PioNER — Наборы данных и базовые методы для распознавания именованных сущностей в армянском языке (Цолак Гукасян, ISPRASOPEN-2018)
Материал из 0x1.tv
- Докладчик
- Цолак Гукасян


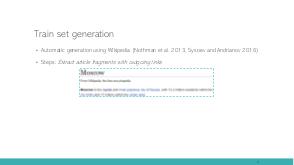
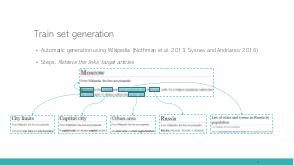
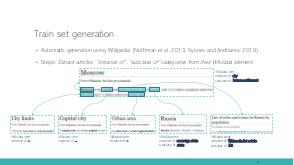
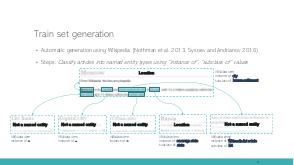
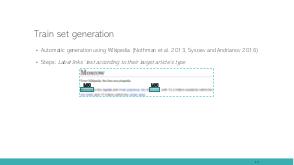
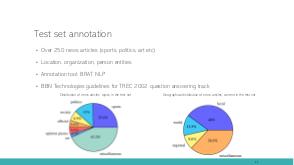
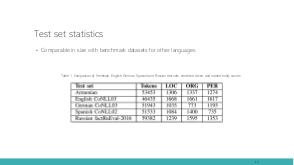
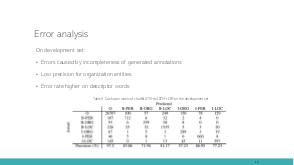
In this talk we tackle the problem of Armenian named entity recognition, providing silver- and gold-standard datasets as well as establishing baseline results on popular models. We present a 163000-token named entity corpus automatically generated and annotated from Wikipedia, and another 53400-token corpus of news sentences with manual annotation of people, organization and location named entities. The generated corpus was used to train several popular named entity recognition models, which then were evaluated on the gold-standard corpus. Apart from the datasets, we also release 50-, 100-, 200-, 300-dimensional GloVe word embeddings trained on a collection of Armenian texts from Wikipedia, news, blogs, and encyclopedia, which we used in our experiments.
Видео
Посмотрели доклад? Понравился? Напишите комментарий! Не согласны? Тем более напишите.
Презентация










!.jpg)
Примечания и ссылки
Plays:19 Comments:2