Опеншифт — Кубернетес с человеческим лицом (Вадим Рутковский, LVEE-2019)
Материал из 0x1.tv
- Докладчик
- Вадим Рутковский


Openshift is a project based on Kubernetes --- an orchestration platform for containers. The priority is shifted from container management to ease of development and deployment.
This talk is showcasing most common usecases for container orchestration, the history of Kubernetes and distinctive features of OpenShift itself
Содержание
Видео
Презентация














Thesis
Openshift is a Red Hat developed project, based on Kubernetes. This talk would lead you through the main aspects of container orchestration and openshift-specific features.
Intro
Why would I want to orchestrate containers?
Containers have gone a long way from initial PoC-quality demos to a wide adoption by large companies, e.g. Google. The main selling point for containers was not just ease of use by developers — but also the ability to be controlled in the same fashion as VMs while being more lightweight. While Docker was providing developers with a dev/stage environment locally, early adopters have realized that a single daemon is not enough — the images should be tracked, carefully updated, some containers would need to be recreated etc.
Thus the idea of container orchestration has emerged. After several years of a fierce fight between container orchestration technologies, we now have a clear winner — Kubernetes, initially created by Google.
What does it has to do with Openshift?
Openshift is based on Kubernetes, it has every API endpoint kube has. One might say its a fork, but the relationship is much closer — its being rebased after every kubernetes release. Red Hat engineers are working on Kubernetes itself, although some Openshift abstraсtions are not available in Kubernetes.
Hybrid clouds
While virtually any provider is now making its own Kubernetes distribution which one should I pick?
There’s certainly several answers to this question, depending on plans, existing infrastructure, legal restrictions and existing contracts. Red Hat is affilated with any of the existing cloudprovider and doesn’t bind you to a specific cloud provider. This strategy is called «Hybrid Cloud», which means you can run OpenShift on various platforms — bare metal, vSphere, GCP — and the interface / API would remain the same, unlike other solutions. This empowers the customer to decide which part of the workfload should be performed by a particular cloud solution.
DEVELOPERS DEVELOPERS DEVELOPERS
Openshift’s goal is to simplify operations for developers. In a standard k8s distribution usual developer workflow is the following:
- Commit code and push it to a branch. Create PR/MR optionally
- If CI is setup for the project wait for it produce artifacts. In container world this is of course container image. CI is also resposible for tagging the image with a unique tag, so that the tag can be traced back to the particular commit
- Update deployment with new container tag
- Perform additional actions — run DB migrations This can be performed by CI system, given that it has access to k8s cluster
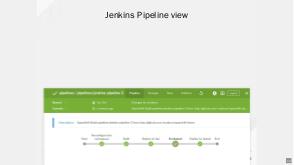
- Wait for deployment to rollout and run acceptance/end-to-end tests
This process requires at least two additional entities — CI (with sufficient amount of yaml/groovy/bash glue) and docker registry to store built container images. Note, k8s is acting only when a deployment image tag needs to be changed — the rest should be properly coded, tested and maintained by an engineer.
OpenShift is aimed to simplify the whole process. First of all, it comes with an integrated docker registry. Its using internal SDN and takes care of caching of built images. It also has an API, so whenever a new image is being pushed there it can be inspected using standard kubernetes API — using «kind: ImageStream» and «kind: ImageStreamTag».
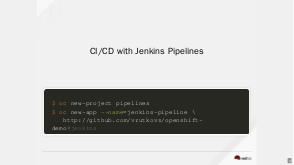
Another important part of this simplified pipeline is building new images. This may involve caching builds, fetching fresh base images and keeping enough information about SCM commit hash. K8s specifically tries to avoid the whole complexity of this, as any build now requires elevated privileges.
In order to simplify this OpenShift includes additional types — called Builds and BuildConfigs. These native k8s objects are taking care building container images and pushing them to internal (or external) registry. The build process also includes adding labels to track the source of the image — SCM url, commit hash, author etc. This improves observability of the running infra (a.k.a «which commit is actually deployed now»).
BuildConfig can be triggered by changes in ImageStream, so it can start a new build automatically whenever a base image has been built a new build for «child» images would start. OpenShift also includes a webserver to accept webhooks, so the build can be triggered by an external event, e.g. Gitlab commit.
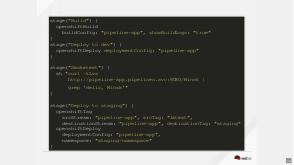
Updating image in the deployment may look simple, but if that would make rollback to a working version complex. In order to solve this OpenShift introduces DeploymentConfigs — this object would create new deployments when triggered — and keep the history of the existing deployments, so that the user could easily rollback to any known-to-be-good deployment when necessary.
These parts are working together, but neither of them is required — developers can replace specific parts with their own implementation (e.g. an external Docker registry) and use k8s HTTP API or ‘kubectl‘/ ‘oc‘ CLI tool.
Batteries included
Most k8s distributions don’t simply deploy an API server — these also come with additional tools, which simplify cluster maintenance. Most popular are probably k8s dashboard and Prometheus for cluster monitoring.
OpenShift is an opinionated k8s distribution, so it has console, router (similar to ingress controller in vanilla k8s), container registry and Prometheus monitoring solution. Other options — for instance, ELK stack for persistent logging are available as additional components.
Operators
Most k8s distributions are being installed and maintained by a set of additional tools. For instance, ‘kubeadm‘ will take care of setting up the cluster and rotating certificates, but its useless if the task is to update packages on the host. Most k8s distros are using commonly-known Linux distributions to carefully setup container engine, bring necessary packages and configuration on the host and get k8s to start.
This however leaves maintenance burden on the ops team — they have to use additional instruments to update, reconfigure and keep this state-of-art set of components running.
Openshift 4 is different in this area — it uses a concept of «operators» to config, maintain and update components. In k8s context an operator is a simple application which is aware that its running in a k8s cluster — and it uses k8s API to start new application(s), watch them start and update them if necessary. If several applications need to be kept in sync (e.g. Prometheus URL and Grafana’s datasource URL) the operator can expose a single configuration entry to configure both apps without desync. In k8s operators are using CRDs — Custom Resource Definitions — for configuration and status updates. Other operators may read these settings and update themselves accordingly.
Operators are a handy concept to bring the cluster to a defined state — and maintain that state. For instance, if the operator creates a deployment it also watches it. If the deployment is removed or changed the operator would create it or reconfigure it back. This strategy simplifies maintenance — operator would take care of necessary steps when config is changed — and updates, as operator knows if any migrations need to be performed between two versions on update.
OpenShift as a platform also takes care of the underlying operating system. A dedicated operator — Machine Controller Operator — is running a daemon, which reads MachineConfig settings from cluster and applies the changes on OS machines. MachineConfig stores file configuration in a format similar to Ignition – base64-encoded files and systemd units.
Upgrades
Operator pattern simplifies a core cluster function — an ability to do zero downtime upgrades. Once all the cluster is being controlled by operators, an upgrade is essentially a matter of updating particular operators in specific order (for instance, network and apiserver operators are more important than monitoring). Machine Controller operator is also managing underlying OS upgrade. In common-purpose OSes upgrades are inherently unsafe — this is why OpenShift 4 is using RHEL CoreOS instead. This OS is a successor for RHEL Atomic and uses ostree deployments to store RPMs (which are coming from standard RHEL repositories). This system allows us to create a new ostree deployment with an update — and in case it doesn’t boot or breaks something important the OS will always have a previous deployment to boot into.
Additional operator
Red Hat has also released a set of tools to create your own operators — operator-sdk. It enables developers to use Golang, Ansible or Helm to control their deployment using additional CRD to extend any kubernetes platform. These operators could be uploaded to OperatorHub.io, so that developers would not have to look for those in some shady places like Dockerhub.
OpenShift also includes Operator Lifecycle Manager operator — it integrates operators from OperatorHub.io in openshift console and takes care of setting up, configuring and updating additional operators.
Can I run this on my machine?
‘try.openshift.com‘ is the place to start. It requires free developer subscription to get started and guides newcomers through install process.
!.jpg)
Примечания и ссылки
- [ Talks page]
- Discuss on Facebook
- Discuss on VK
Plays:279 Comments:1