Libmdbx key-value storage — кандидат в лучшие из встраиваемых (Леонид Юрьев, OSSDEVCONF-2017)
Материал из 0x1.tv
- Докладчик
- Леонид Юрьев


В докладе делается обзор высокопроизводительного движка хранения пар ключ-значения (key-value storage). Сейчас в проекте происходят огромные изменения, в результате которых MDBX (libmdbx) приобретает новые, недосягаемые ранее, свойства. В докладе рассказывается о целях инициированной революции, уже доступных и ожидаемых результатах.
Стоит вынести главный утверждающий тезис доклада — уже сейчас libmdbx является одним из самых быстрых key-value хранилищ, а в следующем году избавится от ряда унаследованных недостатков и перейдет в класс технологических лидеров.
Содержание
Видео
Презентация




Thesis
Хранилища ключ-значения (key-value) уже давно стали трендом индустрии и фактически вытеснили реляционные СУБД из применений требующих высокой производительности или экономии ресурсов. При этом, несмотря на крайне широкий спектр уже доступных технологий идёт битва и поиск новых решений, в том числе более оптимальных в некоторых сферах применения или специфических условиях.
MDBX (libmdbx) — это классический встраиваемый ультра-быстрый движок хранения пар ключ-значение (key-value), но со специфическим набором свойств и возможностей, ориентированный на создание решений с предельной производительностью и/или контролируемым (прозрачным) поведением.
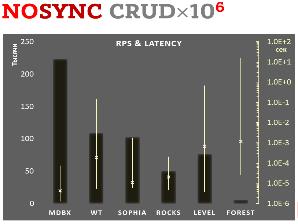
Следует ответить, что libmdbx действительно является чемпионом во многих открытых бенчмарках, в том числе по таким параметрам как: равномерность времени выполнения запросов, масштабируемость чтения, используемое место, потребление процессорного времени и т.д.
С другой стороны, libmdbx объективно будет отставать от конкурентов в некоторых сценариях использования. Поэтому к результатам сравнительных тестов следует относиться взвешенно, обязательно принимая во внимание все детали, особенно предоставляемые гарантии сохранности данных, объём потерь и длительность восстановления после аварий.
История libmdbx
libmdbx является трёхгодичным форком Lightning Memory-Mapped Database (LMDB). Но только с 2017 года развитие проекта не сдерживается необходимостью совместимости с прародителем, в том числе по формату файлов БД.
Уместно сказать, что LMDB широко известен «в узких кругах» и используется во многих общеизвестных проектах, например: InfluxDB, Postfix, Cyrus SALS, Knot DNS, Power DNS, libpaxos, Monero и т. д. Родиной LMDB является проект OpenLDAP, где в 2010 году потребовалась замена для технологически и морально устаревшей Berkeley DB.
История libmdbx начинается осенью 2014 года. Изначально работа велась в составе проекта ReOpenLDAP, который был отпочкован от OpenLDAP из-за отказа основных разработчиков принимать часть изменений, которые были жизненно необходимы для «починки» (тушения пожара) и успешной эксплуатации в инфраструктуре ПАО МегаФон с полной проектной нагрузкой. К осени 2015 сделанные доработки приобрели самостоятельную ценность и исходный код движка хранения был выделен в отдельный проект libmdbx.
В 2017 году libmdbx получил новый импульс развития. С одной стороны, были выполнены обязательства по сохранению совместимости. С другой стороны, libmdbx был задействован в «Позитивных таблицах» компании Positive Technologies.
Основные свойства libmdbx
Как уже было пояснено, libmdbx является достаточно глубокой переработкой и развитием LMDB. Поэтому, с одной стороны, libmdbx наследует все характеристики и уникальные свойства LMDB, в том числе проблемы и недостатки. С другой стороны, libmdbx предлагает ряд успешных «заплаток» для всех проблем LMDB, а также предлагает дополнительные возможности.
Хотелось-бы избежать нахваливания и подробного описания libmdbx, в том числе LMDB как прародителя. Подобная информация доступна в сети, в том числе на сайте проекта. Тем не менее, всё же необходимо тезисно перечислить основные свойства libmdbx:
- Данные отображаются в память и используются совместно всеми процессами работающими с экземпляром БД.
- В качестве модели данных предлагаются упорядоченные ассоциативные массивы с поддержкой курсоров и выборкой по диапазонам.
- Запросы чтения выполняются параллельно без использования дорогих атомарных операций, в том числе никак не блокируются (lockfree).
- Изменения выполняются строго последовательно, но не блокируются запросами чтения при наличии места в БД.
- Чтение и обновление данных происходят только в рамках транзакций с полными гарантиями ACID, которые обеспечиваются посредством MVCC (параллельный доступ с помощью многоверсионности) и COW (копированием при изменении).
- Амортизационная стоимость любой операции Olog(N), в том числе Write Amplification Factor и Read Amplification Factor.
- Нет журнала транзакций или журнала опережающей записи. Не требуется восстановление после аварий. Не требуется какое-либо периодическое обслуживание. Поддерживается резервное копирование «на лету».
- Поддерживаются ключи с множественными значениями. При этом ключи хранятся в одном экземпляре, а значения помещаются в аналоги «вложенных таблиц», для которых также доступны курсоры.
- Код движка компактен (менее 64К для x86_64). Не имеет собственных механизмов управления памятью и кешированием. Не нуждается в дополнительных thread для собственных нужд (за исключением планируемого механизма асинхронной фиксации).
Сценарии использования libmdbx
Исходя из свойств и внутренних механизмов libmdbx можно выделить три группы областей применений или сценариев использования libmdbx: подходящие, пограничные, противопоказанные. Однако, практика показывает что такое подразделение достаточно условно и правильнее оценивать сумму факторов, каждый из которых вытекает из отдельного свойства libmdbx и может быть как положительным, так и отрицательным в каждом конкретном случае. Кратко рассмотрим самые важные свойства и связанные с ними плюсы/минусы:
Встраиваемый движок:
Встраиваемость становится весомым плюсом когда отдельный серверный процесс не требуется, тем более если этого хочется избежать.
С другой стороны, при встраивании, со стороны остального кода, есть неизбежный риск повреждения внутренних структур данных движка. Что может приводить к повреждению БД. Характерным примером может служить «удачная» запись нуля по некорректному указателю, которая заставит движок сделать запись в нулевую (управляющую) мета-страницу БД.
Данные отображены в ОЗУ:
Отображение в память позволяет кардинально снизить накладные расходы на доступ к данным и не иметь какой-либо собственной инфраструктуры кеширования (всё необходимое выполняется ядром ОС). В частности, в libmdbx можно легко избежать лишнего копирования данных (zero copy) получая непосредственно указатель на read-only отображение в памяти.
С другой стороны, могут быть затруднения если объём данных превышает размер ОЗУ или механизмы управления виртуальной памятью неверно настроены и/или работаю не оптимально (Windows 8).
Кроме этого, в сравнении с хранилищами основанными на LSM-деревьях (Log-Structured Merge-tree), в libmdbx новые и старые данные равны между собой. Поэтому на больших объёмах libmdbx может проигрывать в сценариях с частым доступом к недавно добавленным данных. Однако, стоит отметить, что на практике ситуация зависит от массы факторов и может быть кардинально обратной. Например, «горячие» и/или недавно добавленные данные с большой вероятностью НЕ будут вытесняться из ОЗУ и кэша процессора, и тогда libmdbx может быть на порядок более эффективнее LSM-деревьев, что подтверждается соответствующими тестами.
Отсутствие журнала транзакций:
Пожалуй это один из самых принципиальных моментов, который, в зависимости от требований, может становиться как радикальным плюсом, так и большим минусом. Вопрос сложен и неразрывно связан с гарантиями сохранности данных и производительностью для операций изменяющих данные. Но давайте попробуем тезисно разобраться (далее предполагается что читатель знаком или ознакомится с терминами «журнал опережающей записи» и «журнализация транзакций» в Википедии).
- При низком темпе изменений данных, отсутствие или наличие журнала не окажет значимой разницы. Скорее всего мы
предпочтем полностью фиксировать данные на диске после каждой транзакции. Например, такой простой сценарий является классическим для LDAP.
В этом случае libmdbx вероятно будет абсолютным чемпионом, так как позволяет выполнять читающие запросы сколь угодно параллельно, без блокировок и с минимальными накладными расходами.
- При высоком темпе изменений, точнее при фиксации этих изменений, узким местом становится диск. Чтобы записывать
меньше данных, и преимущественно последовательно, придётся вести журнал и тратить на него ресурсы, в том числе что-то делать дважды: сначала делать промежуточное «быстрое» фиксирование в журнале, а позже ещё раз внутри БД.
Однако, важнее то, что использование журнала потребует восстановления БД после аварии. Такое восстановление может быть длительным, и даже потребовать участия человека (например, при нехватке места), что в ряде применений может быть неприемлемым. Поэтому отсутствие фазы восстановления в libmdbx может стать решающим плюсом.
- Несомненно использование журнала дает выигрыш в производительности, особенно на шпиндельных дисках (HDD). Но
нередко упускается тот факт, что для гарантии сохранности данных требуется фиксировать изменение самого журнала после каждой транзакции, что крайне драматически сказывается на итоговой производительности.
Например, журнал обычно располагается в файловой системе, нередко на одном физическом устройстве с телом БД или другими изменяемыми сущностями. При этом реальная фиксация данных требует выполнения носителем всей очереди команд и выдачи подтверждения (наличие нескольких логических очередей не означает что драйвер и ОС будут ими пользоваться, а также не означает что встроенный контроллер носителя будет действительно независимо их обслуживать). В результате, фиксация транзакции всё также «стреляет по диску дробью», как если-бы журнала не было. Причём в случае SSD ситуация во многом схожая — нет затрат на перемещение головок, зато данные пишутся большими секторами в несколько шагов, что при синхронном выполнении с подтверждением занимает достаточно времени.
Поэтому, практически всегда приходится жертвовать гарантиями сохранности данных. Проще говоря, если при аварии мы готовы потерять некоторое количество последних изменений, то можем фиксировать журнал реже или как-получится, тем самым подняв производительность ещё на порядок или более.
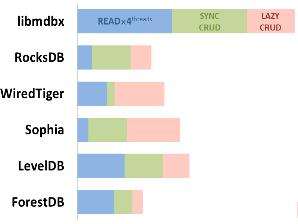
В целом, здесь речь всегда идёт о компромиссе между производительностью и гарантиями сохранности данных в терминах объема потерь при аварии. В libmdbx предлагается несколько вариантов подобного компромисса:
- «простая» отложенная запись в файлы ядром ОС;
- автоматическая фиксация по объёму изменений и/или по времени;
- асинхронная «догоняющая» фиксация (в разработке);
- полностью асинхронная фиксация по усмотрению ядра ОС;
- явная «ручная» фиксация через API.
По оценкам автора, за счёт предлагаемых компромиссов и возможностей, libmdbx может более чем успешно конкурировать в подавляющем большинстве сценариев. Тем не менее, следует понимать что в абсолютных цифрах WAF (Write Amplification Factor) в libmdbx, скорее всего и почти всегда, будет больше чем в движках с хорошо реализованным WAL (write-ahead log).
Проблема долгих чтений в MVCC:
Подобная проблема так или иначе существует во всех СУБД, которые обеспечивают конкурентную обработку читающих и пишущих запросов с соблюдением ACID (aka MVCC bloat). Суть в том, что для любой читающей транзакции, на всё время жизни такой транзакции, СУБД должна обеспечивать консистентный набор данных, который не меняется с точки зрения читателя. Если при этом происходит интенсивное изменение данных, то все данные могут быть изменены и для поддержания долгой читающей транзакции может потребоваться дополнительное место, равное объёму данных на момент старта читающей транзакции.
В случае libmdbx проблема проявляется более остро и на это есть две веские причины:
- Ради производительности libmdbx отслеживает использование страниц через линейную проекцию истории их изменения.
Поэтому сборка мусора крайне эффективна (дешева), но может происходить только последовательно от старых версий снимков данных к новым. В результате сборка мусора вынужденно приостанавливается на самой старой (дальней) используемой/читаемой точки в истории данных.
Другими словами, одного «застрявшего» читателя достаточно чтобы приостановить сборку мусора и вызвать переполнение БД.
- Высокая производительность позволяет израсходовать всё свободное место относительно быстро.
Для решения проблемы текущая версия libmdbx предлагает использовать обратный вызов, который, в частности, может либо подождать «застрявшего» читателя, либо прервать его транзакцию.
В будущих версиях libmdbx планируется реализовать механизм аварийной сборки мусора, который ценой относительно большого объёма операций будет искать неиспользуемые страницы глядя «сквозь» всю линейную историю, не останавливаясь на последней используемой версии данных. Можно сказать, что этот механизм будет по-требованию выполнять аналог VACUUM из PostreSQL.
Причины и цели революционных изменений
Уместно напомнить, что libmdbx отпочковался от LMDB вынужденно. В частности, из-за того что часть необходимых доработок не была принята. Более того, вся первоначальная активность была ради устранения производственно-эксплуатационных проблем возникших при эксплуатации OpenLDAP в ПАО МегаФон.
Это обстоятельство требовало «ехать, а не искать шашечки», в том числе нужно было устранять проблемы, а не улучшать движок. По той-же причине было невозможно нарушать совместимость с LMDB по формату файлов, а изменения API требовали немедленного отражения в исходном коде ReOpenLDAP.
Когда же в 2016 удалось добиться достаточно стабильной работы ReOpenLDAP, включа libmdbx и механизм репликации, активная доработка движка потеряла смысл. С одной стороны, просились радикальные изменения, но их реализация неизбежно увеличивала риски новых дефектов, и было-бы крайне нерационально привносить эти риски в промышленно эксплуатируемый сервис. С другой стороны, параллельная доработка без реальной живой потребности в ней, чревато «работой в стол» и усложнением поддержки эксплуатируемой версии.
Не углубляясь в детали, можно уверенно сказать, что в LMDB есть масса проблем и недостатков, устранить которые можно только кардинальной переработкой API и ещё более существенной переработкой формата файлов БД. В LMDB сделать подобное крайне затруднительно, так как фактически это будет означать создание нового движка и взорвет все зависящие проекты. В случае libmdbx подобного барьера не было, изменения напрашивались с самого начала, «зудели и кровоточили». Однако, по совокупности вышеназванных причин задуманные доработки «стояли на паузе» до 2017. Кроме этого, необходимость изменений заставляла требовала не рекламировать libmdbx, чтобы в итоге создать неудобства меньшему количеству пользователей.
Начиная же с 2017 года, понемногу, реализовывались не-кардинальные, но необходимые доработки, с постепенным увеличением масштаба и амплитуды. Так в частности, была возвращена поддержка Windows, а также решены проблемы с завершением потоков из-за архитектурных дефектов в thread-local-storage destructors в GNU libc.
Завершенные доработки
Здесь и далее подразумевают доработки и новые возможности относительно LMDB, как прародителя MDBX (libmdbx). Текущая версия (ветка master) содержит более 25 различных доработок и все они приемлемо-подробно описаны в README. Поэтому здесь приведем лишь некоторые ключевые:
- Поддержка LIFO порядка при «переработке мусора». Из-за чего цикл использования страниц памяти и секторов диска
становился минимальным, что снижает эффект вымывание кэша и на порядок увеличивает эффективность очередей обратной записи;
- Поддержка пользовательского обработчика для случая исчерпания свободного места в БД из-за блокирования сборщика
мусора долгими транзакциями чтения. Это позволяет управлять ситуацией, а в случае ReOpenLDAP позволило предотвратить «случайные» отказы сервиса;
- Полная переработка пути записи на диск, что дает гарантию сохранности БД. Проще говоря, libmdbx в отличие от LMDB
в ряде режимов при аварии потеряет последние изменения, но не разрушит всю базу.
В 2017 году был начат процесс реализации задуманных доработок, включая изменения формата файлов БД. При этом внезапно образовалась неожиданная проблема — очень давно и очень многое хотелось изменить или переделать. Так давно, что многое уже забылось, а глаза привыкли к странностям кода и перестали их замечать. И так много, что начиная что-то менять неудержимо втягиваешься в переделку всего, в изменение каждой строчки кода…
Тем не менее, в этом году уже удалось сделать и довести до эксплуатации большие и важные доработки:
- Унификация формата файлов и структур для 32-битных и 64-битных сборок, включая переход на 32-битные номера
страниц.
- Поддержку трех мета-страниц вместо двух, что на самом деле означает возможность прозрачно и произвольно
комбинировать «сильные» и «слабые» точки фиксации, одновременно гарантированно и надежно соблюдая MVCC как для всех читателей, так и на случай любых аварий.
- Управление геометрией, включая выбор размера страниц, контролируемое увеличение и уменьшение размера БД.
- Автоматическую компактификацию БД без дополнительных затрат, с последующим автоматическим освобождением места на
диске. Стоит пояснить, что в LMDB это большая боль, так как однажды увеличенный файл БД может быть уменьшен только путем копирования с компактификацией.
Планируемые доработки и новшества
- Переработка API c ликвидация хрупкости.
Если говорить кратко, то унаследованное API имеет много сложно связанных опций/флажков и соглашений, нарушение которых может приводить к сложно обнаруживаемым ошибкам.
Отдельного упоминания заслуживает путаница с термином «database» и странности API открытия/закрытия ассоциативных массивов. Из-за чего совершенно нетривиально эффективно организовать координацию читающих MVCC-транзакций с созданием и/или удалением таких массивов.
- Асинхронная догоняющая фиксация данных на диске.
Технически libmdbx позволит запускать дополнительный thread, который будет заниматься фоновой фиксацией данных и формированием «сильных» точек фиксации.
С точки зрения пользователя это добавит режимы «ленивой» и «догоняющей» фиксации данных, что с точки зрения обеспечения сохранности данных аналогично ведению журнала с асинхронной его фиксацией.
- Рефакторинг структур для уменьшения накладных расходов.
Кроме изменения заголовков страниц будет переработан формат хранения списков.
- Возможность размещения больших страниц в отдельном файле.
Технически эта большая переработка, затрагивающая все механизмы движка, которая позволит вынести хранение «больших записей» на отдельный носитель. В результате становится возможной гибридная модель хранения (например SSD + HDD), при которой индексы и короткие значения хранятся на быстром носителе, а большие данные вынесены на дешевый.
С учетом внутренних механизмов libmdbx такая модель может быть предельно эффективной по показателю цена/производительность: для поиска данных используется быстрый носитель, а при доступе к большим записям происходит адресное последовательное чтение с дешевого носителя.
- Контрольные суммы страниц.
Контроль содержимого страниц на основе CRC64 или t1ha позволит обнаруживать ошибочное изменение данных. Выбор функции будет производиться при создании БД, причём для t1ha будет возможность выбрать вариант допускающие аппаратную акселерацию (AES-NI).
- Контроль консистентности БД посредством Merkle Tree.
Технически эта большая переработка, требующая эффективной реализации «обратной волны» при обновлении страниц.
С точки зрения пользователя появиться возможность верифицировать состояние БД, также как git проверяет совокупную целостность всех файлов в большом иерархическом проекте.
- Аварийный сборщик мусора.
Позволит решить архитектурно-обусловленную проблему переполнения БД (исчерпания свободных страниц) из-за остановки сборки мусора на долгой читающей транзакции. Технически доработка сводиться к выявлению свободных страниц путем обхода B+Tree дерева для каждого используемого/читаемого снимка БД.
С точки зрения пользователя, в результате эффективность использования места в БД, даже в проблемных ситуациях, сравняется с таким СУБД как Oracle. DB2, MSSQL, PostgreSQL и т.р.
Примечания и ссылки
!.jpg)
Plays:239 Comments:0