T1ha — самая быстрая, переносимая, 64-битная хэш-функция (Леонид Юрьев, OSSDEVCONF-2017)
Материал из 0x1.tv
- Докладчик
- Леонид Юрьев


В докладе представляется некриптографическая хеш-функция t1ha — переносимая и чрезвычайно быстрая на современных процессорах. Кроме базового переносимого варианта также предлагается несколько платформо-зависимых вариантов, способных выполнять хеширование на скоростях близких к пропускной способности памяти.
При этом базовый вариант t1ha имеет регулярную структуру, в статистических тестах качества не уступает никому из своей весовой категории, а по субъективным оценкам лучше конкурентов. Все функции проходят все тесты SMHasher без каких-либо замечаний.
Содержание
Видео
Посмотрели доклад? Понравился? Напишите комментарий! Не согласны? Тем более напишите.
Презентация






Thesis
Опустим определение хэш-функций вместе с детальным перечислением свойств и требований для их криптографического применения, предполагая что читатель либо владеет необходимым минимумов знаний, либо восполнит их из открытых источников, включая Википедию. Также условимся, что здесь и далее мы подразумеваем некриптографические (криптографически не стойкие) хэш-функции, если явно не указывается иное.
Хэширование применяется в массе алгоритмов, при этом практически всегда требуется максимально эффективная (быстрая) обработка данных, одновременно с соблюдением некоторого минимального уровня качества хеширования. Причём под «качеством», прежде всего, понимается «условная случайность» (стохастичность) результата относительно исходных данных. Несколько реже предъявляются дополнительные требования: устойчивость к преднамеренной генерации коллизий или необратимость.
Для стройности изложения необходимо определить понятия «качества» хэш-функции и остальные требования чуть более детально:
- Базовое качество: Изменение одного или более произвольных бит в произвольном наборе исходных данных, приводит к изменению каждого бита результата с вероятностью ½.
- Необратимость (стойкость к восстановлению прообраза): Невозможность получения исходных данных или отдельных битов по результату хеширования.
- Устойчивость к подбору хэша (стойкость к коллизиям первого рода): Сложность поиска/подбора исходного набора данных с целью получения заданного результата или даже отдельных его битов.
- Устойчивость к подбору сообщений (стойкость к коллизиям второго рода): Сложность поиска/подбора двух разных наборов данных, которые давали бы одинаковый результат или совпадение отдельных битов.
Опуская цитирование доказательств и прочие выкладки можно констатировать:
- Надлежащее выполнение всех пунктов, одновременно с обеспечением производительности, является достаточно трудной задачей, решение которой даёт хорошую криптографическую хэш-функцию.
- Обеспечение базового качества требует достаточно большого количества операций АЛУ. Проще говоря, качество всегда конфликтует со скоростью.
- Получение качественного результата с разрядностью больше разрядности операций АЛУ требует более чем кратного увеличения количества перемешиваний, а следовательно базовых операций АЛУ.
- В целом, создание быстрой кэш-функции предполагает достижения взвешенного компромисса между скоростью, качеством и разрядностью результата.
Исходя из вышесказанного, можно сказать, что t1ha появилась в результате поиска компромисса между качеством и скоростью, одновременно с учетом возможностей современных процессоров и уже найденных способов (арифметико-логических комбинаций) перемешивания и распространения зависимостей (лавинного эффекта).
Базовый вариант t1ha является (самой) быстрой переносимой хэш-функцией для построения хэш-таблиц и других родственных применений. Поэтому базовый вариант t1ha ориентирован на 64-битные little-endian архитектуры, принимает 64-битное подсаливающее значение (seed) и выдает 64-битный результат, который включает усиление длиной ключа. Стоит отметить, t1ha намеренно сконструирована так, чтобы возвращать 0 при нулевых входных данных (ключ нулевого размера и нулевой seed).
Оценить качество хэш-функции во всех аспектах достаточно сложно. Можно идти аналитическим путем, либо проводить различные статистические испытания. К сожалению, аналитический подход малоэффективен для оценки хэш-функций с компромиссом между качеством и скоростью. Причем сравнительная аналитическая оценка таких функций стремиться к субъективной.
Напротив, для статистических испытаний легко получить прозрачные количественные оценки. При этом есть хорошо зарекомендовавшие себя тестовые пакеты, например SMHasher. Для t1ha результаты просты — все варианты t1ha проходят все тесты без каких-либо замечаний. С другой стороны, не следует считать, что у t1ha есть какие-либо свойства сверх тех, что необходимы для целевого применения (построение хэш-таблиц).
Бенчмарки
Стоит пояснить наличие в заголовке словосочетания «самая быстрая». Действительно, крайне маловероятно, что существует хэш-функция, которая будет полезной и одновременно самой быстрой на всех платформах/архитектурах. На разных процессорах доступны разные наборы инструкций, а схожие инструкции выполняются с разной эффективностью. Очевидно, что «всеобщая самая быстрая» функция, скорее всего, не может быть создана. Однако, представляется допустимым использовать «самая быстрая» для функции, которая является переносимой и одновременно самой быстрой как минимум на самой распространенной платформе (x86_64), при этом имея мало шансов проиграть на любом современном процессоре с достойным оптимизирующим компилятором.
В состав исходных текстов проекта входить тест, который проверяет как корректность результата, так и замеряет скорость работы каждого реализованного варианта При этом на x86, в зависимости от возможностей процессора (и компилятора) могут проверяться дополнительные варианты функций, а замеры производится в тактах процессора.
Кроме этого, на сайте проекта приведены таблицы с результатам замеров производительности посредством доработанной версии SMHasher от Reini Urban. Соответственно, все цифры можно перепроверить и/или получить результаты на конкретном процессоре при использовании конкретного компилятора.
Здесь же можно привести сопоставление с некоторыми ближайшими конкурентами t1ha.
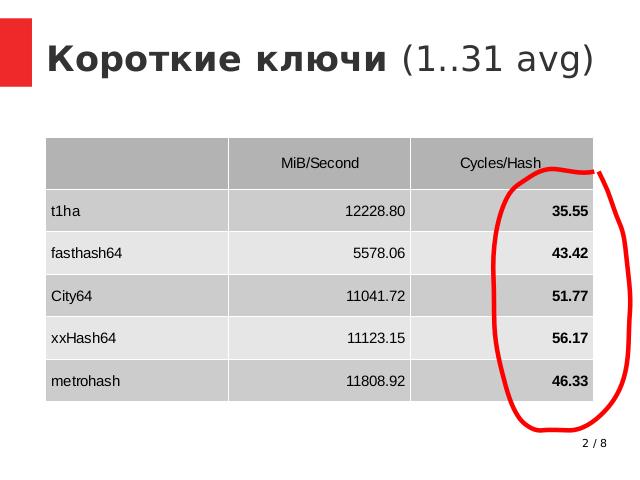
Хэширование коротких ключей (среднее для 1.31 байта, см. Табл.). Смотрим на правую колонку «Cycles/Hash» (чем меньше значение, тем быстрее):
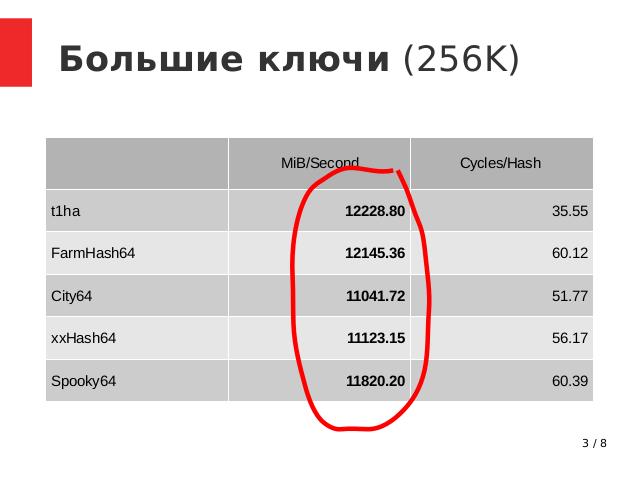
Хэширование длинных ключей (256 Кб, см. Табл.). Смотрим на среднюю колонку «MiB/Second» (чем больше значение, тем быстрее):
Варианты t1ha
Разработка t1ha преследовала сугубо практические цели. Первой такой целью было получение быстрой переносимой и достаточно качественной функции для построения хеш-таблиц.
Затем потребовалась максимально быстрый вариант хэш-функции, который давал-бы сравнимый по качеству результат, но был максимально адаптирован на целевую платформу. Например, базовый вариант t1ha работает с little-endian порядком байт, из-за чего на big-endian архитектурах требуется конвертация с неизбежной потерей производительности. Так почему-бы не избавиться от лишних операций на конкретной целевой платформе? Таким же образом было добавлено ещё несколько вариантов:
- Упрощенный вариант для 32-битных платформ, как little, так и big-endian.
- Вариант с использованием инструкций AES-NI для процессоров без AVX.
- Два варианта с использованием инструкций AES-NI с использованием AVX.
Чуть позже стало понятно что потребуются ещё варианты, сконструированные для различных применений, включая разную разрядность результата, требования к качеству и стойкости. Такое многообразие потребовало наведения порядка. Что выразилось в смене схемы именования, в которой цифровой суффикс обозначает «уровень» функции:
t1ha0() — максимально быстрый вариант для текущего процессора.
t1ha1() — базовый переносимый 64-битный вариант t1ha.
t1ha2() — переносимый 64-битный вариант с чуть большей заботой о качестве.
t1ha3() — быстрый переносимый 128-битный вариант для получения отпечатков.
и т.д.
В этой схеме предполагается, что t1ha0() является диспетчером, который реализует перенаправление в зависимости от платформы и возможностей текущего процессора. Кроме этого, не исключается использование суффиксов «_le» и «_be» для явного выбора между little-endian и big-endian вариантами.
Таким образом, под «вывеской» t1ha сейчас находиться несколько хеш-функций и это семейство будет пополняться, в том числе с прицелом на отечественный E2K «Эльбрус».
Представление о текущем наборе функций и их свойствах можно получить из вывода теста. Стоит лишь отметить, что все функции проходят все тесты SMHasher, а производительность вариантов AES-NI сильно варьируется в зависимости от модели процессора:
Simple bench for x86 (large keys, 262144 bytes):
t1ha1_64le: 47151 ticks, 0.1799 clk/byte, 16.679 Gb/s @3GHz
t1ha1_64be: 61602 ticks, 0.2350 clk/byte, 12.766 Gb/s @3GHz
t1ha0_32le: 94101 ticks, 0.3590 clk/byte, 8.357 Gb/s @3GHz
t1ha0_32be: 99804 ticks, 0.3807 clk/byte, 7.880 Gb/s @3GHz
Simple bench for x86 (small keys, 31 bytes):
t1ha1_64le: 39 ticks, 1.2581 clk/byte, 2.385 Gb/s @3GHz
t1ha1_64be: 42 ticks, 1.3548 clk/byte, 2.214 Gb/s @3GHz
t1ha0_32le: 51 ticks, 1.6452 clk/byte, 1.824 Gb/s @3GHz
t1ha0_32be: 54 ticks, 1.7419 clk/byte, 1.722 Gb/s @3GHz
Simple bench for AES-NI (medium keys, 127 bytes):
t1ha0_ia32aes_noavx: 72 ticks, 0.5669 clk/byte, 5.292 Gb/s @3GHz
t1ha0_ia32aes_avx: 78 ticks, 0.6142 clk/byte, 4.885 Gb/s @3GHz
t1ha0_ia32aes_avx2: 78 ticks, 0.6142 clk/byte, 4.885 Gb/s @3GHz
Simple bench for AES-NI (large keys, 262144 bytes):
t1ha0_ia32aes_noavx: 38607 ticks, 0.1473 clk/byte, 20.370 Gb/s @3GHz
t1ha0_ia32aes_avx: 38595 ticks, 0.1472 clk/byte, 20.377 Gb/s @3GHz
t1ha0_ia32aes_avx2: 19881 ticks, 0.0758 clk/byte, 39.557 Gb/s @3GHz
Чуть подробнее о внутреннем устройстве
Если говорить чуть более детально, то t1ha построена по схеме Меркла-Дамгарда (энтропийная губка) с упрочнением от размера данных и подсаливающего значения. Внутри основного сжимающего цикла используется 256-битное состояние, с аналогичным размером входного блока. Причем для каждого операнда данных реализуется две точки инъекции с перекрестным опылением. По завершению сжимающего цикла выполняется сжатие 256-битного состояния до 128 бит.
При выполнении описанных действий используются 64-битные операции, комбинирующие миксеры ARX (Add-Rotate-Xor) и MUX-MRX (Mul-Rotate-Xor). Немаловажно, что все эти вычисления выстроены так, чтобы обеспечить возможность параллельного выполнения большинства операция и плотной укладки u-ops как в конвейер, так и в исполняющие устройства x86_64. За счет этого достигается достаточно хорошее качество при практически предельной скорости хэширования длинных ключей.
Стоит отметить, что сжимающий цикл запускается только для блоков достаточного размера. Если же данных меньше, то промежуточное 128-битное состояние будет состоять только из размера ключа и подсаливающего значения.
Далее, оставшийся хвост данных порциями по 64 бита подмешивается попеременно к половинам 128-битного состояния. В заключении выполняется перемешивание состояния одновременно со сжатием до 64-битного результата. Немаловажной особенностью t1ha здесь является использование миксера на базе широкого умножения (128-битное произведение двух 64-битных множителей). Это позволяет реализовать качественно перемешивание с хорошим лавинным эффектом за меньшее количество операций. Несмотря на то, что широкое умножение относительно дорогая операция, меньшее количество операций позволяет t1ha обрабатывать короткие ключи за рекордно малое количество тактов процессора.
Следует отметить, что используемый миксер на основе широкого умножения и исключающего ИЛИ не идеален. Несмотря на то, что t1ha проходит все тесты SMHasher, у автора есть представление о последствиях неинъективности. Тем не менее, результирующее качество представляется рационально-достаточным, а в планах развития линейки t1ha уже отражено намерение предоставить чуть более качественный вариант.
Примечания и ссылки
!.jpg)
Plays:109 Comments:2