Современное состояние исследований и разработок в области автоматического анализа программ (Александр Герасимов, SECR-2019)/Стенограмма
Материал из 0x1.tv
Статья-стенограмма доклада Современное состояние исследований и разработок в области автоматического анализа программ (Александр Герасимов, SECR-2019)
Доброе утро господа, меня зовут Герасимов Александр и мой доклад посвящен современному состоянию исследований разработок в области автоматического анализа программ.

Немножко себе. Я последние 14 лет работаю в Институте Системного Программирования РАН имени Иванникова, непосредственно темой моих исследований является создание автоматических инструментов для обнаружения ошибок в программах. Автоматически — значит без участие человека какого-то ни было, ну разве что инструмент запустить.
Работал по контракту с компанией Сlockwork, мы разрабатывали движок статического анализа исходного кода программ, для языков и C/C++, плюс C#, работаем по контракту с компанией Samsung, и разрабатываем инструменты статического и динамического анализа в нашем институте для анализа программ в различных средах.
За последний год мне пришлось достаточно много общаться с компаниями разработчиками программного обеспечения, куда мы предоставляем инструменты разработанные нашем институте. И вот тема сегодняшнего доклада является следствием вопросов, которые обычно задают представители компаний, в основном разработчики. Потому что все знают про всевозможные способы статического анализа программ, но не знают, чем они отличаются.

Прежде всего давайте разберемся, что же такое «ошибка».
Есть стандартная классификация ошибок, точнее определение ошибок. Но термины по большому счету не говорят более-менее ничего. Они не имеют никакого смысла.
Начиная от того что неправильное действие пользователя это ошибка или какой-то дефект программе — ошибка. Хотя это может и не приводить неправильной работе и так далее. С моей точки зрения программа должна просто работать.

Работать корректно, в соответствии со спецификацией.
Многие задаются вопросом — зачем собственно искать ошибки, то есть программа оттестирована, она прошла все стадии верификации и ошибок быть не должно.
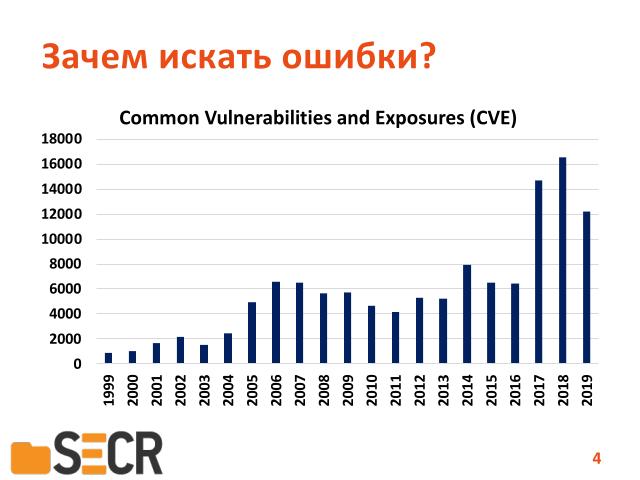
Ну вот статистика уязвимостей в программах говорит о том, что количество ошибок, зарегистрированных ошибок в программах выпущенных на рынок, растет из года в год, и в последнее время достигает достаточно больших значений — по статистике сайта «CVE Details».
Важно, когда мы говорим об анализе программ на наличие ошибок, определить ее критичность.

Ну например, если у вас программа работает закрытом контуре атомной электростанции, то наверное для вас не очень критична утечка данных — данные оттуда никуда утечь не могут.
С другой стороны если у вас программное обеспечение работает в ракете, то вас мало будет интересовать утечка памяти — ракета летит там две-три минуты и за это время вряд ли там переполнится память.
А на самолете вас вряд ли будет интересовать возможность взлома программы, которая обрабатывает телеметрию с датчиков, потому что опять таки контур закрыт.
Критичность ошибки в любом случае определяется характером автоматизированных функций вашей программы, которую вы анализируете.

Цена ошибки может быть достаточно высока.
Вчера был доклад в наших коллег из компании VIVA64, они тоже упоминали этот пример, когда ракета Ariane 5, … вызвала сигнал самоуничтожение из-за того что произошло переполнение при копировании 64-разрядного числа в 16-разрядное.
Цена ошибки, суммарно вместе со стоимостью разработки ракеты составила восемь с половиной миллиардов долларов. Полезная нагрузка — 370 миллионов.
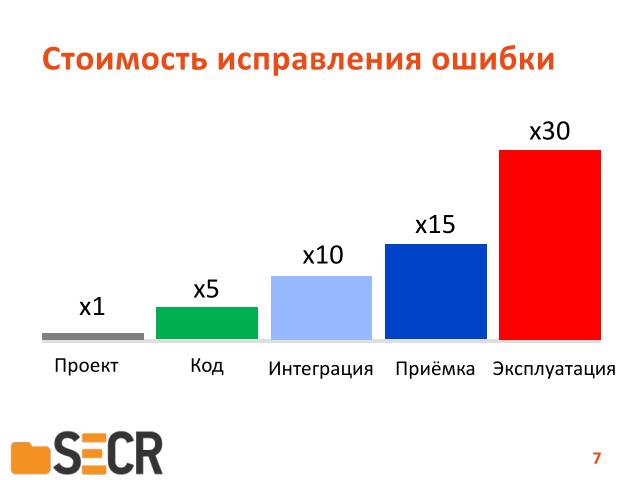
Стоимость исправления ошибки очень сильно зависит от того, на каком этапе мы ее обнаруживаем.
Здесь приведена статистика американского института NIST.
Они считают, что если во время проектирования цена ошибки — единица, исправление ошибки — единица, то на этапе эксплуатации она вырастает в 30 раз.
Поэтому надо передвигать методики поиска ошибок на как можно более ранние стадии разработки программы.

Немного истории. Первая ошибка считается зарегистрированной, с официальным отчетом — это отчет Грейс Хоппер, 9 сентября 1947 года. Когда она нашла мотылька, который замкнул контакт в компьютере Mark2, и написала об этом отчет, и ввела новый термин «дебаггинг», то есть удаление насекомых.
Можно считать, с этой даты было признано, что в программах могут быть ошибки.

Далее применялись различные методы. В основном эти методы применялись в военно-морских силах США. Было установлено, что как минимум двое человек должны посмотреть на исходную подпрограмму, т.е. провести ее инспекцию. И потом, уже во время космической программы США, начали проводить активное тестирование программ.
Разница здесь заключается в том, что в одном случае мы смотрим на код, просто человек смотрит на код, глазами.
В другом случае, случае мы применяем какие-то автоматические инструменты, которые нам показывают, как же именно программа работает.

Тестирование. Изначально тестирование было ручным, т.е. просто писались тесты, и показывали, что программа работает корректно.
Но в какой-то момент стало ясно, что программе могут дать некорректные данные и было придумано, что надо делать «исчерпывающее» тестирование программ.
Что это такое — это когда мы тестируем работу программы на всевозможных входных данных.
Ну, понятное дело, что у некоторых программ множество входных данных может бесконечно. Особенно, если идет циклическая обработка данных. Поэтому исчерпывающее тестирование было признано невозможным в некоторых случаях.
Вот этот милый дедушка на фотографии — это на самом деле Эдсгер Вибе Дейкстра.

И он в лекции о надежности программ выдал вот этот тезис, что тестирование достаточно весьма эффективно показывать наличие ошибок, но оно безнадежно неадекватно для демонстрации их отсутствия.
То есть тестирование для того, чтобы продемонстрировать на программе нет ошибок применять нельзя. Поэтому инженеры пошли дальше и решили придумать метод автоматического построения покрытий программы тестовыми наборами.

Среди них можно выделить «динамическое символьное исполнение», которое было впервые описано в 1975 году. И «фаззинг» который был описан где-то в середине восьмидесятых.
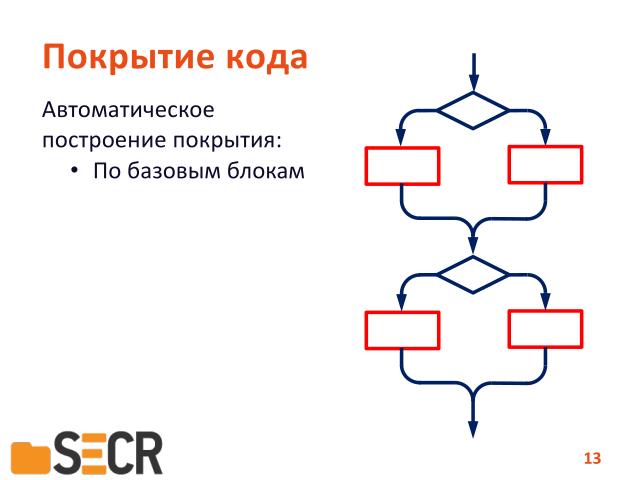
Сначала разберемся, что такое покрытие кода. Прежде всего это может покрытие по базовым блокам, то есть по-линейному, между условным ветвлениями.
Т.е. если мы хотя бы один раз прошлись по базовому блоку — мы считаем что уже достаточно протестировали его.
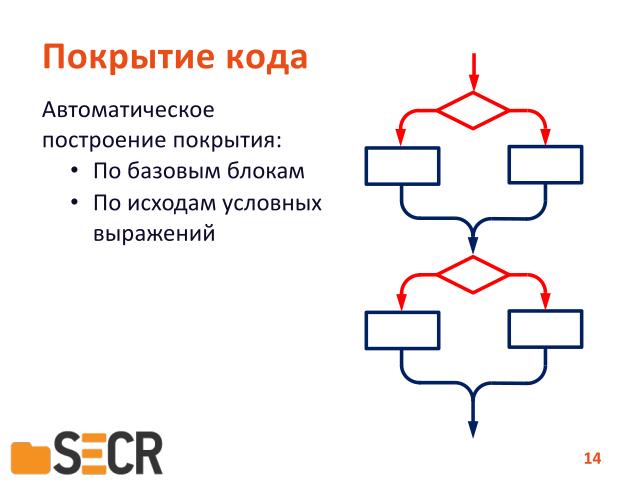
Второй тип покрытия — это по исходам условных операторов. То есть мы должны пройти по всем веткам, по «true» и по «false», а если у нас оператор выбора — то по всем вариантам выбора.
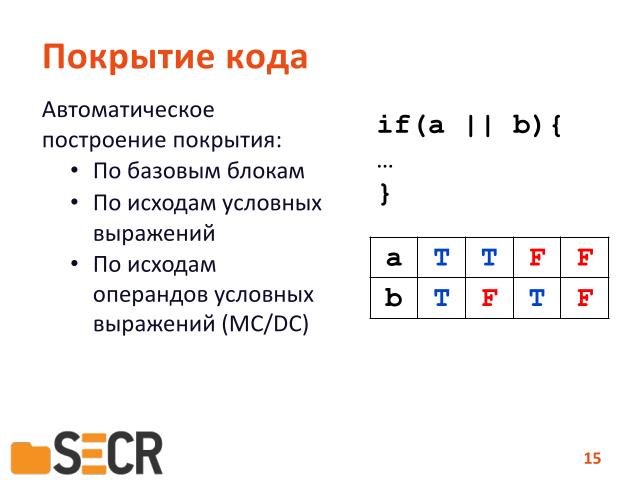
Третий тип покрытия — это покрытие по исходу операндов условных выражений. Если мы каждый операнд вычислили во всех комбинациях, в «истину» или «ложь», то мы считаем, что в принципе покрытие достаточное.
Еще эта задача называется «metric condition/decision coverage».
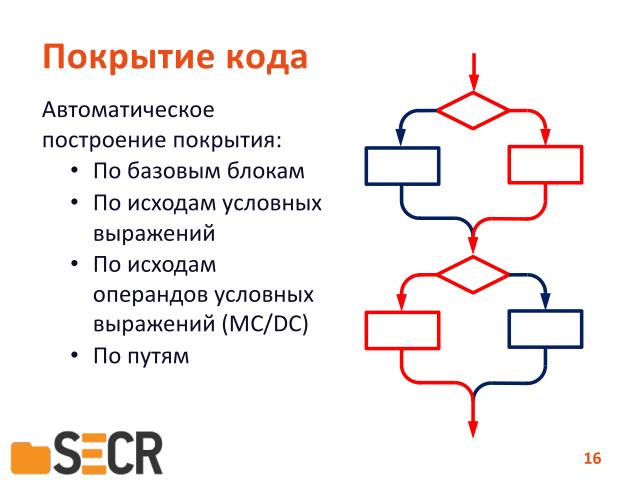
И «покрытие по путям», то есть когда мы подобрали такие набора входных данных, которые позволили пройти в программе все возможные пути исполнения.
Дальше перейдем к методам. Начнем с «фаззинга». «Фаззинг» был придуман, а точнее открыт совершенно случайно. В середине восьмидесятых, один из программистов из дома по модемной линии подключился к удаленному компьютеру, а в этот момент шел дождь и помехи на линии вносили изменения в аргументы командной строки утилит Linux и Unix, и утилиты внезапно стали работать некорректно, начали завершать свою работу с ошибкой.
Таким образом возникло предположение, что если псевдослучайным образом генерировать аргумент командной строки Unix, то их можно протестировать на устойчивость.
И было показано, что на самом деле достаточно большое количество программ работает неустойчиво.
Через несколько лет был проведет повторный тест, и что самое интересное, он показал примерно такой же результат, хотя уже была статья и выступление на конференции.
Какие виды фаззинга бывают, и чем они отличаются.
Прежде всего они отличаются по методам проверки работы программ.
То есть мы можем просто запустить программу и посмотреть на результаты работ.
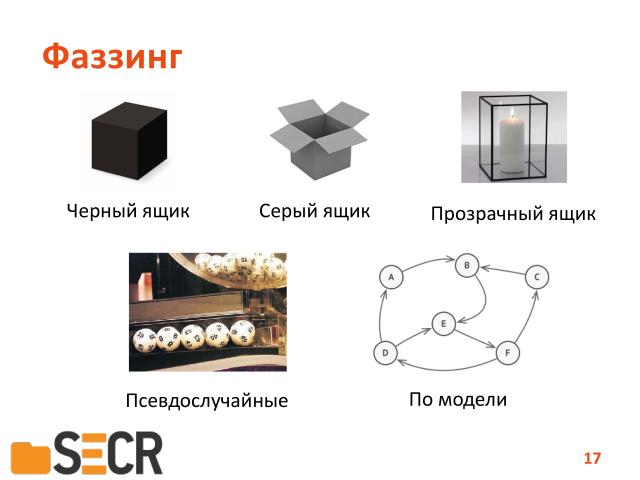
Например, завершилась она с ошибкой или нет. В этом случае, такой метод называется «тестирование черного ящика», то есть мы на вход кидаем некоторые данные, а на выходе смотрим, что происходит с самим ящиком снаружи.
Мы можем, каким бы то ни было образом проинструментировать программу, или запустить ее под отладчиком и, например, снять покрытие по базовым блокам — посмотреть сколько базовых блоков в программе было выполнено в процессе «фаззинг» тестирования. При этом мы не ориентируемся на внутреннюю структуру программы, просто подсчитываем покрытие.
Этот метод называется «метод серого ящика», вот картиночка вам иллюстрирует — как открытая коробка, в которую можете заглянуть, но не можете кого руками залезть. То есть вы видите только то, что видно через закрытую часть.
И «прозрачные ящики» или «white box» в английском, «белый ящик» — когда мы действительно знаем как внутри устроена программа и можем на самом деле ориентироваться на ее алгоритм при генерации данных.
В дальнейшем, такой метод получил название «динамического символьного исполнения», об этом будет чуть-чуть дальше.
То есть это методы анализа работы программ, отслеживание и исполнение.
Также «фазинг» отличается методом генерации данных, то есть каким способом мы генерируем данные подаваемые на вход программы.
Т.е. псевдослучайные методы, ну, здесь изображет лототрон, мы каким образом просто генерируем поток данных для программы. Можем инвертировать биты, можем переставлять слова в этом потоке, или байты… неважно, просто случайным образом их меняем.
И можем на самом деле генерировать данные по модели. Предположим, у нас есть некоторый протокол, который описывает, из какого состояния в какое может переходить поток данных и, таким образом, используя конечный автомат, генерируем эти данные.
Сейчас применяются комбинированные методы, то есть сначала мы протокол тестируем по его спецификации описанной в виде автомата, а потом начинаем нарушать правила задаваемые этим автоматом, чтобы проверить насколько устойчивы программы к нарушению протокола.
Ну и соответственно, если мы применяем методы серого или белого ящика к совместно с генерацией данных и как-то влияем на эти данные в зависимости от покрытия — такие методы называются «генетический» или «мутационный фаззинг». Когда мы закрепляем некоторый набор, который привел например, к увеличению покрытия программы, и отталкиваемся дальше уже от него.

Но в чем проблема этого метода? Ну прежде всего представьте, что у вас есть сравнение в программе с некоторой константной величиной, то вероятность попадания значения, случайно сгенерированного, вот в это значение, с которым мы сравниваем, достаточно низка. И вот фаззер, достаточно плохо справляется с подобными условными переходами. То есть очень часто бывает, что они не могут пройти в новую часть программы, еще не открытую, только из-за того, что есть сравнение с какой-то константой. А теперь представьте, что это не просто число 32-битное, а какая-то длинная строка, и нам надо подобрать длинную строку случайным образом.
На практике же сейчас есть достаточно серьезная проблема.

Хорошо если при работе программы мы вышли за пределы выделенной страницы памяти и программа просто была остановлена операционной системой из-за нарушения доступа к памяти. А что если это не так?
Предположим, у вас есть буфер в некоторой программе, который переполнился и запортил данные на стеке. Программа продолжит выполнение, но уже с запорченными данными.
Поэтому в последнее время, время в современных компиляторах стали появляться так называемые легковесные проверки или «санитайзеры».
Вставляются некоторые проверки в программу, которые замедляют ее от десяти до двадцати процентов, но зато позволяет проверить — а вот корректно ли мы работаем с буферами или используем ли мы неинициализированные значения, есть у нас утечки памяти и тому подобное.
И соответственно применение фаззеров вместе с санитайзерами дает достаточно хороший результат, потому что санитайзеры вам дают диагностику, что в программе пошло что-то не так, но при этом программа может не обрушится. И у вас есть набор данных который показывает, что на таком наборе данных программа работает некорректно, вы можете ее отлаживать.

Среди современных инструментов можно перечислить достаточно большой набор различных фаззеров. Часть из них это коммерческие, например «Peach Fuzzing Platform»™, которые основном зарабатывает за счет продажи так называемых peach-китов, которые описывают конечные автоматы для различных протоколов. Или фаззеры для операционной системы, такие как Syzkaller, и тому подобные.
Далее мы переходим к так называемому «white box»-фаззингу, динамическому символьному исполнению.
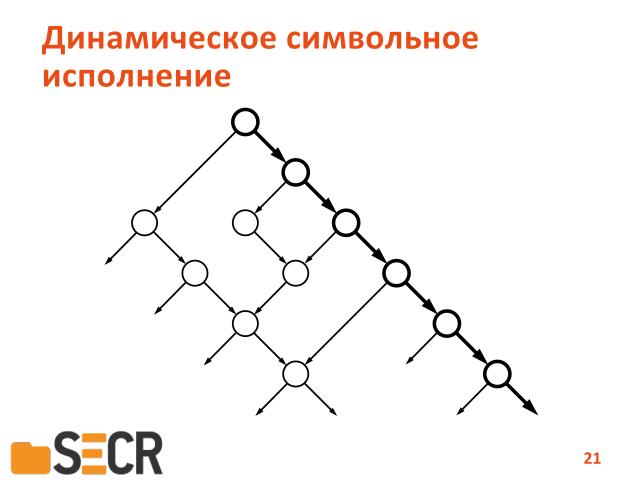
Как оно устроено. Предположим, мы запускаем программу на некотором наборе входных данных и вот жирными стрелочками показан путь исполнения программы. Это такое семантическое представление графа потока управления программы. В процессе исполнения мы собираем информацию о всех инструкциях, которые обрабатывали тем или иным способом данные, полученые из внешних данных программ. Строим формулу и пытаемся дальше с этой формулой работать следующим образом. Если нам повезло — мы можем сразу обнаружить ошибку.
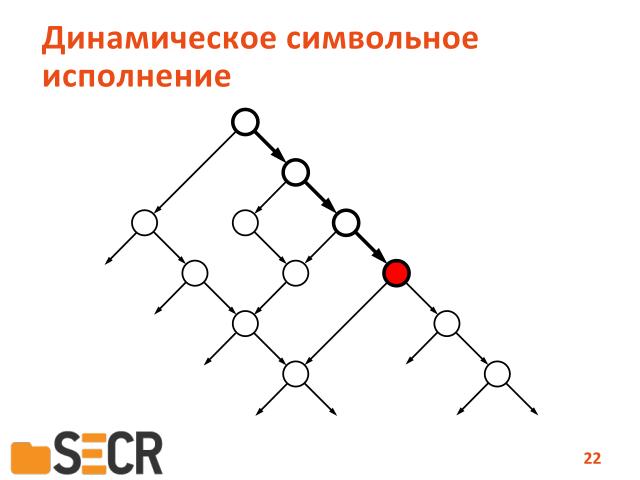
Т.е. мы случайным образом сгенерировали начальные данные и вдруг программа обрушилась. Ура, мы нашли ошибку, но в принципе, мы можем в формулу вставить специальную проверку, изменить ее, вставить некоторое условие, которое будет проверять, например, можно ли получить такой набор входных данных, чтобы в делителе операции деления попал ноль. Если такой набор вычислим, в зависимости от условий на пути условных выражений на переходах, то мы вычислим новый набор данных, можно запустить программу и таким образом, показать, что в ней есть ошибка.
Соответственно вот это вот условие «равенства делителя 0» называется «условием нарушения предиката безопасности операции». Для каждой операции на праве операции доступа к памяти есть свой предикат безопасности, для работы с утечками памяти — свой, и так далее.
Формулируя условия нарушающие эти предикаты, мы можем таким образом вычислять входные данные, причем именно вычислять — используются специальные, так называемые солверы, для «теории в условиях», и они позволяют вычислять наборы данных.
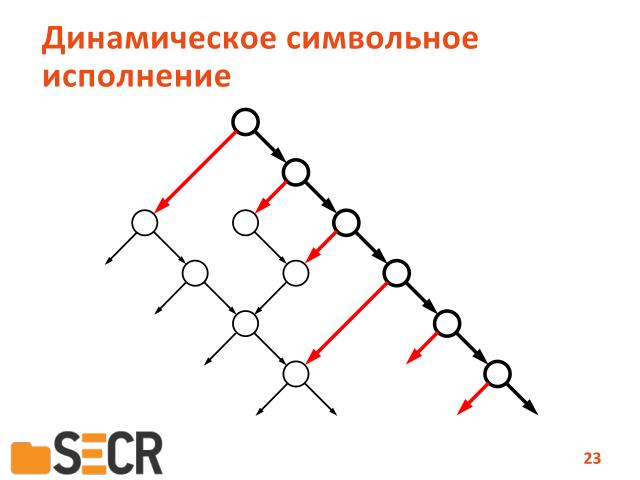
Что мы еще можем сделать.
У нас есть некоторый набор условных переходов, зависящих от внешних данных программы и мы можем ставить условия, которые инвертирует этот переход и таким образом запустить программу по альтернативному пути.
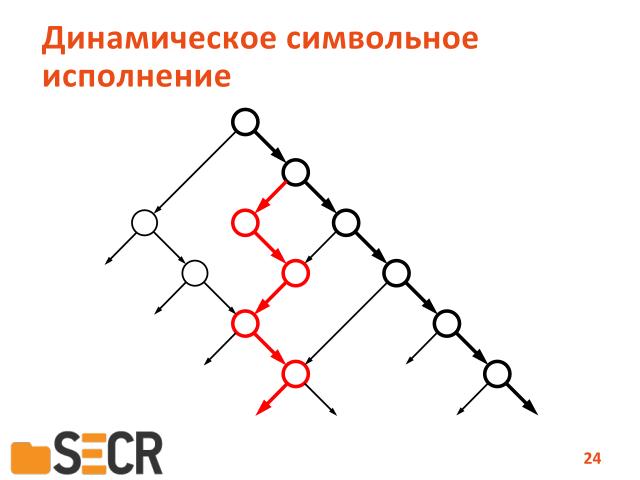
В принципе, в теории, такой способ позволяет обойти все достижимые пути в программе.
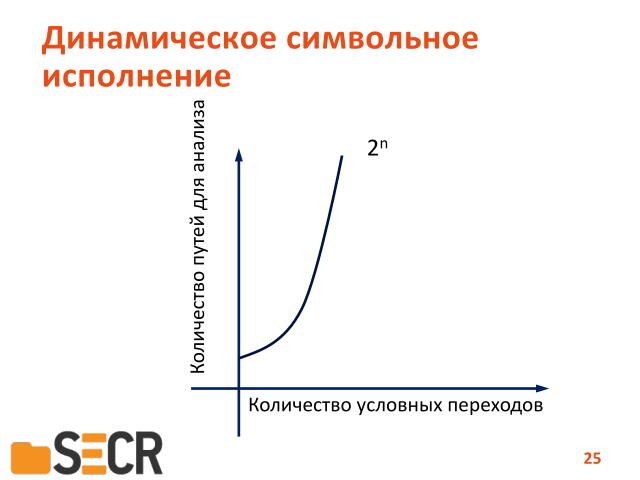
Но если есть цикл, то таких путей будет бесконечное множество и опять-таки мы упираемся в то, что при увеличении количества условных условных переходов, зависящих от внешних данных, количество путей для исследования растет экспоненциально. В этом заключается ограничение данного метода.

Но несмотря на то, что этот имеет ограничения, с 2005 года начинают появляться автоматические инструменты анализа программ, построеные по технике динамического символьного исполнения.

Среди известных инструментов можно отметить такие среды как «KLEE», «S2E», «angr», и вот инструмент, разрабатываемый в нашем институте, «Anxiety».

Применения. Вот есть такая маленькая вырезка из презентации Microsoft Research — в 2007 году была запущена программа Sage, и на большого кластере тестировались компоненты операционной системы Windows 7, всевозможные библиотеки в основном. И после того, того как прошли все этапы классического тестирования и приемки этих библиотек, инструмент Sage, построенный на принципе динамического символьное исполнения, нашел сотни и сотни ошибок.
И насколько мне известно, сейчас эта техника Microsoft применяется до сих пор, то есть несмотря на то что продукт уже ушел в релиз, продолжается фаззинг, из-за этого мы получаем достаточно большое количество обновлений по безопасности. Пример достаточно показательный.

Теперь немножко про статический анализ. Статический анализ это развитие техник инспекции кодом, то есть когда мы анализируем программу, не запуская ее на исполнение никаким образом.
Но в 1951 году Генри Гордон Райс уже доказал теорему, что в общем случае статический анализ невозможен. Т.е. мы не можем статически вычислить какое-то нетривиальное свойство вычислимых функций.
В принципе, «можно расходится и больше ничего не делать»©.

Но в семидесятые годы, при разработке языка Си, Керниган Ричи и описал в своей книге правила, как как правильно пользоваться конструкциями языка — но программисты оказались такими интересными людьми, что эти правила постоянно нарушали, и пришлось господину Джонсону, разрабатывающему в тот момент оптимизирующий компилятор, написать инструмент «lint», который проверял, что эти правила в программе не нарушаются, и выдавал предупреждения, как правильно пользоваться конструкциями языка.
Поэтому многие современные компиляторы уже имеют в себе встроенные алгоритмы статического анализа, которые достаточно хорошо помогают вам повысить качество программ.
А с 2000-х годов, появляются уже специализированные инструменты. Среди них можно отметить и лидеров, таких как «Klocwork inSight» и «Coverity Prevent», ну и также, с 2005 года в нашем институте разрабатывается инструмент статического анализа С/C++/C#/Java — Svace.

Чуть подробнее про статический анализ. Что такое «linter» — проверка простейших условий. Т.е., если кто знает С/С++, то это операция операция сравнения, «двойное равно». Но никто вам не запрещает в условное выражение подставить присваивание и в зависимости от того, какое значение у вас находится в переменной «b», если она не ноль, вы всегда будете ходить по ветке «true», по ветке «истины».
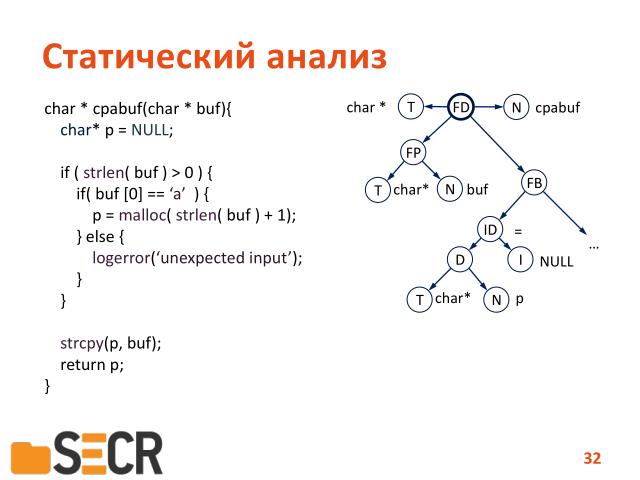
Устроен пример следующим образом. Вот это дерево разбора исходного кода программы маленький кусочек, первые две строчки. Т.е. исходный код представляется виде древовидной структуры, где каждой операции сопоставляется узел, и соответственно, отыскивая на этом дереве специфические паттерны или шаблоны, можно находить различные ошибки. Например, если у нас в операции условного выражения условного перехода будет стоять вместо операции сравнения операция присваивания, то в этом случае мы получим ошибку и достаточно легко можем ее найти. Но к сожалению, по этому дереву нельзя проводить анализ потока данных, потому что такое представление программы к этому не приспособлено.
Зачем нам нужен анализ потока данных.
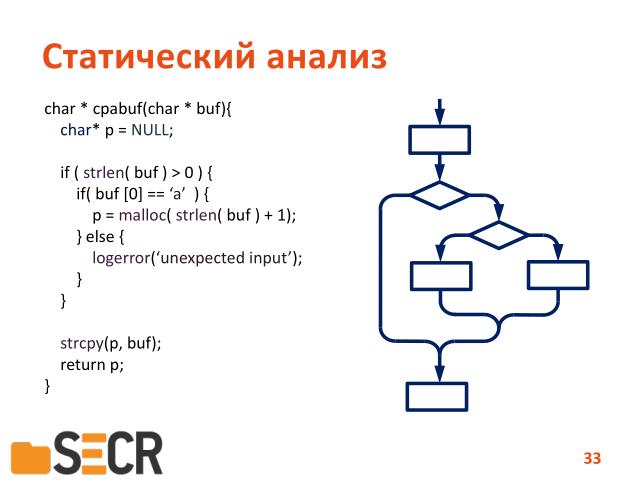
Вот все, кто занимался программированием, когда-то рисовали блок-схемы. Представление программы виде блок-схемы и это и есть так называемый «control flow graph», т.е. граф потока управления программы. И двигаясь по веточкам данного графа можно передавать факты о том, какие значения, каким переменам были присвоены и проверять в различных точках программы эти значения.
Здесь вот если вы внимательно посмотрите, есть путь на котором реализуются ошибка в программе.
Так вот анализ, чувствительный к пути, ее можно найти.
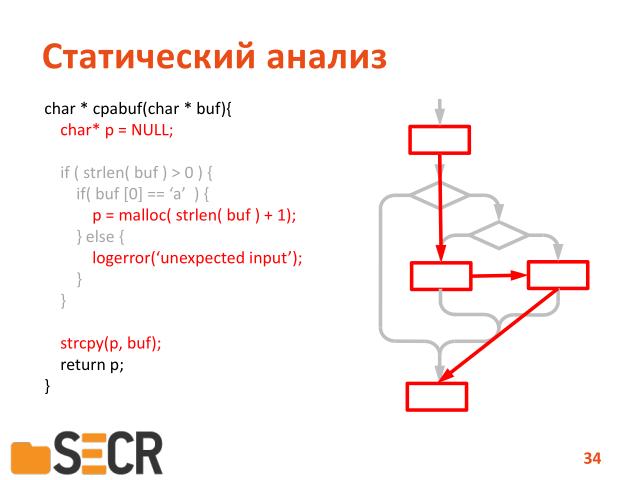
А нечувствительный — нет.
Почему? Потому, что когда у нас анализ нечувствителен к путям исполнения программ, то у нас выстраивается линейная последовательность операций, и у нас на этой последовательности есть выделение памяти и присвоение в переменную «p». И поэтому операция копирования будет считаться вполне себе корректной.
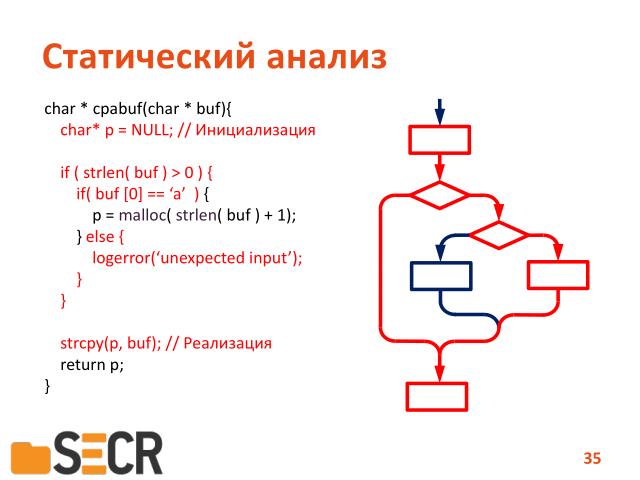
Если же у нас анализ чувствительный к путям, когда мы условия все-таки проверяем на пути, то в этом случае мы можем сказать, что есть путь в программе, где присвоения переменной корректного адреса в памяти не происходит и тогда операция копирования приведет к тому, что мы пытаемся скопировать строку по нулевому адресу, что в принципе запрещено и приведет к системным исключениям.

Следующий уровень анализа — это уровень чувствительности контекста.
Т.е. опять та же самая функция, два вызова. Первый вызов со значением «allow», в принципе корректен, потому что первый символ строки это буква «a» и у нас произойдет выделение памяти.
Но вот вызов с значением «deny», приведет к ошибке. Если статический анализатор умеет подставлять поведение функции в контекст, то он контекстно-зависимый и соответственно такой уровень анализа вам лучше, чем контекстно-независимый.

Какие есть проблемы?
Теорема Райса, она в принципе права — мы не всегда можем корректно вычислить свойство вычислимых функций, определить свойство вычислимых функций.
Поэтому статически анализаторы часто выдает так называемые ложные предупреждение об ошибках, то есть предупреждение об ошибке есть, а ошибки самой нет.
Ну и вторая часть — поскольку разработчики инструментов борются за производительность и масштабируемость этих методов, например, инструмент SVACE может проанализировать исходный код операционной системы Android на 8 миллионов строк за пять-шесть часов. Это достигается как раз именно тем, что в программе некоторые факты о ее поведении не учитываются. Соответственно можем и пропускать ошибки, и выдавать ложные предупреждения. И статические анализаторы борятся за то чтобы уровень ложных предупреждений был как можно ниже.
Считается нормальным уровнем от 60 процентов истинных предупреждений об ошибках.
Это такой «borderline», от которого разработчики уже начинают использовать эти инструменты.
Соответственно преимущество этого метода — это производительность и масштабируемость. Т.е. проанализировать целиком исходный код системы Android за ночь — неплохой результат.
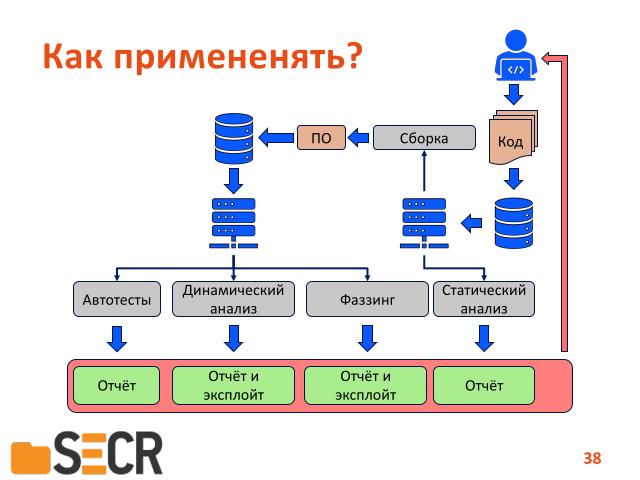
Как же применять все эти инструменты?
Здесь вот сейчас нарисован классический цикл:
- работа с кодом — то есть он кладется в репозитории…
- потом запускается сборка…
- потом запускаются тесты…
вот параллельно со сборкой можно запустить статический анализ, который соберет информацию об исходном коде выдаст вам ошибки виде отчета, а параллельно с автотестами можно запускать динамический анализ и «fuzzing», на каждой новой версии программы.
Таким образом, повышать ее устойчивость.
Что же дальше, где вот сейчас находится передовой край?
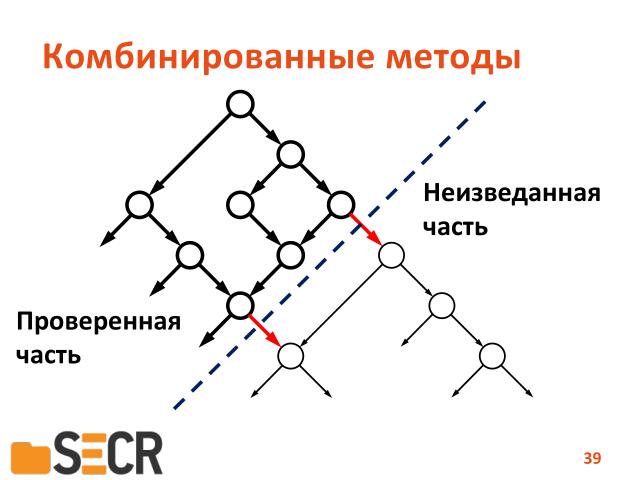
Это комбинированные методы. То есть вот есть программа, в которой фаззер встретил два условных перехода, который не может никак пройти по альтернативной ветке. Но у нас есть набор входных данных и есть инструмент динамического символьного исполнения, мы можем сказать «вот тебе набор данных, вот тебе адрес перехода, который мы хотим инвертировать». В этом случае динамическое символьное исполнение либо скажет, что инвертировать невозможно, при данном наборе данных, при данном пути, либо подберет данные, которые позволят фаззеру пройти неизведанную часть программы. И отталкиваясь от нового набора, дальше фаззить программу.
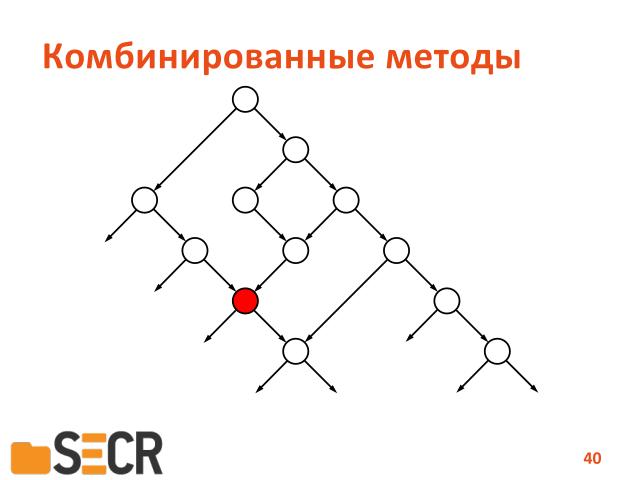
И второй способ, это комбинирование статического анализа и динамического символьного исполнения. Т.е. статический анализ нам указывает точку в программе, которая говорит, что вот здесь потенциальная ошибка.
И нам уже не надо перебирать все пути в этой программе, нам надо просто спуститься в эту точку по различным путям и проверить, реализуется ли ошибка действительно в данной точке или нет.
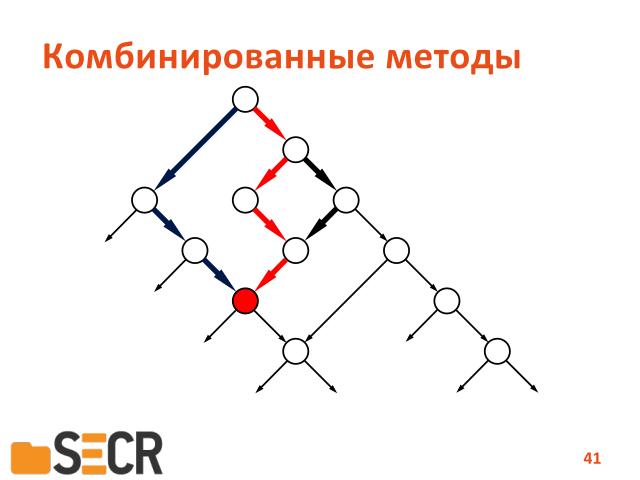
Или условия переходов таковы, что ошибка не реализуется.

Соответственно комбинированные методы вот сейчас разделяются на
- фаззинг с динамическим символьным исполнением, среди них есть один из участников Cyber Security Grand Challenge, Driller, и примерно такой же метод применяется в инструменте Crusher — это совмещение с фазера и динамического символьного исполнения, инструмент, который разрабатывается в нашем институте.
- ну и вот моя тема, моей диссертации который защитил в этом году — это совмещение статического анализа и динамического символьного исполнения.
Удалось доказать, что таким способом можно подтверждать программные ошибки найденные статическим анализом.
На этом в общем все.

Есть некоторый набор материалов от тех инструментах и методах, которые указывались в данной презентации, указывались в данной презентации.

Я готов ответить на ваши вопросы, если они у вас есть.

— Анатолий Кушниренко: А могут ли расставленные программистом «assert»-ы, или какие-то аналогичные высказывания программиста ускорить этот синтаксический анализ или сделать возможным то, что ранее было невозможно?
— В принципе с этого начиналось. То есть применялась инструментация исходного кода, когда программисты расставляли «assert»-ы, потом эти функции проверяли состояние в программе. Но в современном мире не каждый программист захочет портить свой исходный код дополнительными проверками.
Поэтому сейчас достаточно инструментов автоматической инструментации программ, и мы сами вставляем в нужные места программы эти assert-ы. При необходимости.
— Анатолий Кушниренко: А где-то есть есть области, где какими-то
стандартами типа ARINC, корпоративного типа, что-то требуется? Вот работа с такими программами может оказаться более легкой? Или все равно теорема Райса и все, пропали?
— Ну облегчить может. Другой вопрос, что применение таких стандартов усложняет жизнь программиста. Т.е. все таки «Clean Code» — код должен быть чистым, в коде не должно быть ничего лишнего. Т.е. если его можно проанализировать без таких «assert»-ов, то это правильно.
— Анатолий Кушнеренко: Ну если мне лететь на этом самолете с семьей, меня меньше волнует чистота кода…
— Ну не забывайте, что любые «assert»-ы, тем или иным способом замедляют исполнение программ.

— Вы когда говорили про статический анализ, сказали что все стараются уменьшить количество ложных срабатываний, то есть получается на пропуск ошибок в принципе всем наплевать? Это менее важная вещь, чем количество ложных срабатываний?
— Не совсем так. Просто с пропуском ошибок сложнее — то есть ложное предупреждение об ошибке — видно, а вот пропущенную ошибку в коде — не видно. У нас даже был такой случай, когда мы разрабатывали инструмент clockwork, когда из NASA пришел пример кода из-за которого спутник перестал работать, там мы пропустили ошибку, хотя заявляли, что такую ошибку мы находим. Вот когда такие примеры приходят в команду разработки статического анализатора, то соответственно в алгоритме его работы подправляется отправляется что-то и такой тип ошибок начинаем ловить тоже.
— Еще один вопрос она знаете ли вы, пробовали может быть, какие-нибудь механизмы способы построения моделей, вот тех которые любят аналитики рисовать там всякие диаграммки, … последовательностей всякие bpmn и прочие, на основе от статического анализа кода или динамического?
— Знаете был раньше инструмент назывался «clockwork архитектор», который строил различные архитектурные диаграммы по связям в коде, но сейчас насколько мне известно самым таким промышленно применимым является инструмент Structure 101. Потому что мы знаем, что мы в конце работы с компанией Clockwork в 2017 году, мы отгружали данные в специальном формате для этой программы. Ну плюс сейчас вышла новая методика ФСТЕК, по построению вот этих вот матриц связей, в программе и в принципе это возможно сделать на инструменте статического анализа. Просто выражать семантическую информацию которую используют в используют в компиляторе для связывания типов переменных.