Free software porting on the Elbrus architecture (Андрей Савченко, LVEE-2019)
Материал из 0x1.tv
- Докладчик
- Андрей Савченко


The Elbrus (aka E2000, aka E2K) is the unique Russian VLIW CPU with its own architecture, instruction set and security features. In this talk we'll discuss main architecture features interesting for general software developers, particularities of the system compiler and main obstacles during software porting. Interaction with various free software upstreams will be discussed as well.
Содержание
Видео
Презентация























Thesis
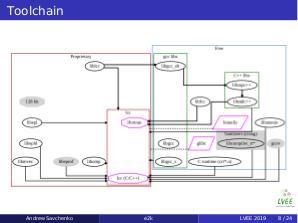
Unlike most other CPUs available the Elbrus family (E2K) uses a VLIW instruction set (Very Large Instruction Word) and features 25 general instructions per cycle. Such dependency puts much more demands on the system compiler for optimization. Furthermore in order to minimize the silicone usage every high level function possible was moved from the hardware to the compiler, so roughly speaking there is no microcode and microcode-level operations are done during a compile time, not run-time like on x86 family of CPUs.
While such approach yields better power usage and performance per number of transistors used, it’s side effect is that the only system compiler — the LCC — is closed source and will likely stay that way. The LCC tries to mimic GCC by user interface (both supported options and GCC-specific features) but here similarity ends. The LCC is based on EDG frontend and MCST-made multi-layer backend.
However, free software is also used in the compiler toolchain:
libstdc++, libatomic, libgcc_s, the C runtime and so on. It was a challenging task to separate all free components from the compiler bundle, build them from the source and package them apart from binary blobs left to form fully functional toolchain meeting the distribution standards (ALT in our case).
While the Elbrus machine supports running x86 and amd64 instruc- tions using run-time JIT compiler for x86/amd64 assembly, we do not use this mode for both performance and security reasons. This JIT compiler is left for special purposes like running proprietary closed source software without native E2K support.
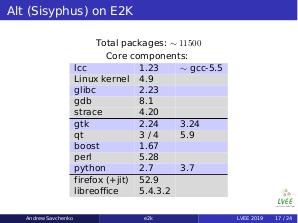
Most software porting problems rise from the lack of full compatibility with GCC due to various reasons. The main problem is that the EDG frontend — which is responsible for parsing program’s syntax — lags behind the GCC in supported language features, e.g. current production version lcc-1.23 is on par with gcc-5.5. So many code needs backporting to older C++ standard or similar tweaks in order to build on the E2K.
However, there are other cases as well:
- Sometimes the LCC notices problem which GCC skips like uninitialized variable usage. This causes problem especially in combination with -Werror. Sometimes we fix such problems, some- times we just disable -Werror.
- lcc-1.23 implements not all extended data types from gcc-5.5, e.g. __(u)int128_t and _Decimal64. Such problems are usually easily solved by macro definitions.
- Not all GCC builtins are implemented, some may never be.
- LCC’s preprocessor assumes input to be C/C++ code and replaces indentation tabs with spaces. This breaks applications which use a compiler’s preprocessor to parse Makefiles and similar tabulation sensitive data.
- Some software depends on tricky GCC features, e.g. on
undocumented VLAIS (variable length array in structure) or on writing C++ code «careful enough» to not to use C++ runtime and to link such code as normal C code. While such tricks work with gcc, they create many problems with other compilers, sample case is libgraphite2. Such problems are solved on case-by-case basis and prone to be painful issues.
For now the LCC supports only C, C++ and Fortran. So it is not possible to build and use on the E2K in native mode software written in languages with their own code generators like Go, Rust and Haskell. This problem should be solved with ongoing effort to create an LLVM backend for the LCC, but ETA is unknown.
Aside from compiler induced issues the E2K has significantly different hardware architecture besides using VLIW. It feature three independent stacks: for data, for function pointers and for function arguments. This way a system is hardware protected from many kinds of buffer overflow and pointer hijacking attacks. But there is price to pay: low-level memory manipulations like garbage collectors or context switching should be rewritten to take into account this stack layout.
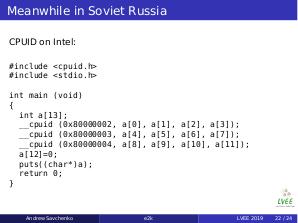
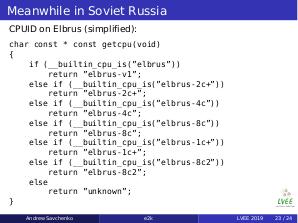
Of course system calls and ioctls are also partly different and such difference should be taken into account while porting software using these calls directly. But this is the common rule for all new architectures.
The E2K also supports a tagged memory, but we do not use this mode to build general purpose applications since drastic changes are required to work in strict security environment, e.g. all virtual calls in C++ will be invalidated by design. More details on the E2K hardware architecture and security features may be learned from the MCST official textbook.
Upstreaming software for the Elbrus has its limitations, but is
possible. The main obstacle is that both hardware and software are distributed by MCST under NDA for now, thus we cannot publish patches received from them without prior approval. However, we are free to upstream all own code including low-level stuff and assembly. And the ALT team already upstreamed E2K-specific changes to many free software projects like ruby, lxc, gimagereader, imake. More complete list is available at our wiki.
All people are different, upstreams are different as well. Some gladly accept patches, some are not interested and ignore changes, some
demand the toolchain to be opened before accepting any changes. With some luck NDA restrictions may be mostly lifted in the future and this beautiful architecture will see a second wind in its development.
!.jpg)
Примечания и ссылки
- [ Talks page]
- Discuss on Facebook
- Discuss on VK
Plays:1061 Comments:7