custom algorithms based on finite state machines, are described.
Содержание
Видео
Презентация







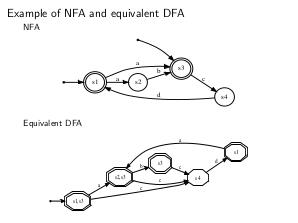





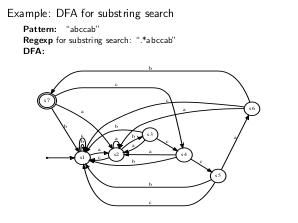




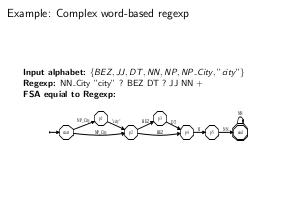
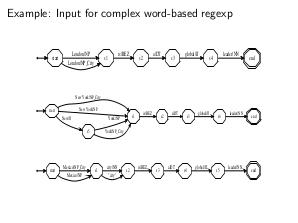
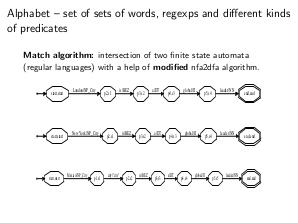
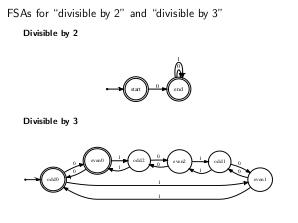
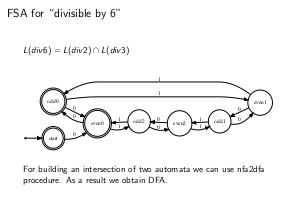
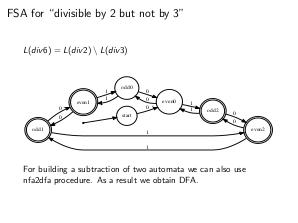











Thesis
Начать следует с определений и теорем, хорошо знакомых любому выпускнику ВУЗ-а по технической специальности.
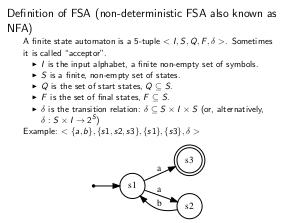
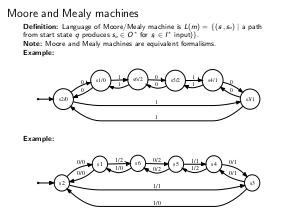
Определение: Недетерминированным конечным автоматом (НКА) называется пятёрка <I,S,Q,F,δ>, где:
- I — конечное непустое множество символов (алфавит);
- S — конечное непустое множество состояний;
- Q — множество стартовых состояний, Q ⊆ S;
- F — множество конечных состояний, F ⊆ S;
- δ — отношение переходов δ ⊆ S × I × S (или, иначе, δ: S × I → ).
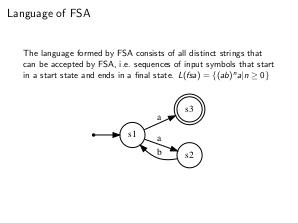
Языком КА является множество различных последовательностей символов алфавита, допускаемых конечным автоматом, то есть, цепочек символов вдоль пути от стартового до конечного состояния КА.
Определение: Регулярный язык над алфавитом Σ определяется следующим образом:
- Пустой язык ∅ и язык {ε}, состоящий из пустой строки, являются регулярными языками;
- {a}, где a ∈ Σ, является регулярным языком;
- Если A и B — регулярные языки, то A ∪ B (объединение), A • B (конкатенация) и (звезда Клини) являются регулярными языками;
- Никакие другие языки над Σ не являются регулярными.
Этот формализм даёт нам так называемые «регулярные выражения».
Определение: Детерминированным конечным автоматом (ДКА) является пятёрка <I,S,q,F,δ>, где:
- I — конечное непустое множество символов (алфавит);
- S — конечное непустое множество состояний;
- q — стартовое состояние, q ∈ S;
- F — множество конечных состояний, F ⊆ S;
- δ — функция переходов: δ: S × I → S.
Теоремы:
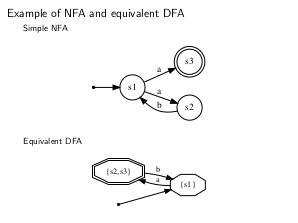
- НКА и ДКА — эквивалентные формализмы, то есть для каждого НКА существует эквивалентный ему ДКА; обратное верно по определению.
- В общем случае ДКА может быть экспоненциально больше (по количеству состояний) по сравнению с эквивалентным ему НКА.
- Для любого ДКА существует только один (с точностью до изоморфизма) минимальный ДКА, эквивалентный ему.
- Регулярные языки и конечные автоматы — эквивалентные формализмы, то есть для любого конечного автомата существует эквивалентный ему регулярный язык и наоборот.
- Конечные автоматы замкнуты относительно операций объединения, вычитания, пересечения, дополнения и звезды Клини.
Алгоритм построения ДКА из НКА представлен ниже.
Вход: NFA = <I,S,Q,F,δ>
Выход: DFA = <I,S′,q′,F′,δ′>
δ′ := ∅, q′ := {s | s ∈ Q}, S′ := {q′}
seen := {q′}, queue := [q′]
пока queue ≠ ∅:
src_states ← queue
для каждого i ∈ I:
trg_states := {sᵗʳᵍ | (sˢʳᶜ,i,sᵗʳᵍ) ∈ δ, sˢʳᶜ ∈ src_states}
если trg_states ≠ ∅:
δ′ ← (src_states, i, trg_states)
S′ ← trg_states
если trg_states ∉ seen:
queue ← trg_states
seen ← trg_states
F′ := {state_set ∈ S′ | ∃ s ∈ state_set, s ∈ F}
nfa2dfa algorithm (также известен как «Subset construction»)
Введём два дополнительных оператора:
- R — оператор инвертирования. L(R(KA)) = { inverse(w) | w ∈ L(KA) }
- D — оператор построения ДКА по НКА.
Алгоритм Бжозовского построения минимального ДКА по НКА:
Замечание: В отличие от большинства других алгоритмов построения минимального ДКА, алгоритм Бжозовского строит минимальный ДКА по НКА!
Алгоритм проверки, входит ли строка в язык ДКА:
Вход: DFA = <I,S,q,F,δ>, Text = [t₁, t₂ … tₙ], tᵢ ∈ I
Выход: true или false
state := q
для i от 1 до n:
если δ определена на (state, tᵢ):
state := δ(state, tᵢ)
иначе:
вернуть false
вернуть (state ∈ F)
# Сопоставление строки с ДКА
# Сложность алгоритма: O(n)
Алгоритм проверки, входит ли строка в язык НКА.
Вход: NFA = <I,S,Q,F,δ>, Text = [t₁, t₂ … tₙ], tᵢ ∈ I
Выход: true или false
states := Q
для i от 1 до n и пока states ≠ ∅:
states := { trg | (src, tᵢ, trg) ∈ δ, src ∈ states }
вернуть (∃ s ∈ states, s ∈ F)
# Сопоставление строки с НКА
# Сложность алгоритма: O(n × |S|)
Область применения взвешенных конечно-автоматных преобразователей: распознавание речи, синтез речи, распознавание символов, машинный перевод, различные задачи обработки естественного языка, включая синтаксический анализ и моделирование языка, распознавание образов и вычислительная биология.
Задачи, решаемые с помощью конечных автоматов:
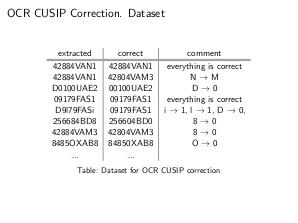
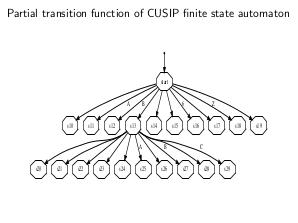
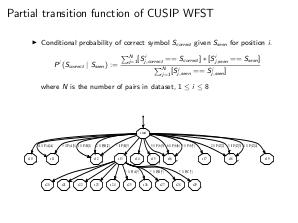
- Исправление ошибок OCR-распознавания CUSIP. Идея алгоритма заключается в построении взвешенного конечно-автоматного преобразователя. В нём состояния соответствуют значению контрольной суммы (по модулю 10), рассчитанной для определённого символа (8 групп по 10 состояний в каждой), а переходы между группами состояний соответствуют символам CUSIP. Переходы из состояний 8-й группы в конечное состояние соответствуют символу контрольной суммы. Входным алфавитом является множество наблюдаемых (распознанных) символов. Выходным алфавитом — множество символов, допустимых в CUSIP. При этом выходной вес на переходе соответствует правильному (исправленному) символу CUSIP. Вес же перехода — это условная вероятность правильного символа при определённом наблюдаемом. Таким образом, путь с максимальным произведением заданных на переходах условных вероятностей и даёт нам способ исправления неправильно распознанных символов CUSIP. При этом правильность контрольной суммы CUSIP обеспечивается структурой конечно-автоматного преобразователя.
- Исправление ошибок OCR-распознавания IBAN. Подход, который можно использовать для этой задачи, ровно тот же, что и в задаче корректирования CUSIP. Разница заключается лишь в том, что КА строится для другой контрольной суммы (mod 97) и с использованием регулярных выражений, задающих форму IBAN для различных стран Европы. Такой КА получится достаточно большим.
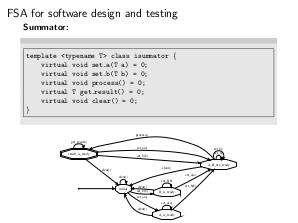
- Наиболее простым способом применения КА является проектирование программного обеспечения, в частности проектирование классов при использовании объектно-ориентированной парадигмы. Жизненный цикл объекта некоторого класса представляется в виде КА, задающего его поведение. При этом стартовое состояние КА представляет собой состояние объекта в момент после его создания конструктором по умолчанию, а переходы соответствуют вызовам определённых функций в моменты, когда объект находится в определённых состояниях. Этот подход даёт возможность тестировать поведение объекта (и, в общем случае, ПО) в процессе его жизни. Такого рода тестирование заключается в покрытии таблицы переходов КА.
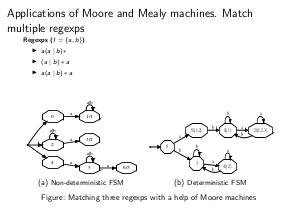
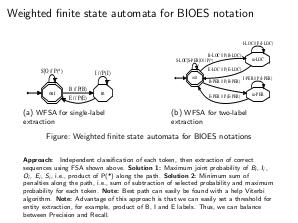
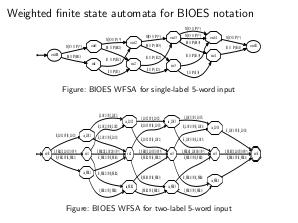
- Задача извлечения именованных сущностей из текста также может быть решена с использованием взвешенных конечных автоматов. Идея такого алгоритма заключается в том, что классификация производится пословно на классах B, I, O, E, S (при использовании BIOES-нотации), а затем производится выбор из всех возможных цепочек только тех, которые согласуются с BIOES-нотацией, которую можно задать с помощью КА. При этом переходы КА взвешены вероятностями, полученными классификационным алгоритмом, а значит появляется возможность выбрать наиболее вероятную последовательность меток B, I, E, S и O. Этот подход является по сути алгоритмом выбора цепочки меток, соответствующей максимальной совместной вероятности набора меток, при этом множество цепочек, из которых производится отбор, полностью соответствует BIOES-нотации.
- Автоматы Мура можно использовать, например, для задачи сопоставления текста с образцами с сохранением информации о том, какой именно набор образцов «сработал» на заданном тексте. Для решения данной задачи при использовании ДКА необходимо воспользоваться информацией о том, из каких состояний исходного НКА «сформировано» состояние ДКА. Эта информация используется для формирования символа выходного алфавита, соответствующего «конечному» состоянию, которое соответствует любому набору исходных регулярных выражений. Потенциально выходной алфавит может содержать элементов, где n — количество исходных регулярных выражений.
!.jpg)
Примечания и ссылки
Plays:72
Comments:1